
Home >Technology peripherals >AI >QTNet: New temporal fusion solution for point clouds, images and multi-modal detectors (NeurIPS 2023)
QTNet: New temporal fusion solution for point clouds, images and multi-modal detectors (NeurIPS 2023)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-12-15 12:21:311510browse
Written in front & personal understanding
Time series fusion is an effective way to improve the perception ability of autonomous driving 3D target detection, but the current method has cost overhead when applied in actual autonomous driving scenarios. And other issues. The latest research article "Query-based Explicit Motion Timing Fusion for 3D Object Detection" proposed a new timing fusion method in NeurIPS 2023, which takes sparse queries as the object of timing fusion and uses explicit motion information to generate timing Attention matrices to adapt to the characteristics of large-scale point clouds. This method was proposed by researchers from Huazhong University of Science and Technology and Baidu, and is called QTNet: a temporal fusion method for 3D target detection based on query and explicit motion. Experiments have proven that QTNet can bring consistent performance improvements to point clouds, images, and multi-modal detectors at almost no cost overhead

- Paper link :https://openreview.net/pdf?id=gySmwdmVDF
- Code link: https://github.com/AlmoonYsl/QTNet
Problem background
Thanks to the temporal continuity of the real world, information in the time dimension can make the perception information more complete, thereby improving the accuracy and robustness of target detection. For example, timing information can help solve problems in target detection. It solves the occlusion problem, provides the target's motion status and speed information, and provides the target's persistence and consistency information. Therefore, how to efficiently utilize timing information is an important issue in autonomous driving perception. Existing timing fusion methods are mainly divided into two categories. One type is time series fusion based on dense BEV features (applicable to point cloud/image time series fusion), and the other type is time series fusion based on 3D Proposal features (mainly aimed at point cloud time series fusion methods). For temporal fusion based on BEV features, since more than 90% of points on BEV are background, this type of method does not pay more attention to foreground objects, which results in a lot of unnecessary computational overhead and sub-optimal performance. For the time series fusion algorithm based on 3D Proposal, it generates 3D Proposal features through time-consuming 3D RoI Pooling. Especially when there are many targets and a large number of point clouds, the overhead caused by 3D RoI Pooling is actually very high. It is often difficult to accept in applications. In addition, 3D Proposal features heavily rely on Proposal quality, which is often limited in complex scenes. Therefore, it is difficult for current methods to efficiently introduce temporal fusion to enhance the performance of 3D target detection in a very low-overhead manner.
How to achieve efficient timing fusion?
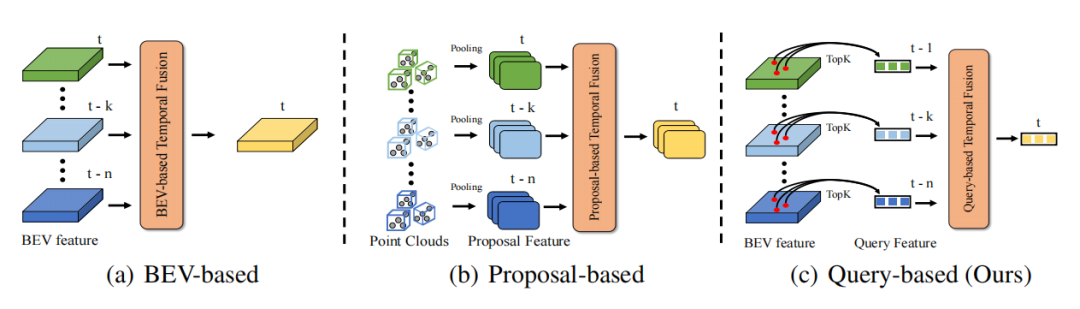
DETR is a very excellent target detection paradigm. Its Query design and Set Prediction ideas effectively realize an elegant detection paradigm without any post-processing. . In DETR, each Query represents an object, and Query is very sparse compared to dense features (generally the number of Query is set to a relatively small fixed number). If Quey is used as the object of timing fusion, the problem of computational overhead will naturally drop to a lower level. Therefore, DETR's Query paradigm is a paradigm naturally suitable for timing fusion. Temporal fusion requires the construction of object associations between multiple frames to achieve the synthesis of temporal context information. So the main problem is how to build a Query-based timing fusion pipeline and establish a correlation between the Query between the two frames.
- Due to the motion of the self-vehicle in actual scenes, the point clouds/images of the two frames are often misaligned in coordinate systems, and in practical applications it is impossible to compare all historical frames in the current frame. Re-forward the network to extract the features of the aligned point cloud/image. Therefore, this article uses Memory Bank to store only the Query features obtained from historical frames and their corresponding detection results to avoid repeated calculations.
- Because point clouds and images are very different in describing target features, it is not feasible to build a unified temporal fusion method through the feature level. However, in three-dimensional space, both point cloud and image modality can depict the correlation between adjacent frames through the geometric position/motion information relationship of the target. Therefore, this paper uses the geometric position of the object and the corresponding motion information to guide the attention matrix of the object between two frames.
Method introduction
The core idea of QTNet is to use Memory Bank to store the Query features obtained in historical frames and their corresponding detection results to avoid duplication Calculate the cost of historical frames. Between two frames of Query, use motion-guided attention matrix for relationship modeling
Overall framework
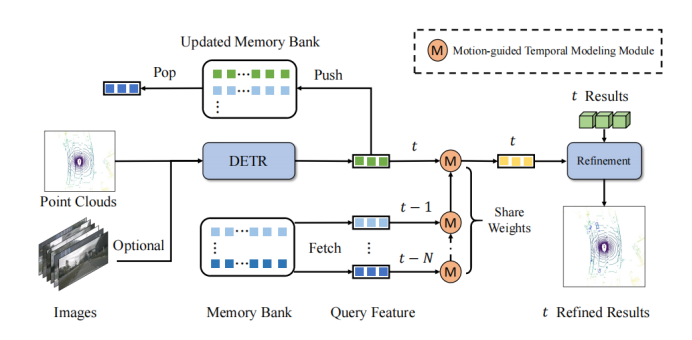
As shown in the framework diagram, QTNet includes a 3D target detector with a 3D DETR structure (LiDAR, Camera and multi-modal are available), a Memory Bank and a Motion-guided Temporal Modeling Module (MTM) for timing fusion. QTNet obtains the Query features and detection results of the corresponding frame through the 3D target detector of the DETR structure, and sends the obtained Query features and detection results to the Memory Bank in a first-in, first-out queue (FIFO) manner. The number of Memory Banks is set to the number of frames required for timing fusion. For timing fusion, QTNet reads data from the Memory Bank starting from the farthest time, and uses the MTM module to iteratively fuse all the features in the Memory Bank from the frame to the frame. Enhance the Query feature of the current frame, and Refine the corresponding detection result of the current frame based on the enhanced Query feature.
Specifically, QTNet fuses the Query features of and frames in frames and , and obtain the enhanced Query feature of the frame. Then, QTNet fuses the Query features of the and frames. In this way, it is continuously integrated to frames through iteration. Note that the MTM used here from the frame to the frame all share parameters.
Motion Guided Attention Module
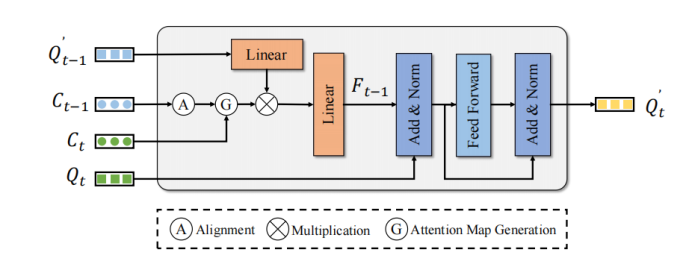
MTM uses the center point position of the object to explicitly generate frames Query and Attention matrix of frame Query. Given the ego pose matrix and , the center point of the object, and the speed. First, MTM uses the ego pose and the speed information of the object prediction to move the object in the previous frame to the next frame and align the coordinate systems of the two frames:
Then pass the frame object center point and The corrected center point of the frame constructs the Euclidean cost matrix . In addition, in order to avoid possible false matching, this article uses the category and distance threshold to construct the attention mask :
Convert the cost matrix The ultimate goal is to form an attention matrix
Apply the attention matrix to the enhanced Query features of the frame to aggregate the temporal features to enhance Query features of the frame:
Finally enhanced Query features of the frame Refine the corresponding detection results through simple FFN to achieve Enhance detection performance.
Decoupled temporal fusion structure
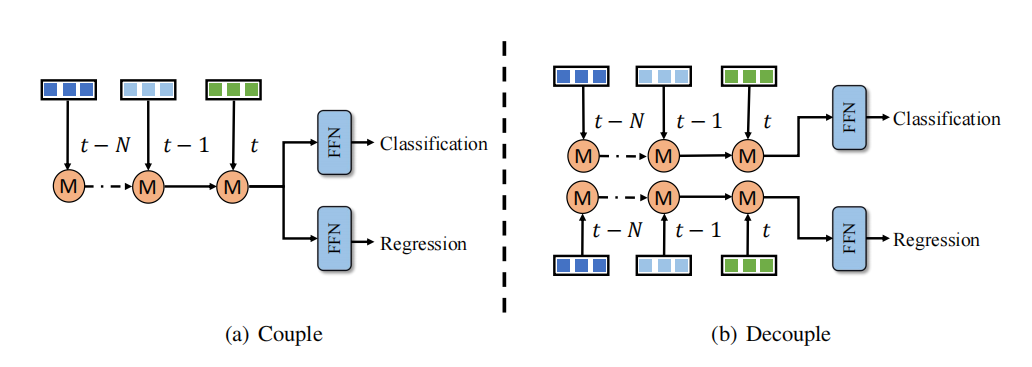
It is observed that there is an imbalance problem in classification and regression learning of temporal fusion, a solution Time series fusion branches are designed for classification and regression respectively. However, this decoupling approach adds more computational cost and latency, which is unacceptable for most methods. In contrast, QTNet utilizes an efficient timing fusion design, its computational cost and delay are negligible, and it performs better than the entire 3D detection network. Therefore, this article adopts the decoupling method of classification and regression branches in time series fusion to achieve better detection performance at negligible cost, as shown in the figure
Experimental Effect
QTNet achieves consistent point increase on point clouds/images/multi-modalities
After verification on the nuScenes data set, it was found that QTNet does not use the future When information, TTA and model are integrated, an mAP of 68.4 and an NDS of 72.2 are achieved, achieving SOTA performance. Compared with MGTANet that uses future information, QTNet performs better than MGTANet in the case of 3-frame timing fusion, increasing mAP by 3.0 and NDS by 1.0 respectively
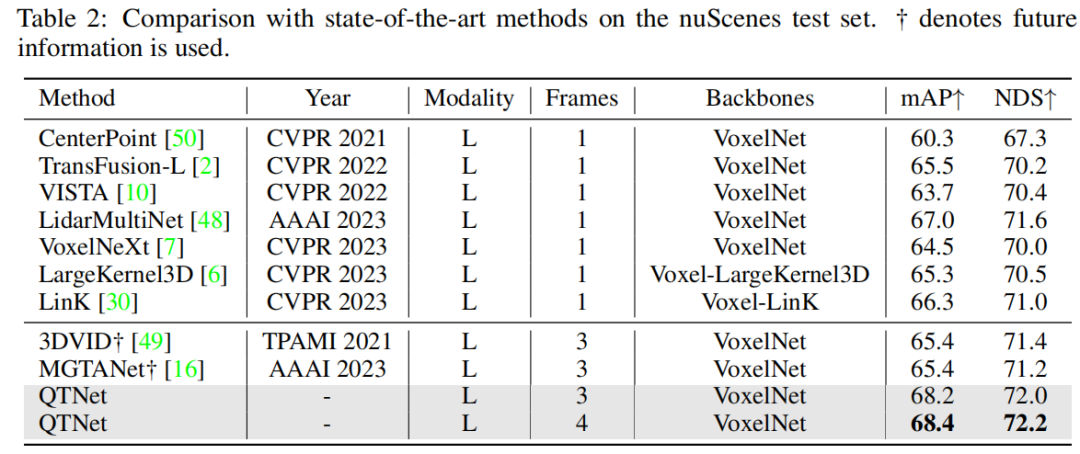
In addition, this article has also been verified on multi-modal and ring view-based methods. The experimental results on the nuScenes validation set prove the effectiveness of QTNet on different modalities.
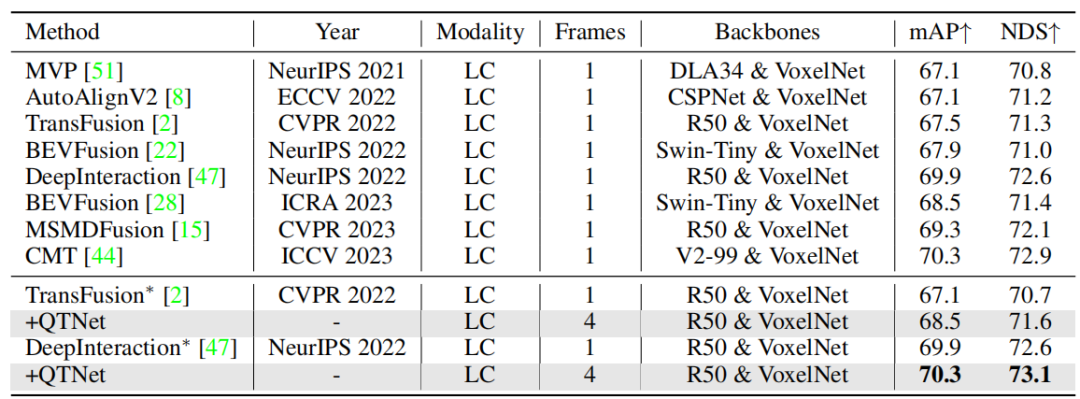

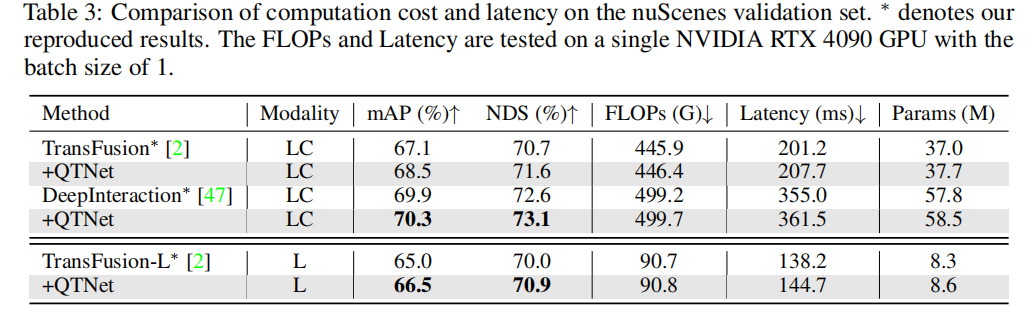
For practical applications, the cost overhead of timing fusion is very important. This article conducts analysis and experiments on QTNet in three aspects: calculation amount, delay and parameter amount. The results show that compared with the entire network, QTNet's computational overhead, time delay and parameter amount caused by different baselines are negligible, especially the calculation amount only uses 0.1G FLOPs (LiDAR baseline)
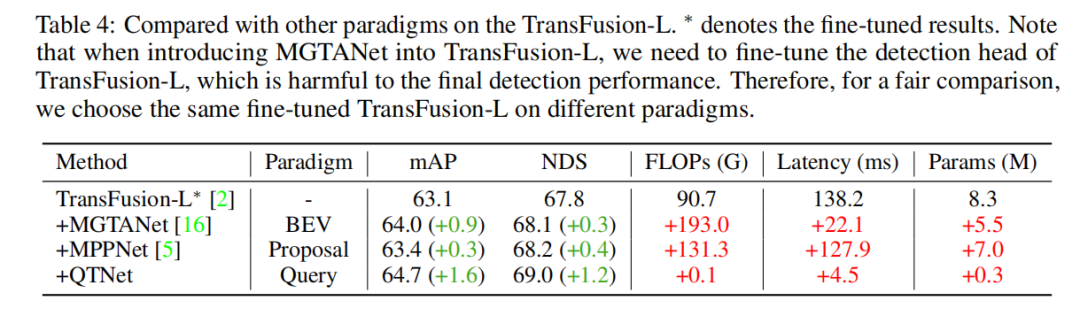
Comparison of different timing fusion paradigms
In order to verify the superiority of the Query-based timing fusion paradigm, we selected different representative frontier timings Fusion methods are compared. Through experimental results, it is found that the timing fusion algorithm based on Query paradigm is more efficient than those based on BEV and Proposal paradigm. Using only 0.1G FLOPs and 4.5ms overhead, QTNet shows better performance, while the overall parameter amount is only 0.3M
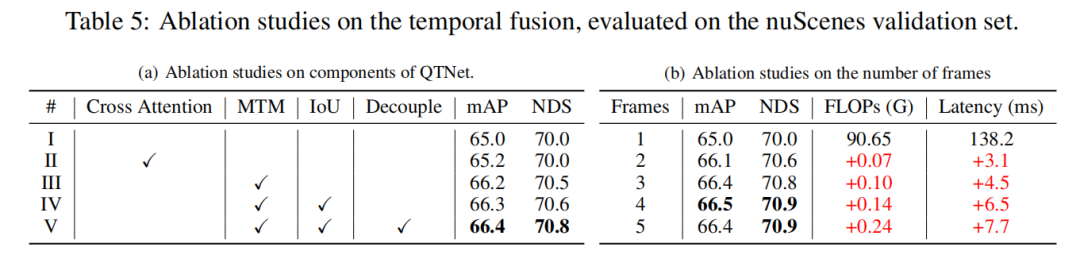
Ablation Experiment
This study conducted an ablation experiment based on LiDAR baseline on the nuScenes verification set, through 3-frame temporal fusion. Experimental results show that simply using Cross Attention to model temporal relationships has no obvious effect. However, when using MTM, the detection performance is significantly improved, which illustrates the importance of explicit motion guidance in large-scale point clouds. In addition, through ablation experiments, it was also found that the overall design of QTNet is very lightweight and efficient. When using 4 frames of data for timing fusion, the calculation amount of QTNet is only 0.24G FLOPs, and the delay is only 6.5 milliseconds
##Visualization of MTM
In order to explore why MTM is better than Cross Attention, this article visualizes the attention matrix of objects between two frames, where the same ID represents the same object between two frames. It can be found that the attention matrix (b) generated by MTM is more discriminative than the attention matrix (a) generated by Cross Attention, especially the attention matrix between small objects. This shows that the attention matrix guided by explicit motion makes it easier for the model to establish the association of objects between two frames through physical modeling. This article only briefly explores the issue of physically establishing timing correlations in timing fusion. It is still worth exploring how to better build timing correlations.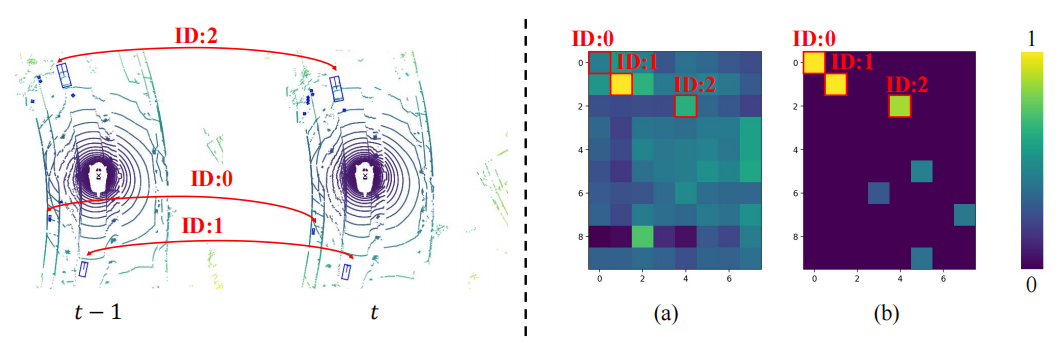
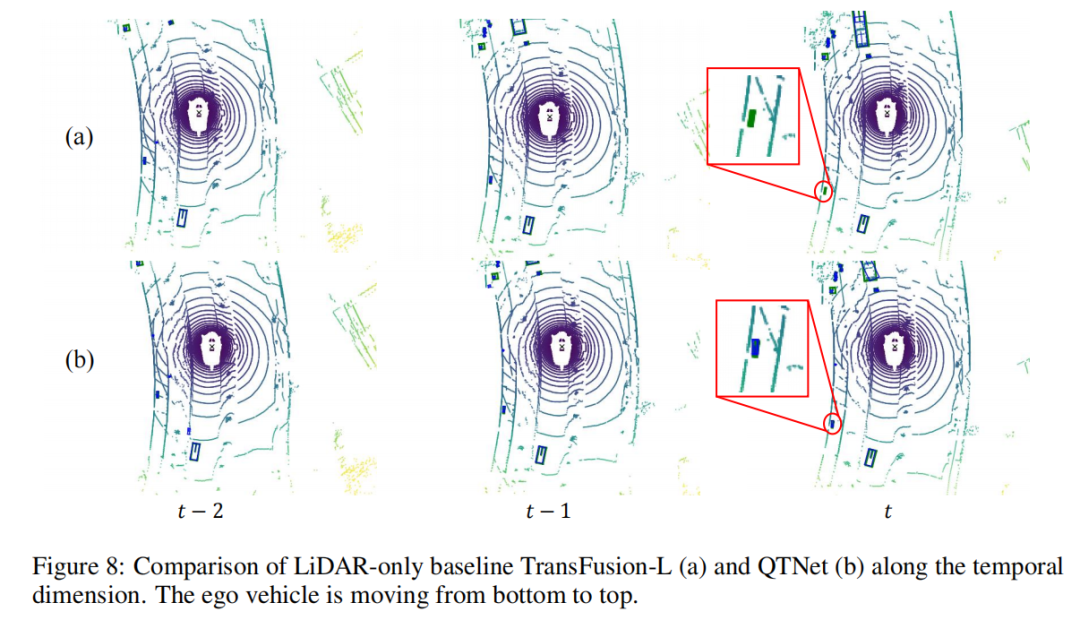
Visualization of detection results
This article uses scene sequences as the object to conduct visual analysis of detection results. It can be found that the small object in the lower left corner quickly moves away from the vehicle starting from frame, which causes the baseline to miss the object in frame . However, QTNet can still detect it in frame The object was detected, which proves the effectiveness of QTNet in temporal fusion.
Summary of this article
This article proposes a more efficient Query-based temporal fusion method QTNet for the current 3D target detection task. Its main core has two points: one is to use sparse Query as the object of temporal fusion and store historical information through Memory Bank to avoid repeated calculations; the other is to use explicit motion modeling to guide the generation of the attention matrix between temporal queries , to achieve temporal relationship modeling. Through these two key ideas, QTNet can efficiently implement timing fusion that can be applied to LiDAR, Camera, and multi-modality, and consistently enhance the performance of 3D target detection with negligible cost overhead.
The above is the detailed content of QTNet: New temporal fusion solution for point clouds, images and multi-modal detectors (NeurIPS 2023). For more information, please follow other related articles on the PHP Chinese website!