

 Technology peripheralsAIImages can be rendered on mobile phones in 0.2 seconds. Google builds the fastest mobile diffusion model MobileDiffusion
Technology peripheralsAIImages can be rendered on mobile phones in 0.2 seconds. Google builds the fastest mobile diffusion model MobileDiffusionImages can be rendered on mobile phones in 0.2 seconds. Google builds the fastest mobile diffusion model MobileDiffusion

Running large generative AI models such as Stable Diffusion on mobile phones and other mobile terminals has become one of the hot spots in the industry. The generation speed is the main constraint.
Recently, a paper from Google "MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices" proposed the fastest Text-to-Image Generation on the mobile phone, on iPhone 15 It only takes 0.2 seconds on Pro. The paper comes from the same team as UFOGen. While creating an ultra-small diffusion model, it also adopts the currently popular Diffusion GAN technology route for sampling acceleration.

Please click the following link to view the paper: https://arxiv.org/abs/2311.16567
The following is the result generated by MobileDiffusion in one step.

So, how is MobileDiffusion optimized?
First of all, let us start from the problem and explore why optimization is necessary
The most popular text-to-image generation technology is based on Diffusion model is implemented. Due to the strong basic image generation capabilities of its pre-trained models and the robust nature of downstream fine-tuning tasks, we have seen the excellent performance of diffusion models in areas such as image editing, controllable generation, personalized generation, and video generation.
However, as a basic model, its shortcomings are also obvious, mainly including two aspects: First, the large number of parameters of the diffusion model leads to slow calculation speed, especially in cases of limited resources. Second, the diffusion model requires multiple steps for sampling, which further leads to slow inference speed. Taking the much-anticipated Stable Diffusion 1.5 (SD) as an example, its basic model contains nearly 1 billion parameters. We quantized the model and conducted inference on the iPhone 15 Pro. 50 steps of sampling took close to 80 seconds. Such expensive resource requirements and slow user experience greatly limit its application scenarios on the mobile terminal
In order to solve the above problems, MobileDiffusion optimizes point-to-point. (1) In response to the problem of large model size, we mainly conducted a lot of experiments and optimizations on its core component UNet, including placing computationally expensive convolution simplification and attention operations on lower layers, and targeting Mobile Devices Operation optimization, such as activation functions, etc. (2) In response to the problem that diffusion models require multi-step sampling, MobileDiffusion explores and practices one-step inference technologies like Progressive Distillation and the current state-of-the-art UFOGen.
Model optimization
MobileDiffusion is optimized based on the most popular SD 1.5 UNet in the current open source community. After each optimization operation, the performance loss relative to the original UNet model will be measured at the same time. The measurement indicators include two commonly used metrics: FID and CLIP.
Overall plan
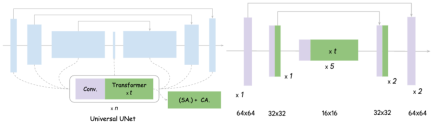
## is on the picture The left side of is the design diagram of the original UNet. It can be seen that it basically includes convolution and Transformer, and Transformer includes self-attention mechanism and cross-attention mechanism
MobileDiffusion The core ideas for UNet optimization are divided into two points: 1) Streamlining Convolution. As we all know, performing Convolution on high-resolution feature space is very time-consuming and has a large number of parameters. Here we refer to It is Full Convolution; 2) Improve Attention efficiency. Like Convolution, high Attention requires calculation of the length of the entire feature space. The Self-Attention complexity is squarely related to the flattened length of the feature space, and Cross-Attention is also proportional to the length of the space.
Experiments have proven that moving the entire 16 Transformers of UNet to the inner layer with the lowest feature resolution, and cutting out a convolution in each layer, has no obvious impact on performance. The effect achieved is: MobileDiffusion reduces the original 22 convolutions and 16 Transformers to only 11 convolutions and about 12 Transformers, and these attentions are all performed on low-resolution feature maps. The efficiency of this is greatly improved, resulting in a 40% efficiency improvement and 40% parameter shearing. The final model is shown on the right. The following is a comparison with other models:

##The content that needs to be rewritten is: Micro Design
Only a few novel designs will be introduced here. Interested readers can read the text for a more detailed introduction.
Decoupling self-attention and cross-attention
Transformer in traditional UNet contains both Self-Attention and Cross-Attention, MobileDiffusion will -Attention is all placed on the lowest resolution feature map, but a Cross-Attention is retained in the middle layer. It is found that this design not only improves the computing efficiency but also ensures the quality of the model image
Finetune softmax into relu
#As we all know, in most unoptimized cases, the softmax function is difficult to perform parallel processing and has low efficiency. MobileDiffusion proposes a new method, which is to directly adjust (finetune) the softmax function to the relu function, because the relu function is more efficient for the activation of each data point. Surprisingly, with only about 10,000 steps of fine-tuning, the model's metrics improved and the quality of the generated images was maintained. Therefore, compared to the softmax function, the advantages of the relu function are obvious
Separable Convolution
MobileDiffuison The key to streamlining parameters is also the use of Seprable Convolution. This technology has been proven to be extremely effective by work such as MobileNet, especially on the mobile side, but it is generally rarely used in generative models. MobileDiffusion experiments found that Separable Convolution is very effective in reducing parameters, especially when it is placed in the innermost layer of UNet. The analysis proves that there is no loss in model quality.
Sampling Optimization
The most popular sampling optimization methods include Progressive Distillation and UFOGen, which can achieve 8 steps and 1 step. In order to prove that these sampling methods are still effective even after the model has been extremely simplified, MobileDiffusion conducted experimental verification of these two methods
The optimized sampling was compared with the baseline model, which can be It can be seen that the indicators of the 8-step and 1-step models after sampling optimization have been significantly improved
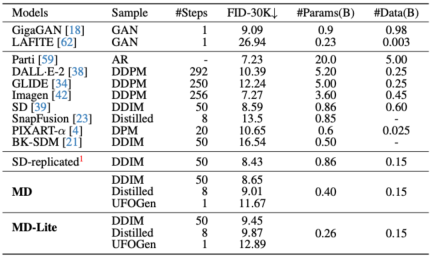
Experiment and Application
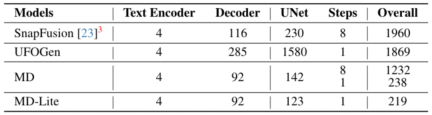
Mobile Benchmark Test
On iPhone 15 Pro, MobileDiffusion can render images at the fastest speed currently , only 0.2 seconds!
Downstream Task Test
MobileDiffusion Exploration Downstream tasks include ControlNet/Plugin and LoRA Finetune. As can be seen from the figure below, after model and sampling optimization, MobileDiffusion still maintains excellent model fine-tuning capabilities.

Summary
MobileDiffusion explored a variety of models and sampling optimization methods, and finally achieved The sub-second image generation capability on the mobile terminal also ensures the stability of downstream fine-tuning applications. We believe this will have an impact on efficient diffusion model design in the future and expand practical application cases for mobile applications
The above is the detailed content of Images can be rendered on mobile phones in 0.2 seconds. Google builds the fastest mobile diffusion model MobileDiffusion. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SublimeText3 Chinese version
Chinese version, very easy to use

Notepad++7.3.1
Easy-to-use and free code editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

