


Nine clustering algorithms to explore unsupervised machine learning

Today, I would like to share with you the common unsupervised learning clustering methods in machine learning
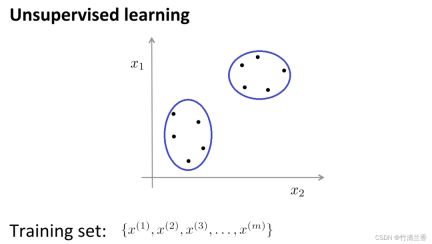
In unsupervised learning, our data does not carry any labels, so there is no need to What needs to be done in supervised learning is to input this series of unlabeled data into the algorithm, and then let the algorithm find some structures hidden in the data. Through the data in the figure below, one of the structures that can be found is the point in the data set. It can be divided into two separate sets of points (clusters), and the algorithm that can circle these clusters (cluster) is called a clustering algorithm.
Application of clustering algorithm
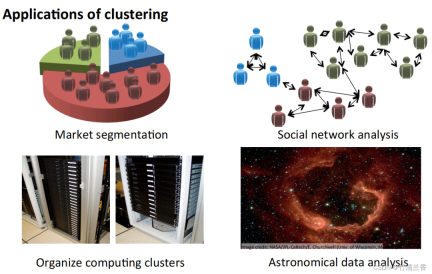
- Market segmentation: Group the customer information in the database into different groups according to markets, so as to sell them separately or improve services according to different markets.
- Social network analysis: Find a closely related group through the people who are most frequently contacted by email and the people they are most frequently contacted by.
- Organize computer clusters: In data centers, computer clusters often work together and can be used to reorganize resources, rearrange networks, optimize data centers, and communicate data.
- Understand the composition of the Milky Way: Use this information to learn something about astronomy.
The goal of cluster analysis is to divide observations into groups ("clusters") such that pairwise differences between observations assigned to the same cluster tend to be smaller than those that are different The difference between observations in a cluster. Clustering algorithms are divided into three different types: combinatorial algorithms, hybrid modeling, and pattern search.
Several common clustering algorithms are:
- K-Means Clustering
- Hierarchical Clustering
- Agglomerative Clustering
- Affinity Propagation
- Mean Shift Clustering
- Bisecting K-Means
- DBSCAN
- OPTICS
- BIRCH
K-means
The K-means algorithm is currently one of the most popular clustering methods.
K-means was proposed by Stuart Lloyd of Bell Labs in 1957. It was initially used for pulse code modulation. It was not until 1982 that the algorithm was announced to the public. In 1965, Edward W. Forgy published the same algorithm, so K-Means is sometimes called Lloyd-Forgy.
Clustering problems usually require processing a set of unlabeled data sets, and require an algorithm to automatically divide these data into closely related subsets or clusters. Currently, the most popular and widely used clustering algorithm is the K-means algorithm
Intuitive understanding of the K-means algorithm:
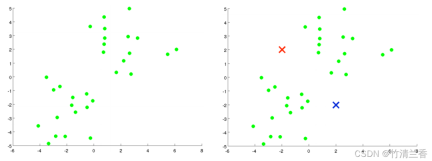
Suppose there is an unlabeled data set (left in the figure above) and we want to divide it into two clusters. Now execute the K-means algorithm. The specific operations are as follows:
- The first step is to randomly generate two points (because you want to cluster the data into two categories) (right in the picture above). These two points are called cluster centroids.
- The second step is to perform the inner loop of the K-means algorithm. The K-means algorithm is an iterative algorithm that does two things. The first is cluster assignment and the second is move centroid.
The first step in the inner loop is to perform cluster assignment, that is, traverse each sample, and then assign each point according to its distance from the cluster center. Assigning to different cluster centers (which ones are closer to each other), in this case, is to traverse the data set and color each point red or blue.
The second step of the inner loop is to move the cluster center so that the red and blue cluster centers move to the average positions of the points they belong to
Assign all points to new clusters based on their distance from the new cluster center, and continue to cycle this process until the position of the cluster center no longer changes with iteration, and the color of the points also changes. No more changes. At this time it can be said that K-means has completed aggregation. This algorithm does a pretty good job of finding two clusters in the data

Advantages of K-Means algorithm:
Simple and easy to understand, fast calculation speed, and suitable for large-scale data sets.
Disadvantages:
- For example, the processing ability for non-spherical clusters is poor and it is susceptible to initial clusters The influence of the selection of clusters requires pre-specifying the number of clusters K and so on.
- In addition, when there is noise or outliers between data points, the K-Means algorithm may assign them to the wrong clusters.
Hierarchical Clustering
Hierarchical clustering is the operation of clustering sample sets according to a certain level. The level here actually refers to the definition of a certain distance
The ultimate purpose of clustering is to reduce the number of classifications, so the behavior is similar to gradually approaching from the leaf node to the root node The dendrogram process, this behavior is also called "bottom-up"
More popularly, hierarchical clustering treats the initialized multiple clusters as tree nodes , each iteration step is to merge two similar clusters into a new large cluster, and so on, until finally only one cluster (root node) remains.
Hierarchical clustering strategies are divided into two basic paradigms: aggregation (bottom-up) and divisive (top-down).
The opposite of hierarchical clustering is divisive clustering, also known as DIANA (Divise Analysis), and its behavior process is "top-down"
The results of the K-means algorithm depend on the number of clusters chosen to search and the allocation of the starting configuration. In contrast, hierarchical clustering methods do not require such specification. Instead, they require the user to specify a measure of dissimilarity between (disjoint) groups of observations based on the pairwise dissimilarity between the two sets of observations. As the name suggests, hierarchical clustering methods produce a hierarchical representation in which clusters at each level are created by merging clusters at the next lower level. At the lowest level, each cluster contains one observation. At the highest level, there is only one cluster containing all the data
Advantages:
- Distance and regularity Similarity is easy to define and has few restrictions;
- There is no need to predetermine the number of clusters;
- The hierarchical relationship of classes can be discovered;
- can be clustered into other shapes.
Disadvantages:
- ##The computational complexity is too high;
- Singular values can also have a big impact;
- The algorithm is likely to cluster into chains.
The rewritten content is: Agglomerative Clustering is a bottom-up clustering algorithm. Treat each data point as an initial cluster and gradually merge them to form larger clusters until the stopping condition is met. In this algorithm, each data point is initially treated as a separate cluster, and then clusters are gradually merged until all data points are merged into one large cluster
Advantages:
- Applicable to clusters of different shapes and sizes, and does not require specifying the number of clusters in advance.
- The algorithm can also output a clustering hierarchy for easy analysis and visualization.
Disadvantages:
- The computational complexity is high, especially when dealing with large-scale Data sets require a large amount of computing resources and storage space.
- This algorithm is also sensitive to the selection of initial clusters, which may lead to different clustering results.
Modified content: Affinity Propagation Algorithm (AP) is usually translated as Affinity Propagation Algorithm or Proximity Propagation Algorithm
Affinity Propagation is a clustering algorithm based on graph theory designed to identify "exemplars" (representative points) and "clusters" (clusters) in data. Unlike traditional clustering algorithms such as K-Means, Affinity Propagation does not need to specify the number of clusters in advance, nor does it need to randomly initialize cluster centers. Instead, it obtains the final clustering result by calculating the similarity between data points.
Advantages:
- No need to specify the number of final clustering families
- The existing data points are used as the final cluster center instead of generating a new cluster center.
- The model is not sensitive to the initial value of the data.
- There is no requirement for the symmetry of the initial similarity matrix data.
- Compared with the k-centers clustering method, the squared error error of the result is smaller.
Disadvantages:
- The algorithm has high computational complexity and requires a lot of Storage space and computing resources;
- has weak processing capabilities for noise points and outliers.
Mean Shift Clustering
Shifting clustering is a density-based non-parametric clustering algorithm. Its basic idea is to find the maximum density of data points. locations (called "local maxima" or "peaks") to identify clusters in the data. The core of this algorithm is to estimate the local density of each data point, and use the density estimation results to calculate the direction and distance of the movement of the data point
Advantages:
- There is no need to specify the number of clusters, and it also has good results for clusters with complex shapes.
- The algorithm can also effectively handle noisy data.
Disadvantages:
- The computational complexity is high, especially when dealing with large-scale Data set needs to consume a lot of computing resources and storage space;
- This algorithm is also sensitive to the selection of initial parameters and needs to be adjusted and optimized.
Bisecting K-Means
Bisecting K-Means is a hierarchical clustering algorithm based on the K-Means algorithm. Its basic idea is to combine all data The points are divided into a cluster, and then the cluster is divided into two sub-clusters, and the K-Means algorithm is applied to each sub-cluster respectively. This process is repeated until the predetermined number of clusters is reached.
The algorithm first treats all data points as an initial cluster, then applies the K-Means algorithm to the cluster, divides the cluster into two sub-clusters, and calculates the squared error of each sub-cluster and (SSE). Then, the subcluster with the largest sum of squared errors is selected and divided into two subclusters again, and this process is repeated until the predetermined number of clusters is reached.
Advantages:
- ## has high accuracy and stability and can effectively handle large scale data set and does not require specifying the initial number of clusters.
- The algorithm is also able to output a clustering hierarchy for easy analysis and visualization.
Disadvantages:
- The computational complexity is high, especially when dealing with large-scale Data sets require a large amount of computing resources and storage space.
- In addition, this algorithm is also sensitive to the selection of initial clusters, which may lead to different clustering results.
Density-based spatial clustering algorithm DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a typical clustering algorithm with noise. Class method
The method of density has the characteristic that it does not depend on distance, but depends on density. Therefore, it can overcome the shortcoming that distance-based algorithms can only find "spherical" clusters
The core idea of the DBSCAN algorithm is: for a given data point, if its density If it reaches a certain threshold, it belongs to a cluster; otherwise, it is regarded as a noise point.
Advantages:
- This type of algorithm can overcome the problem that distance-based algorithms can only find "circular" (convex) Disadvantages of clustering;
- can find clusters of arbitrary shapes and is insensitive to noise data;
- does not need to specify the number of classes cluster;
- There are only two parameters in the algorithm, scanning radius (eps) and minimum number of included points (min_samples).
Disadvantages:
- Computational complexity, without any optimization, the algorithm The time complexity is O(N^{2}). R-tree, k-d tree, ball;
- tree index can usually be used to speed up the calculation and reduce the time complexity of the algorithm. It is O(Nlog(N));
- is greatly affected by eps. When the density of data distribution in a class is uneven, when eps is small, the cluster with small density will be divided into multiple clusters with similar properties; when eps is large, clusters that are closer and denser will be merged into one cluster. In the case of high-dimensional data, due to the curse of dimensionality, the selection of eps is more difficult;
- relies on the selection of the distance formula. Due to the curse of dimensionality, the distance metric is not important;
- It is not suitable for data sets with large density differences, because it is difficult to select eps and metric.
OPTICS
OPTICS (Ordering Points To Identify the Clustering Structure) is a density-based clustering algorithm that can automatically determine the number of clusters. At the same time, it can also discover clusters of any shape and can handle noisy data
The core idea of the OPTICS algorithm is to calculate the distance between a given data point and other points to determine its distance. reachability over density and construct a density-based distance graph. Then, by scanning this distance map, the number of clusters is automatically determined and each cluster is divided
Advantages:
- It can automatically determine the number of clusters, handle clusters of arbitrary shapes, and effectively handle noisy data.
- The algorithm is also able to output a clustering hierarchy for easy analysis and visualization.
Disadvantages:
- The computational complexity is high, especially when dealing with large-scale Data sets require a large amount of computing resources and storage space.
- This algorithm may result in poor clustering results for data sets with large density differences.
BIRCH
BIRCH (Balanced Iterative Reduction and Hierarchical Clustering) is a clustering algorithm based on hierarchical clustering that can efficiently handle large scale data set, and can achieve good results for clusters of any shape
The core idea of the BIRCH algorithm is to gradually reduce the size of the data by hierarchically clustering the data set. , and finally the cluster structure is obtained. The BIRCH algorithm uses a structure similar to B-tree, called CF tree, which can quickly insert and delete sub-clusters and can be automatically balanced to ensure the quality and efficiency of the cluster
Advantages:
- Can quickly process large-scale data sets, and has good results for clusters of any shape.
- This algorithm also has good fault tolerance for noisy data and outliers.
Disadvantages:
- For data sets with large density differences, it may cause The clustering effect is not good;
- is also not as effective as other algorithms for high-dimensional data sets.
The above is the detailed content of Nine clustering algorithms to explore unsupervised machine learning. For more information, please follow other related articles on the PHP Chinese website!

 Tool Calling in LLMsApr 14, 2025 am 11:28 AM
Tool Calling in LLMsApr 14, 2025 am 11:28 AMLarge language models (LLMs) have surged in popularity, with the tool-calling feature dramatically expanding their capabilities beyond simple text generation. Now, LLMs can handle complex automation tasks such as dynamic UI creation and autonomous a
 How ADHD Games, Health Tools & AI Chatbots Are Transforming Global HealthApr 14, 2025 am 11:27 AM
How ADHD Games, Health Tools & AI Chatbots Are Transforming Global HealthApr 14, 2025 am 11:27 AMCan a video game ease anxiety, build focus, or support a child with ADHD? As healthcare challenges surge globally — especially among youth — innovators are turning to an unlikely tool: video games. Now one of the world’s largest entertainment indus
 UN Input On AI: Winners, Losers, And OpportunitiesApr 14, 2025 am 11:25 AM
UN Input On AI: Winners, Losers, And OpportunitiesApr 14, 2025 am 11:25 AM“History has shown that while technological progress drives economic growth, it does not on its own ensure equitable income distribution or promote inclusive human development,” writes Rebeca Grynspan, Secretary-General of UNCTAD, in the preamble.
 Learning Negotiation Skills Via Generative AIApr 14, 2025 am 11:23 AM
Learning Negotiation Skills Via Generative AIApr 14, 2025 am 11:23 AMEasy-peasy, use generative AI as your negotiation tutor and sparring partner. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including identifying and explaining
 TED Reveals From OpenAI, Google, Meta Heads To Court, Selfie With MyselfApr 14, 2025 am 11:22 AM
TED Reveals From OpenAI, Google, Meta Heads To Court, Selfie With MyselfApr 14, 2025 am 11:22 AMThe TED2025 Conference, held in Vancouver, wrapped its 36th edition yesterday, April 11. It featured 80 speakers from more than 60 countries, including Sam Altman, Eric Schmidt, and Palmer Luckey. TED’s theme, “humanity reimagined,” was tailor made
 Joseph Stiglitz Warns Of The Looming Inequality Amid AI Monopoly PowerApr 14, 2025 am 11:21 AM
Joseph Stiglitz Warns Of The Looming Inequality Amid AI Monopoly PowerApr 14, 2025 am 11:21 AMJoseph Stiglitz is renowned economist and recipient of the Nobel Prize in Economics in 2001. Stiglitz posits that AI can worsen existing inequalities and consolidated power in the hands of a few dominant corporations, ultimately undermining economic
 What is Graph Database?Apr 14, 2025 am 11:19 AM
What is Graph Database?Apr 14, 2025 am 11:19 AMGraph Databases: Revolutionizing Data Management Through Relationships As data expands and its characteristics evolve across various fields, graph databases are emerging as transformative solutions for managing interconnected data. Unlike traditional
 LLM Routing: Strategies, Techniques, and Python ImplementationApr 14, 2025 am 11:14 AM
LLM Routing: Strategies, Techniques, and Python ImplementationApr 14, 2025 am 11:14 AMLarge Language Model (LLM) Routing: Optimizing Performance Through Intelligent Task Distribution The rapidly evolving landscape of LLMs presents a diverse range of models, each with unique strengths and weaknesses. Some excel at creative content gen


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Linux new version
SublimeText3 Linux latest version

Atom editor mac version download
The most popular open source editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

