

 Technology peripheralsAINew title: Real-time rendering evolved! Innovative method of 3D reconstruction based on rays
Technology peripheralsAINew title: Real-time rendering evolved! Innovative method of 3D reconstruction based on rays
 Pictures
Pictures
Paper link:https://arxiv.org/pdf/2310.19629
Code link:https://github.com/vLAR-group/RayDF
Homepage: The content that needs to be rewritten is: https://vlar-group.github.io/RayDF.html
Rewritten content: Implementation method:

The overall process and components of RayDF are as follows (see Figure 1)
1. Introduction
In the machine Learning accurate and efficient 3D shape representation is very important in many cutting-edge applications in the fields of vision and robotics. However, existing implicit expressions based on 3D coordinates require expensive computational costs when representing 3D shapes or rendering 2D images; in contrast, ray-based methods can efficiently infer 3D shapes. However, existing ray-based methods do not take into account the geometric consistency under multiple viewing angles, making it difficult to recover accurate geometric shapes under unknown viewing angles.
To address these problems, this paper proposes a new maintenance method. RayDF, a ray-based implicit expression method for multi-view geometric consistency. This method is based on a simple ray-surface distance field, by introducing a new dual-ray visibility classifier and a multi-view consistency optimization module. optimization module), learn to obtain a ray-surface distance that satisfies the geometric consistency of multiple viewing angles. Experimental results show that the modified method achieves superior 3D surface reconstruction performance on three data sets and achieves a rendering speed 1000 times faster than the coordinate-based method (see Table 1).

The following are the main contributions:
- Using ray-surface distance field to represent three-dimensional shape, this expression is better than Existing coordinate-based representations are more efficient.


(1) First construct the ray pairs for training for the auxiliary network dual-ray visibility classifier. For a ray in a picture (corresponding to a pixel in the picture), the corresponding space surface point can be known through its ray-surface distance. Project it to the remaining viewing angles in the training set to obtain another ray; and this ray There is a corresponding ray-surface distance. The article sets a threshold of 10 mm to determine whether two rays are visible to each other.
(2) The second stage is to train the main network ray-surface distance network to make its predicted distance field meet multi-view consistency. As shown in Figure 4, for a main ray and its surface points, the surface point is uniformly sampled with the center of the sphere to obtain several multi-view rays. Pair the main ray with these multi-view rays one by one, and their mutual visibility can be obtained through the trained dual-ray visibility classifier. Then predict the ray-surface distance of these rays through the ray-surface distance network; if the main ray and a certain sampling ray are mutually visible, then the surface points calculated by the ray-surface distances of the two rays should be the same point; according to The corresponding loss function is designed and the main network is trained, which ultimately enables the ray-surface distance field to meet multi-view consistency.

2.4 Surface Normal Derivation and Outlier Points Removal
Since the depth value at the edge of the scene surface often has mutations (discontinuity), and neural The network is a continuous function. The above-mentioned ray-surface distance field can easily predict inaccurate distance values at the edge of the surface, resulting in noise on the geometric surface at the edge. Fortunately, the designed ray-surface distance field has a good feature, as shown in Figure 5. The normal vector of each estimated three-dimensional surface point can be easily found in closed form through automatic differentiation of the network. Therefore, the normal vector Euclidean distance of the surface point can be calculated during the network inference stage. If the distance value is greater than the threshold, the surface point is regarded as an outlier and eliminated, thereby obtaining a clean three-dimensional reconstructed surface.

Figure 5 Surface normal calculation
3. Experiments
In order to verify the effectiveness of the proposed method, we performed experiments on three data sets Experiments were conducted on. The three data sets are the object-level synthetic data set Blender [1], the scene-level synthetic data set DM-SR [2], and the scene-level real data set ScanNet [3]. We selected seven baselines for performance comparison. Among them, OF [4]/DeepSDF [5]/NDF [6]/NeuS [7] are coordinate-based level-set methods, DS-NeRF [8] is a depth-supervised NeRF-based method, and LFN [9] and PRIF [10] are two ray-based baselines
Due to the ease of the RayDF method to directly add a radiance branch to learn textures, it can be compared with baseline models that support predicting radiance fields. Therefore, the comparative experiments of this paper are divided into two groups. The first group (Group 1) only predicts distance (geometry), and the second group (Group 2) predicts both distance and radiance (geometry and texture)
3.1 Evaluation on Blender Dataset
As can be seen from Table 2 and Figure 6, in Group 1 and 2, RayDF achieved better results in surface reconstruction, especially in the most important ADE indicator. Better than coordinate- and ray-based baselines. At the same time, in terms of radiance field rendering, RayDF also achieved performance comparable to DS-NeRF and better than LFN and PRIF.


Figure 6 Visual comparison of Blender data set
3.2 Evaluation on DM-SR Dataset
As can be seen from Table 3, RayDF surpasses all baselines in the most critical ADE indicator. At the same time, in the Group 2 experiment, RayDF was able to obtain high-quality new view synthesis while ensuring that the accurate surface shape was restored (see Figure 7).


Figure 7 Visual comparison of DM-SR data set
3.3 Evaluation on ScanNet Dataset
Table 4 compares the performance of RayDF and baselines in challenging real-world scenarios. In the first and second groups, RayDF significantly outperforms baselines in almost all evaluation metrics, showing clear advantages in recovering complex real-world 3D scenes


The following is a rewrite of the visual comparison of Figure 8 ScanNet dataset: In Figure 8, we show the visual comparison results of the ScanNet dataset
3.4 Ablation Study
We conducted an ablation experiment on the Blender dataset. Table 5 in the paper shows the key The ablation experimental results of the dual-ray visibility classifier
- are shown in Table 5 (1). Without the help of the dual-ray visibility classifier, the ray-surface distance field will not be able to detect the new angle of view. The rays predict reasonable distance values (see Figure 9).
- In the input of the classifier, the input surface point coordinates are selected as auxiliary, as shown in Table 5 (2) and (3), if the surface point distance value is selected as auxiliary or not Providing auxiliary information, the classifier will obtain lower accuracy and F1 score, resulting in insufficient visibility information provided for the ray-surface distance network, thereby predicting incorrect distance values.
- As shown in Table 5 (4), by inputting a pair of rays in an asymmetric manner, the trained classifier has a higher accuracy but a lower F1 score. This shows that this classifier is significantly less robust than a classifier trained with symmetric input rays.
Other resection operations can be viewed in the paper and the paper appendix


need to be re- The written content is: Figure 9 shows the visual comparison of using a classifier and not using a classifier
4. Conclusion
When using the ray-based multi-view consistency framework for research, the paper A conclusion is drawn that three-dimensional shape representations can be learned efficiently and accurately through this method. In the paper, a simple ray-surface distance field is used to represent the geometry of three-dimensional shapes, and a novel dual-ray visibility classifier is used to further achieve multi-view geometric consistency. Experiments on multiple data sets have proven that the RayDF method has extremely high rendering efficiency and excellent performance. Further extensions to the RayDF framework are welcome. You can view more visualization results on the homepage
The content that needs to be rewritten is: https://vlar-group.github.io/RayDF.html

The content that needs to be rewritten is: Original link: https://mp.weixin.qq.com/s/dsrSHKT4NfgdDPYcKOhcOA
The above is the detailed content of New title: Real-time rendering evolved! Innovative method of 3D reconstruction based on rays. For more information, please follow other related articles on the PHP Chinese website!

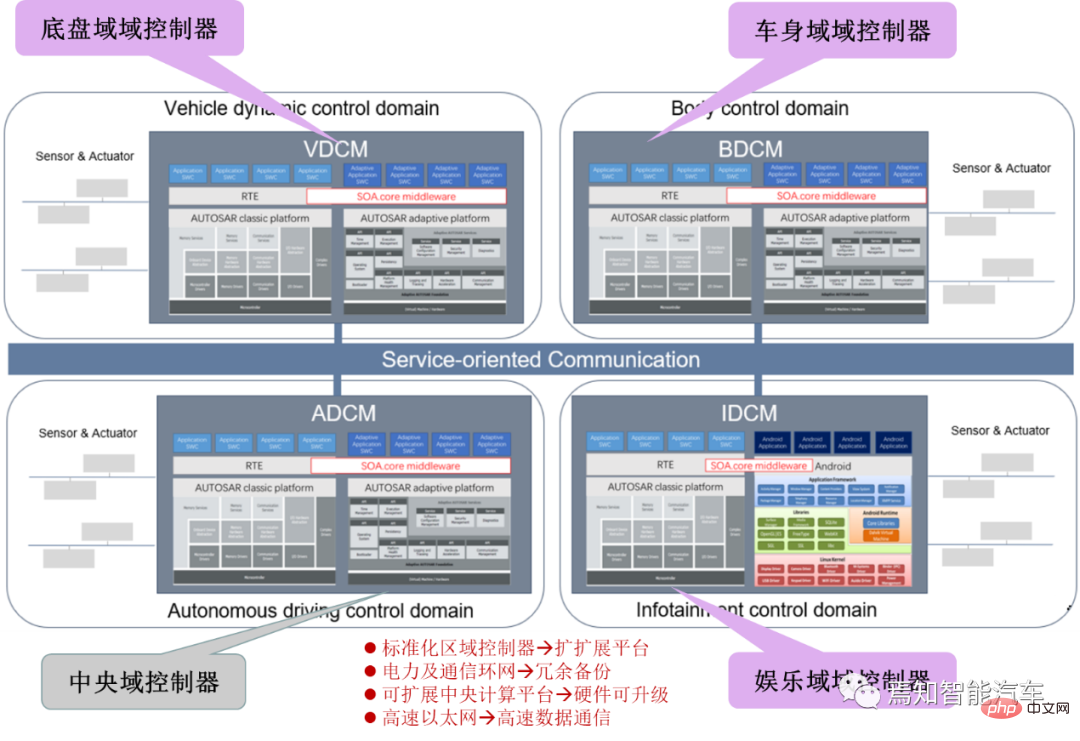 SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
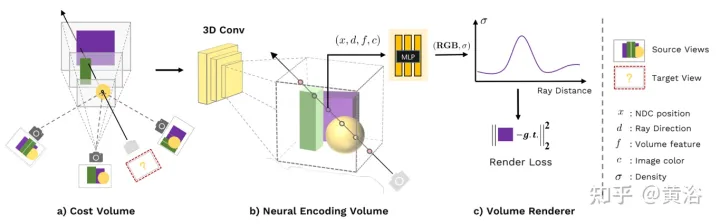 新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM
新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM新视角图像生成(NVS)是计算机视觉的一个应用领域,在1998年SuperBowl的比赛,CMU的RI曾展示过给定多摄像头立体视觉(MVS)的NVS,当时这个技术曾转让给美国一家体育电视台,但最终没有商业化;英国BBC广播公司为此做过研发投入,但是没有真正产品化。在基于图像渲染(IBR)领域,NVS应用有一个分支,即基于深度图像的渲染(DBIR)。另外,在2010年曾很火的3D TV,也是需要从单目视频中得到双目立体,但是由于技术的不成熟,最终没有流行起来。当时基于机器学习的方法已经开始研究,比
 多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM
多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM我们经常可以看到蜜蜂、蚂蚁等各种动物忙碌地筑巢。经过自然选择,它们的工作效率高到叹为观止这些动物的分工合作能力已经「传给」了无人机,来自英国帝国理工学院的一项研究向我们展示了未来的方向,就像这样:无人机 3D 打灰:本周三,这一研究成果登上了《自然》封面。论文地址:https://www.nature.com/articles/s41586-022-04988-4为了展示无人机的能力,研究人员使用泡沫和一种特殊的轻质水泥材料,建造了高度从 0.18 米到 2.05 米不等的结构。与预想的原始蓝图
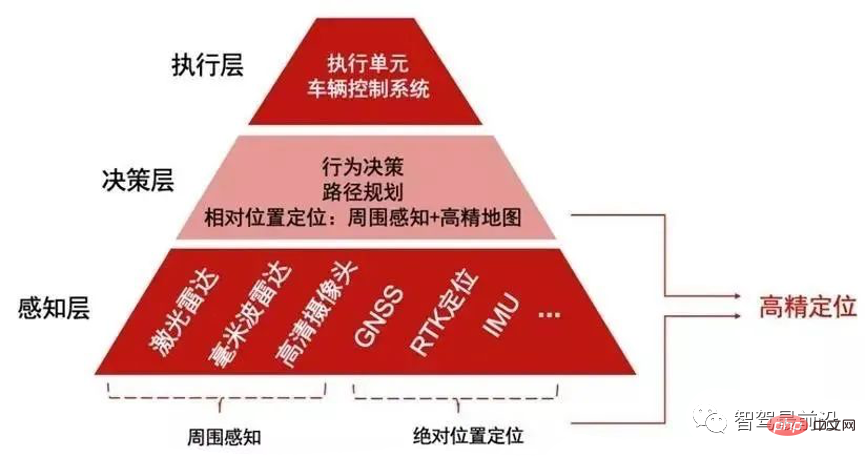 如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM
如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM与人类行走一样,自动驾驶汽车想要完成出行过程也需要有独立思考,可以对交通环境进行判断、决策的能力。随着高级辅助驾驶系统技术的提升,驾驶员驾驶汽车的安全性不断提高,驾驶员参与驾驶决策的程度也逐渐降低,自动驾驶离我们越来越近。自动驾驶汽车又称为无人驾驶车,其本质就是高智能机器人,可以仅需要驾驶员辅助或完全不需要驾驶员操作即可完成出行行为的高智能机器人。自动驾驶主要通过感知层、决策层及执行层来实现,作为自动化载具,自动驾驶汽车可以通过加装的雷达(毫米波雷达、激光雷达)、车载摄像头、全球导航卫星系统(G
 超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM
超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM实时全局光照(Real-time GI)一直是计算机图形学的圣杯。多年来,业界也提出多种方法来解决这个问题。常用的方法包通过利用某些假设来约束问题域,比如静态几何,粗糙的场景表示或者追踪粗糙探针,以及在两者之间插值照明。在虚幻引擎中,全局光照和反射系统Lumen这一技术便是由Krzysztof Narkowicz和Daniel Wright一起创立的。目标是构建一个与前人不同的方案,能够实现统一照明,以及类似烘烤一样的照明质量。近期,在SIGGRAPH 2022上,Krzysztof Narko
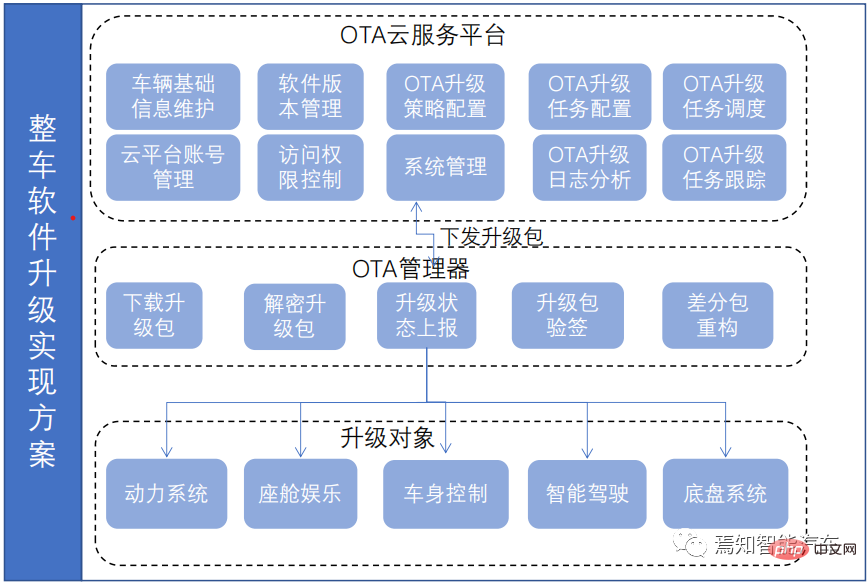 一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM
一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM由于智能汽车集中化趋势,导致在网络连接上已经由传统的低带宽Can网络升级转换到高带宽以太网网络为主的升级过程。为了提升车辆升级能力,基于为车主提供持续且优质的体验和服务,需要在现有系统基础(由原始只对车机上传统的 ECU 进行升级,转换到实现以太网增量升级的过程)之上开发一套可兼容现有 OTA 系统的全新 OTA 服务系统,实现对整车软件、固件、服务的 OTA 升级能力,从而最终提升用户的使用体验和服务体验。软件升级触及的两大领域-FOTA/SOTA整车软件升级是通过OTA技术,是对车载娱乐、导
 internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PM
internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PMinternet的基本结构与技术起源于ARPANET。ARPANET是计算机网络技术发展中的一个里程碑,它的研究成果对促进网络技术的发展起到了重要的作用,并未internet的形成奠定了基础。arpanet(阿帕网)为美国国防部高级研究计划署开发的世界上第一个运营的封包交换网络,它是全球互联网的始祖。
 综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PM
综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PMarXiv综述论文“Collaborative Perception for Autonomous Driving: Current Status and Future Trend“,2022年8月23日,上海交大。感知是自主驾驶系统的关键模块之一,然而单车的有限能力造成感知性能提高的瓶颈。为了突破单个感知的限制,提出协同感知,使车辆能够共享信息,感知视线之外和视野以外的环境。本文回顾了很有前途的协同感知技术相关工作,包括基本概念、协同模式以及关键要素和应用。最后,讨论该研究领域的开放挑战和问题


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Atom editor mac version download
The most popular open source editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

