

 Technology peripheralsAIBreaking through the resolution limit: Byte and the University of Science and Technology of China reveal a large multi-modal document model
Technology peripheralsAIBreaking through the resolution limit: Byte and the University of Science and Technology of China reveal a large multi-modal document model
Now there are even large multi-modal high-resolution documents!
This technology can not only accurately identify the information in the image, but also call its own knowledge base to answer questions according to user needs
For example, when you see Mario’s interface in the picture, you can directly The answer is that this is a work of Nintendo.

This model was jointly researched by ByteDance and the University of Science and Technology of China, and was uploaded to arXiv on November 24, 2023
Study here , the author team proposed DocPedia, a unified high-resolution multi-modal document large model DocPedia.

In this study, the author used a new way to solve the shortcoming of existing models that cannot parse high-resolution document images.
DocPedia has a resolution of up to 2560×2560, but currently the industry’s advanced multi-modal large models such as LLaVA and MiniGPT-4 have an upper limit of image resolution of 336×336, which makes them unable to parse high-resolution document images.
So, how does this model perform and what kind of optimization method is used?
Significant improvement in various evaluation scores
In this paper, the author shows an example of DocPedia high-resolution image and text understanding. It can be observed that DocPedia has the ability to understand the content of instructions and accurately extract relevant graphic and text information from high-resolution document images and natural scene images
For example, in this set of pictures, DocPedia easily mines from the pictures With text information such as license plate number and computer configuration, even handwritten text can be accurately judged.

Combined with the text information in the image, DocPedia can also use large model reasoning capabilities to analyze problems based on context.

After reading the image information, DocPedia will also answer the extended content not shown in the image based on its rich world knowledge base

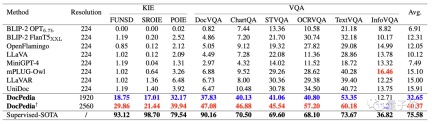
The following table quantitatively compares some existing multi-modal large models with DocPedia’s key information extraction (KIE) and visual question answering (VQA) capabilities.
By increasing the resolution and adopting effective training methods, we can see that DocPedia has achieved significant improvements on various test benchmarks
So, how does DocPedia achieve such an effect?
Solving the resolution problem from the frequency domain
DocPedia’s training is divided into two stages: pre-training and fine-tuning. In order to train DocPedia, the author team collected a large amount of graphic data containing various types of documents and built an instruction fine-tuning data set.
In the pre-training stage, the large language model will be frozen, and only the part of the visual encoder is optimized so that its output token representation space is consistent with the large language model
At this stage , the author team proposed to mainly train DocPedia’s perception capabilities, including the perception of text and natural scenes
The pre-training tasks include text detection, text recognition, end-to-end OCR, paragraph reading, full-text reading, and image text description .
In the fine-tuning phase, the large language model is unfrozen and end-to-end overall optimization is performed.
The author team proposed a perception-understanding joint training strategy: based on the original low-level perception tasks, add This joint perception-understanding training strategy further improves the performance of DocPedia.
 In terms of strategy for resolution issues, unlike existing methods, DocPedia solves it from the
In terms of strategy for resolution issues, unlike existing methods, DocPedia solves it from the
perspective. When processing high-resolution document images, DocPedia will first extract its DCT coefficient matrix. This matrix can downsample the spatial resolution by 8 times without losing the textual information of the original image.
After this step, we will use the cascaded frequency domain adapter (Frequency Adapter) Pass the input signal to the Vision Encoder for deeper resolution compression and feature extraction
With this method, a 2560×2560 image can be represented by 1600 tokens.
Compared with directly inputting the original image into a visual encoder (such as Swin Transformer), this method reduces the number of tokens by 4 times.
Finally, these tokens are spliced with the tokens converted from the instructions in the sequence dimension and input into the large model for answer.

The results of the ablation experiment show that improving resolution and performing joint perception-understanding fine-tuning are two important factors to improve DocPedia performance
The following figure compares DocPedia's answer to a paper image and the same command under different input scales. It can be seen that DocPedia answers correctly if and only if the resolution is increased to 2560×2560.

The figure below compares DocPedia’s model responses to the same scene text image and the same instruction under different fine-tuning strategies.
It can be seen from this example that the model that has been jointly fine-tuned by perception and understanding can accurately perform text recognition and semantic question answering

##Please Click the following link to view the paper: https://arxiv.org/abs/2311.11810
The above is the detailed content of Breaking through the resolution limit: Byte and the University of Science and Technology of China reveal a large multi-modal document model. For more information, please follow other related articles on the PHP Chinese website!

 How to Build Your Personal AI Assistant with Huggingface SmolLMApr 18, 2025 am 11:52 AM
How to Build Your Personal AI Assistant with Huggingface SmolLMApr 18, 2025 am 11:52 AMHarness the Power of On-Device AI: Building a Personal Chatbot CLI In the recent past, the concept of a personal AI assistant seemed like science fiction. Imagine Alex, a tech enthusiast, dreaming of a smart, local AI companion—one that doesn't rely
 AI For Mental Health Gets Attentively Analyzed Via Exciting New Initiative At Stanford UniversityApr 18, 2025 am 11:49 AM
AI For Mental Health Gets Attentively Analyzed Via Exciting New Initiative At Stanford UniversityApr 18, 2025 am 11:49 AMTheir inaugural launch of AI4MH took place on April 15, 2025, and luminary Dr. Tom Insel, M.D., famed psychiatrist and neuroscientist, served as the kick-off speaker. Dr. Insel is renowned for his outstanding work in mental health research and techno
 The 2025 WNBA Draft Class Enters A League Growing And Fighting Online HarassmentApr 18, 2025 am 11:44 AM
The 2025 WNBA Draft Class Enters A League Growing And Fighting Online HarassmentApr 18, 2025 am 11:44 AM"We want to ensure that the WNBA remains a space where everyone, players, fans and corporate partners, feel safe, valued and empowered," Engelbert stated, addressing what has become one of women's sports' most damaging challenges. The anno
 Comprehensive Guide to Python Built-in Data Structures - Analytics VidhyaApr 18, 2025 am 11:43 AM
Comprehensive Guide to Python Built-in Data Structures - Analytics VidhyaApr 18, 2025 am 11:43 AMIntroduction Python excels as a programming language, particularly in data science and generative AI. Efficient data manipulation (storage, management, and access) is crucial when dealing with large datasets. We've previously covered numbers and st
 First Impressions From OpenAI's New Models Compared To AlternativesApr 18, 2025 am 11:41 AM
First Impressions From OpenAI's New Models Compared To AlternativesApr 18, 2025 am 11:41 AMBefore diving in, an important caveat: AI performance is non-deterministic and highly use-case specific. In simpler terms, Your Mileage May Vary. Don't take this (or any other) article as the final word—instead, test these models on your own scenario
 AI Portfolio | How to Build a Portfolio for an AI Career?Apr 18, 2025 am 11:40 AM
AI Portfolio | How to Build a Portfolio for an AI Career?Apr 18, 2025 am 11:40 AMBuilding a Standout AI/ML Portfolio: A Guide for Beginners and Professionals Creating a compelling portfolio is crucial for securing roles in artificial intelligence (AI) and machine learning (ML). This guide provides advice for building a portfolio
 What Agentic AI Could Mean For Security OperationsApr 18, 2025 am 11:36 AM
What Agentic AI Could Mean For Security OperationsApr 18, 2025 am 11:36 AMThe result? Burnout, inefficiency, and a widening gap between detection and action. None of this should come as a shock to anyone who works in cybersecurity. The promise of agentic AI has emerged as a potential turning point, though. This new class
 Google Versus OpenAI: The AI Fight For StudentsApr 18, 2025 am 11:31 AM
Google Versus OpenAI: The AI Fight For StudentsApr 18, 2025 am 11:31 AMImmediate Impact versus Long-Term Partnership? Two weeks ago OpenAI stepped forward with a powerful short-term offer, granting U.S. and Canadian college students free access to ChatGPT Plus through the end of May 2025. This tool includes GPT‑4o, an a


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

WebStorm Mac version
Useful JavaScript development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Atom editor mac version download
The most popular open source editor

