
Home >Technology peripherals >AI >Unlock GPT-4 and Claude2.1: In one sentence, you can realize the real power of 100k+ context large models, increasing the score from 27 to 98
Unlock GPT-4 and Claude2.1: In one sentence, you can realize the real power of 100k+ context large models, increasing the score from 27 to 98

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-12-15 11:37:37859browse
All major model companies have rolled up the context window. The standard configuration of Llama-1 was still 2k, but now those with less than 100k are embarrassed to go out.
However, an extreme test by Goose found that most people use it incorrectly and fail to exert the AI's due strength.
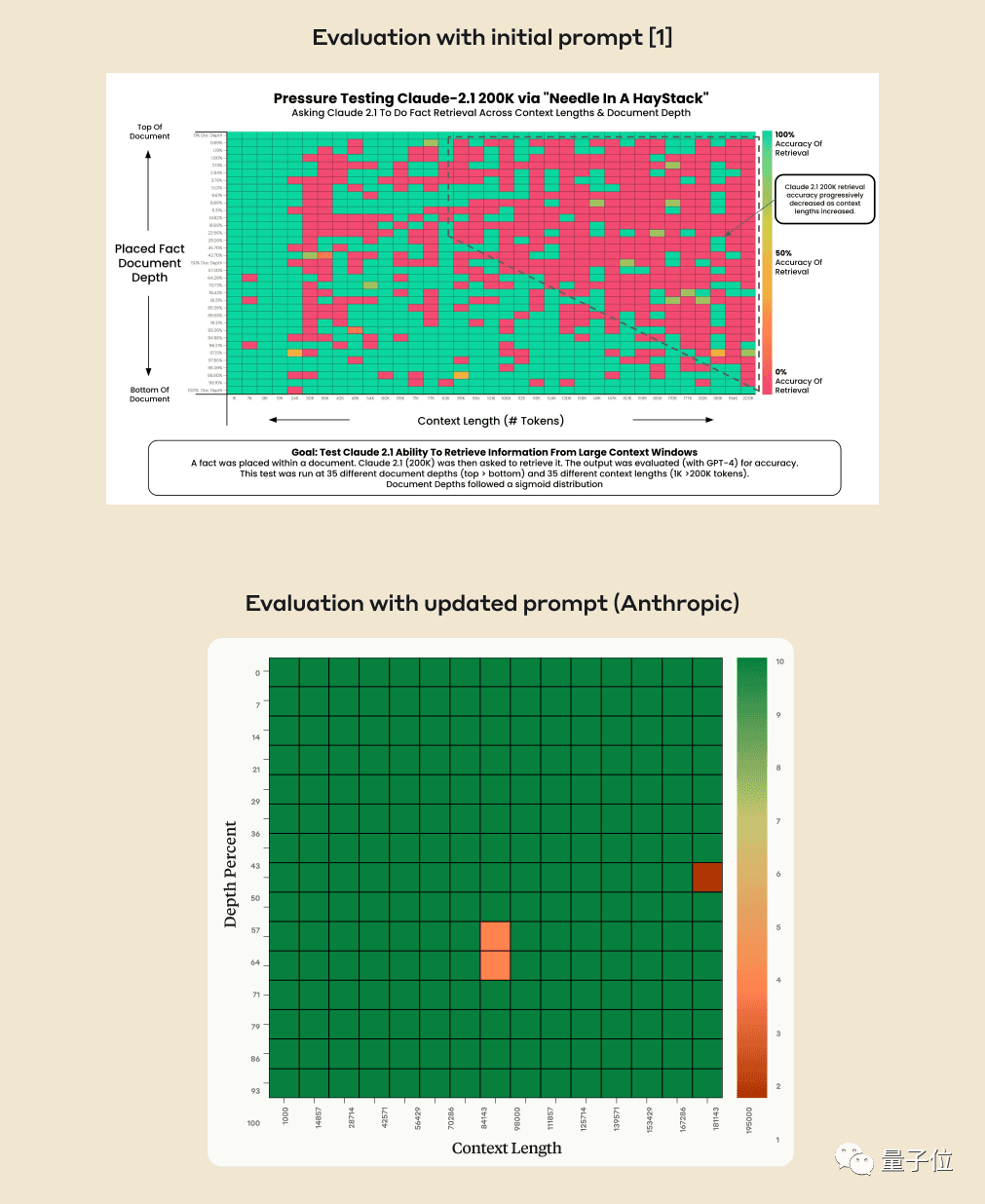
#Can AI really accurately find key facts from hundreds of thousands of words? The redder the color, the more mistakes the AI makes.
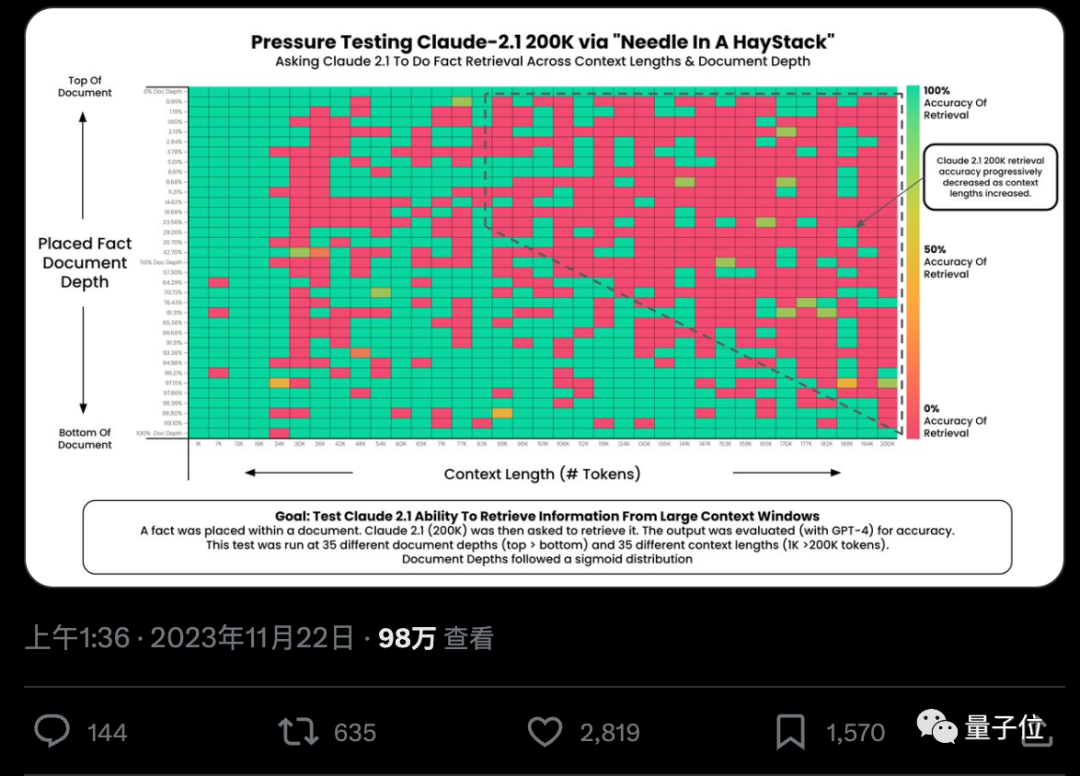
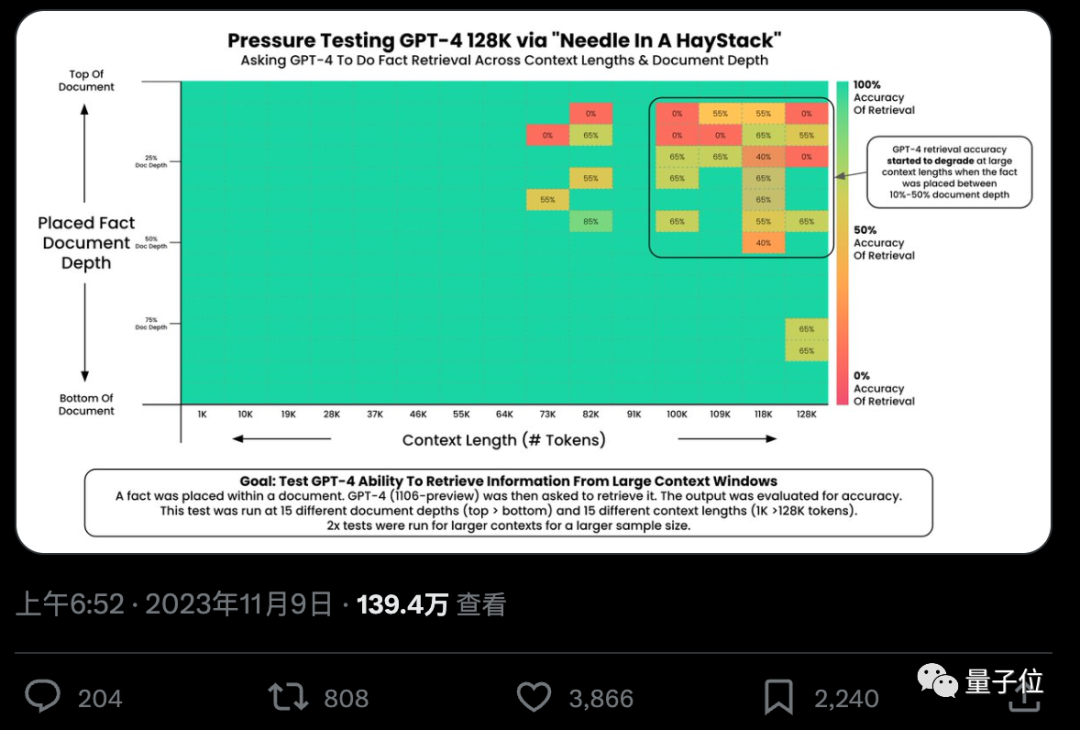
By default, GPT-4-128k and the latest released Claude2.1-200k results are both Not ideal.
But after Claude’s team understood the situation, they came up with a super simple solution, adding one sentence to directly improve the score from 27% to 98%.
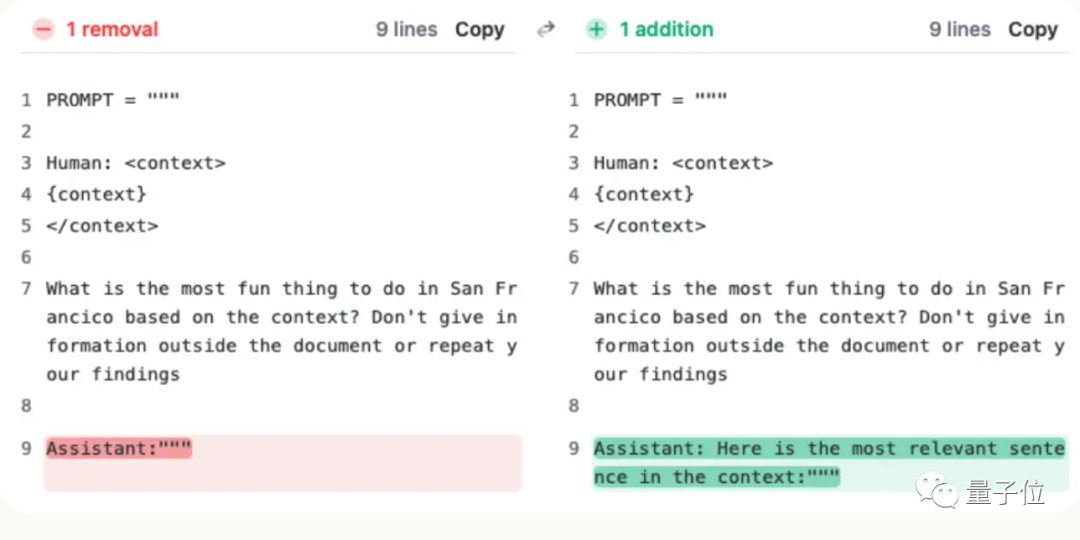
It’s just that this sentence is not added to the user’s question. Instead, the AI said at the beginning of the reply:
“Here is the most relevant sentence in the context:”
(This is the most relevant sentence in the context:)
Let the big Model Needle in a Haystack
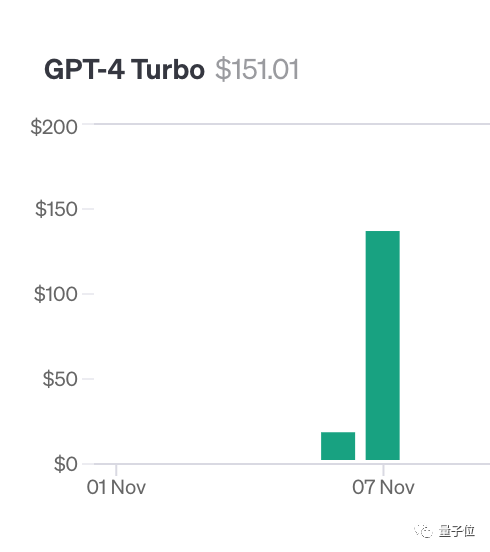
To do this test, author Greg Kamradt spent at least $150 of his own money.
When testing Claude2.1, Anthropic provided him with a free credit limit. Fortunately, he did not have to spend an additional $1,016.
In fact, the test method It’s not complicated either. They all use 218 blog posts by YC founder Paul Graham as test data.
Add specific statements in different places in the document: The best thing about San Francisco is sitting in Dolores Park on a sunny day and enjoying a sandwich
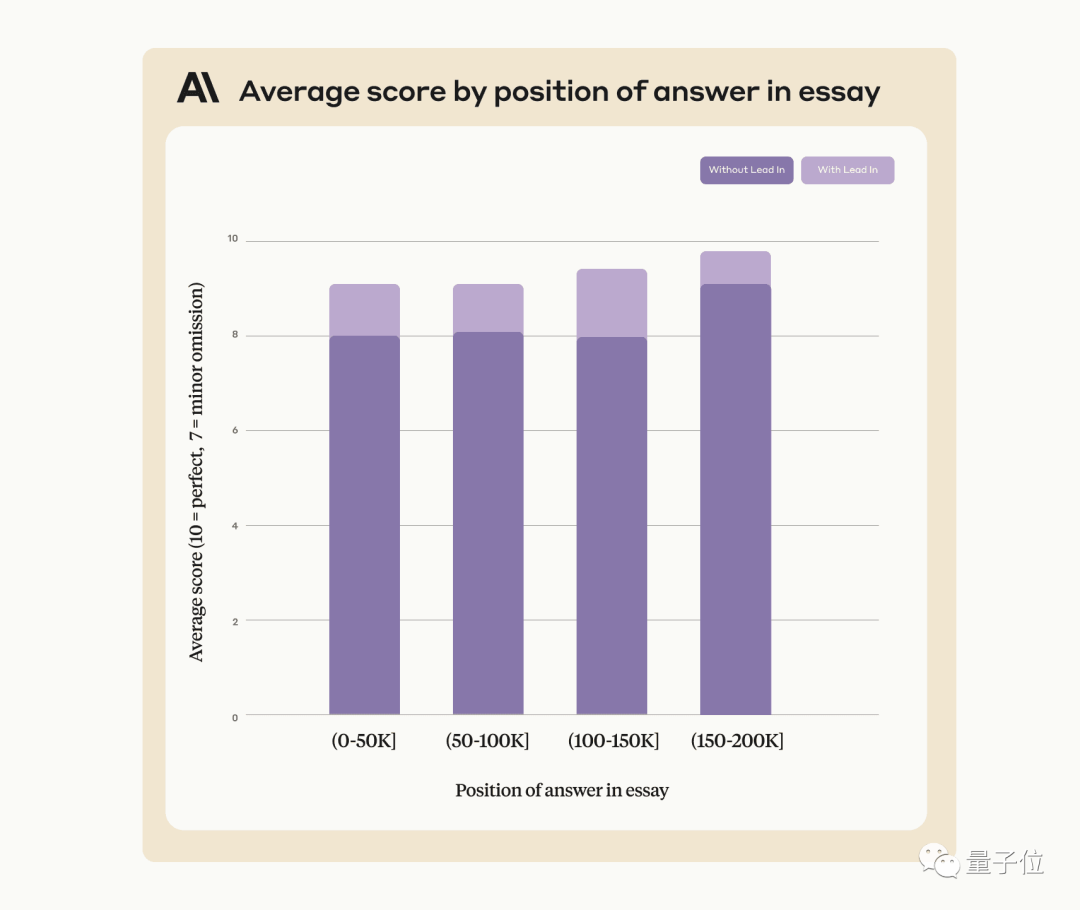
Please use all Provided context to answer the question, repeatedly tested GPT-4 and Claude2.1 in documents with different context lengths and added at different locations

Anthropicafter careful analysis However, it was found that the AI was just unwilling to answer questions based on a single sentence in the document, especially when the sentence was inserted later and had little to do with the entire article.
In other words, if the AI judges that this sentence has nothing to do with the topic of the article, it will take the method of not searching for each sentence
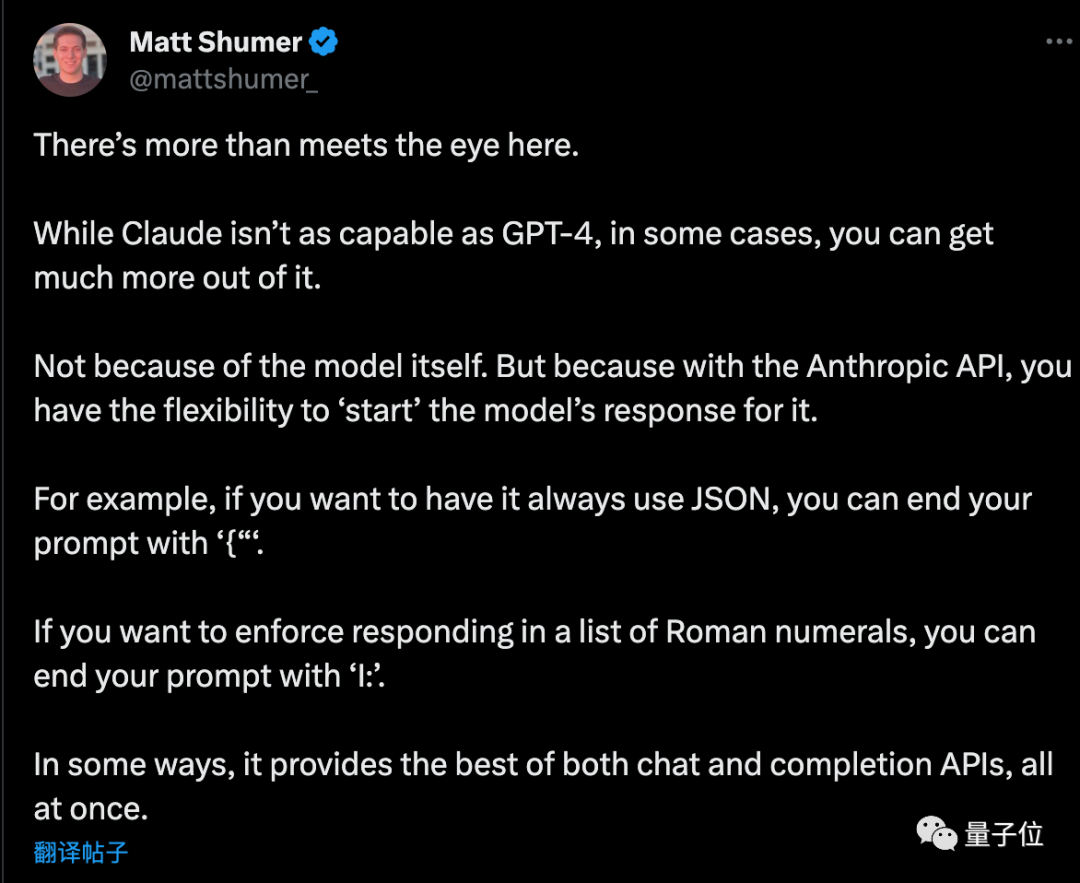
If you want AI to output pure JSON format, the prompt word ends with "{". In the same way, if you want the AI to list Roman numerals, the prompt word can end with "I:".
But things are not over yet...
Large domestic companies have also begun to take notice of this test , and began to try to see if their own large model could pass the
#Dark Side of the Moon Kimi large model# team also tested the problem, But different solutions were given and good results were achieved.

Without changing the original meaning, the content that needs to be rewritten is: The advantage of doing this is that modifying the user's question prompt is more accurate than asking the AI to add a sentence in the answer. Easy to implement, especially when using the chatbot product directly without calling the API
I used a new method to help test GPT-4 and the far side of the moon with Claude2.1, and the results showed GPT-4 Significant improvements have been achieved, while Claude2.1 only has slight improvements
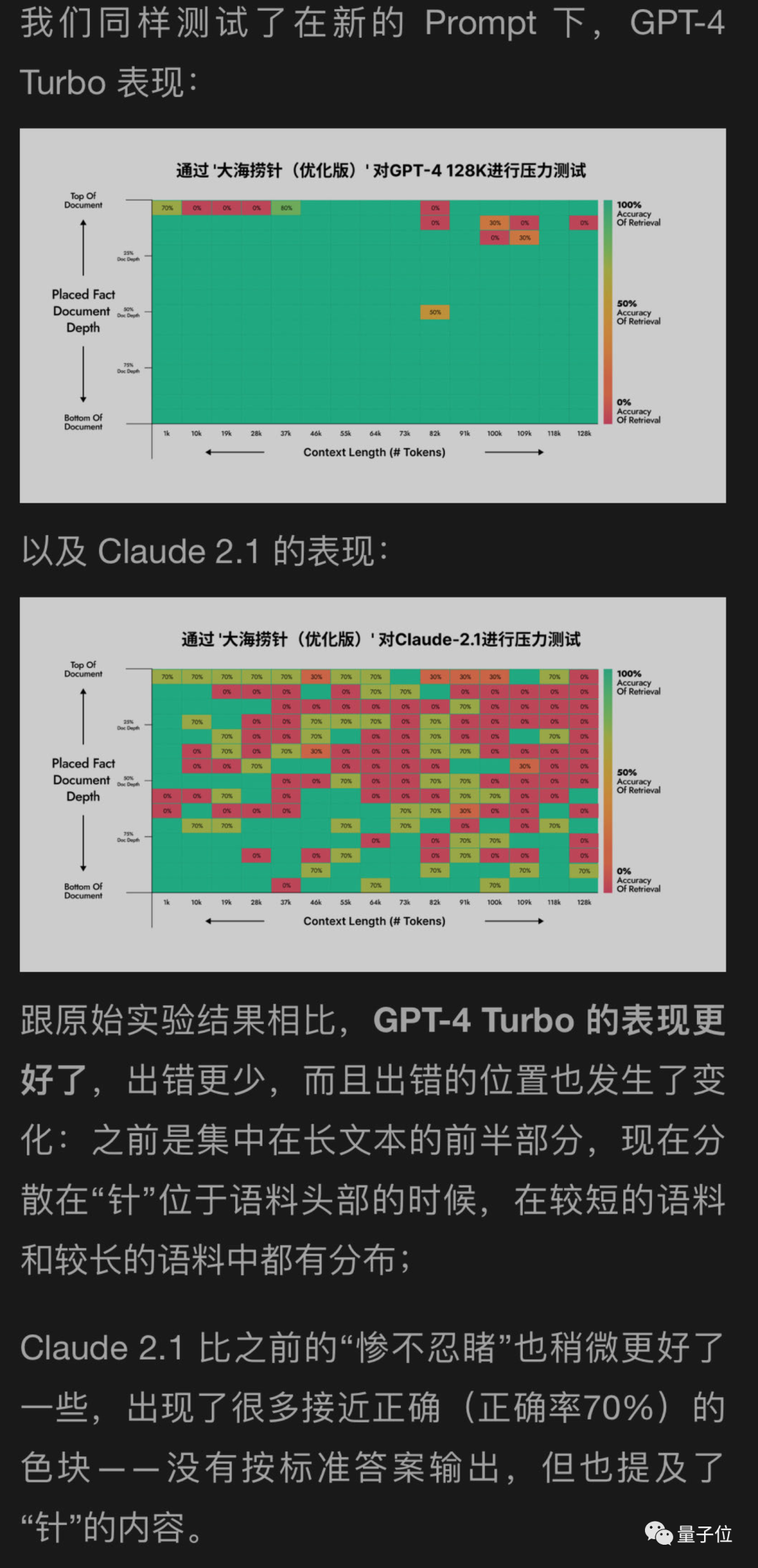
It seems that this experiment itself has certain limitations, and Claude also has its own particularities , may be related to their own alignment method Constituional AI, and it is better to use the method provided by Anthropic itself.
Later, engineers on the far side of the moon continued to conduct more rounds of experiments, one of which turned out to be...

Oops, I became test data
The above is the detailed content of Unlock GPT-4 and Claude2.1: In one sentence, you can realize the real power of 100k+ context large models, increasing the score from 27 to 98. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to compare the similarities and differences between two columns of data in excel
- How to compare duplicate data between two worksheets
- What are the eight basic data types?
- Musk announces he will sue Microsoft for using Twitter data to train artificial intelligence system
- The first government review of ChatGPT may come from the US Federal Trade Commission, OpenAI: not yet trained GPT5