
Home >Technology peripherals >AI >Practice and thinking on Baidu video recommendation cross-domain multi-objective estimation and fusion
Practice and thinking on Baidu video recommendation cross-domain multi-objective estimation and fusion

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-12-01 11:47:181241browse

##1. Baidu video background introduction
1. Unified product form

On the one hand, all video scenes in Baidu APP have been upgraded to a unified immersive (up and down) interactive form; on the other hand, based on Baidu's unified large model, we have opened up the data of all scenes and recommended experiences. The unification of interaction and data can better achieve ecological win-win and promote the long-term development of Baidu Video.
#In order to better cultivate users’ video consumption habits, we have also created a first-level entrance for video consumption (bottom navigation bar entrance). If you are interested, you can download Baidu APP. If you have good suggestions or bad cases, you are always welcome to give us feedback.
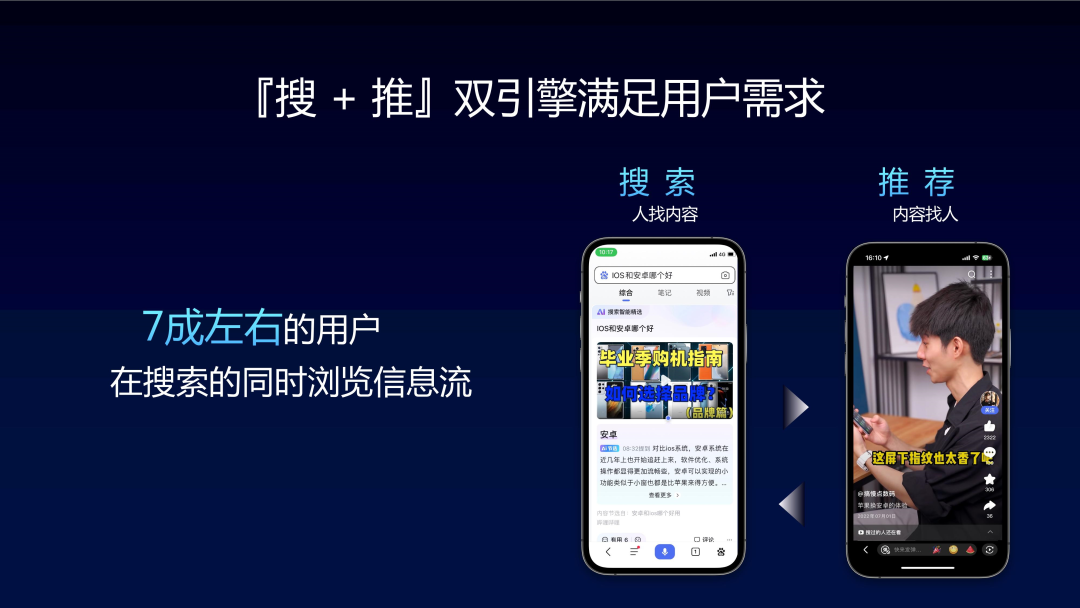
2. Dual search and push engines to meet user needs
It is worth mentioning that Baidu started out as a search engine , the usage rate of search is extremely high, and search data needs to be better used in recommendation scenarios to meet user needs through the dual "search and push" engines. Search is mainly "people looking for content", users will clearly enter their needs, while recommendations are "content looking for people". Integrating search signals and recommendation signals across domains to achieve better integration of recommendation and search is also one of Baidu's advantages.
## 2. Overview of the recommendation system
1. Problems solved by the recommendation system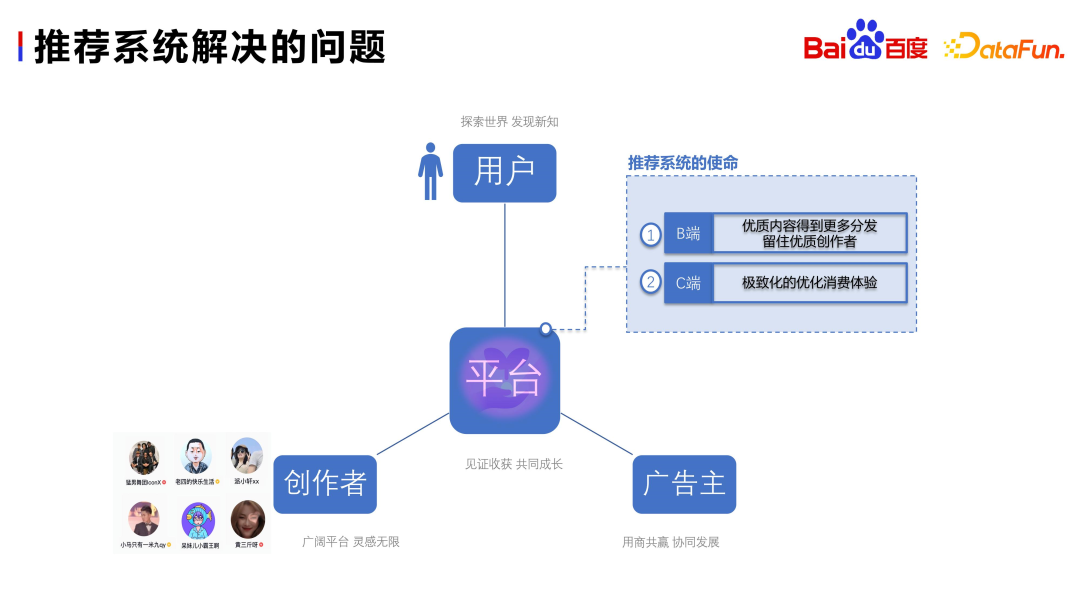
- Users: Explore the world and discover new perceptions here.
- Creators: The basis for platform recommendations and content supply for the platform; the platform provides them with a broad space to inspire their unlimited inspiration and creation.
- Advertisers: Provide financial support for the survival of the platform. Most platforms make a living from advertising.
- The content selection mechanism of survival of the fittest (B-side): How to get more distribution of high-quality content and retain high-quality creators.
- Ultimate user consumption experience (C-side): Only when user demands are met can continuous improvement in scale be promoted.
2. Overview of the recommendation system
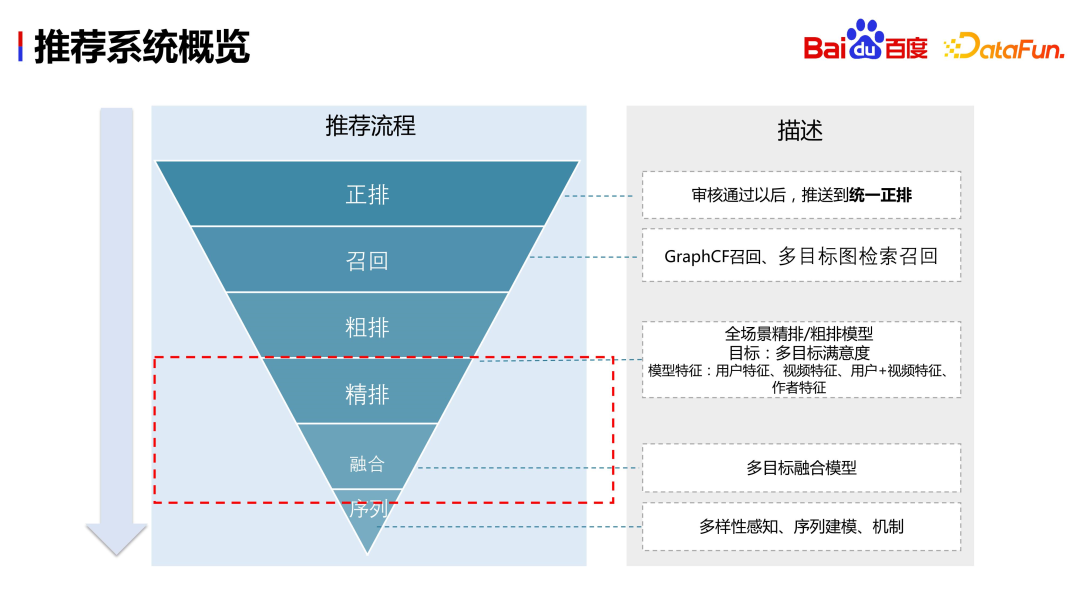
The following content will mainly focus on the fusion of accurately aligned target designs and models
##3. Multi-objective design and modeling
First of all, we want to introduce the application of multi-objective design in video recommendation
1. Thoughts on target design
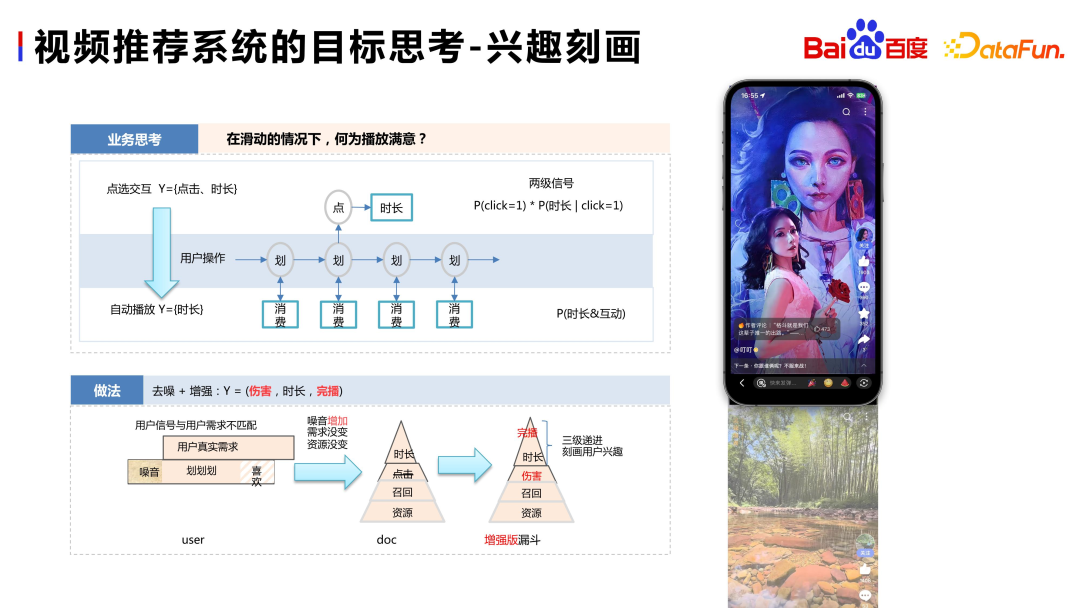
First of all, please think about how to design a recommendation system in a video immersive scenario. What about the goal?
In traditional recommendation systems, users consume resources by clicking on content or videos, thereby clearly expressing their preference for the resource. Therefore, in traditional recommendation scenarios, click behavior is a very important signal and a clear and simple feedback method. However, in immersive scenarios, due to the lack of clear feedback, user preferences are often expressed through "hidden" behaviors. At this time, viewing time becomes an extremely important signal in immersive recommendation scenarios

In addition to the above consumption time, it is also necessary to consider the behavior of users actively leaving in the system, such as following, commenting, sharing, and liking. However, compared with playback data, these behavioral data are very sparse, maybe only one thousandth of the order.
In addition to these interactive signals, there are also some recommendations in Baidu APP A very important data is the search signal. 70% of users on Baidu consume both recommended information streams and search. Therefore, the recommendation system also needs to depict the satisfaction signal of the user's search domain.
B-side creators need a competition mechanism to screen out inferior creators and stimulate the creative potential of high-quality creators, in addition to consumer signals that C-side users are satisfied with, so as to achieve production and a virtuous cycle of consumption
2. Dimensions considered in target design
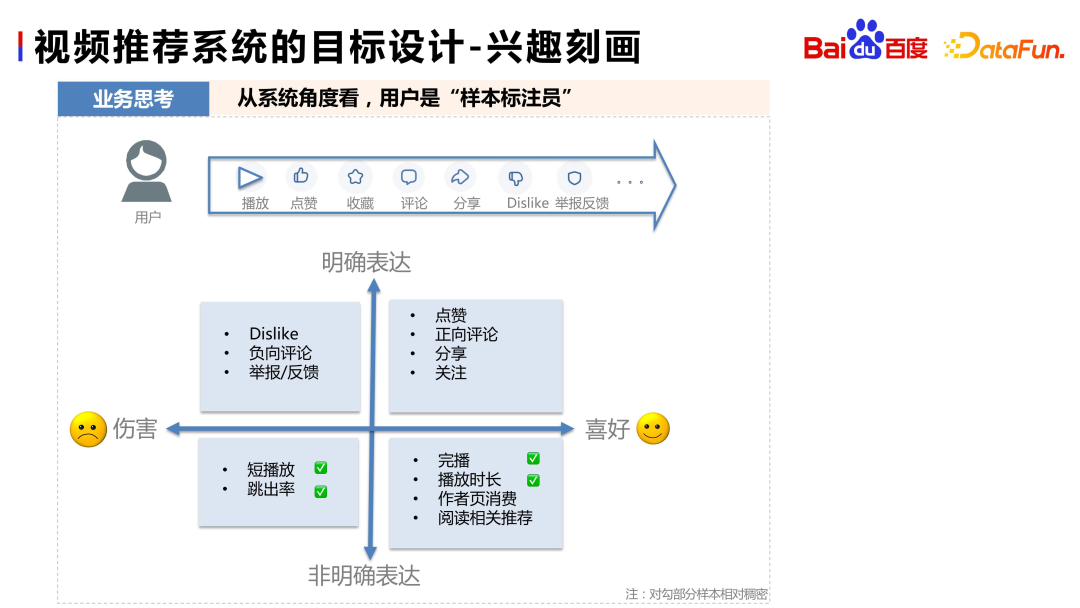
From the perspective of the recommendation system, users are sample annotators. Users have some clear positive expressions, such as playing, liking, collecting, commenting, etc.; there are also some clear negative expressions, such as Dislike, Negative Comment, report, etc. In addition to explicit expressions, users will also have some implicit expressions, such as liking expressed through the completion of broadcasts, playback duration, author page consumption, reading related recommendations, etc., or disliking expressed through short broadcasts, quick pop-ups, etc. Therefore, when designing goals, we must think in all aspects, balance explicit signals and implicit signals, and avoid designing a "partial" recommendation system.
3. Comprehensive Satisfaction Modeling
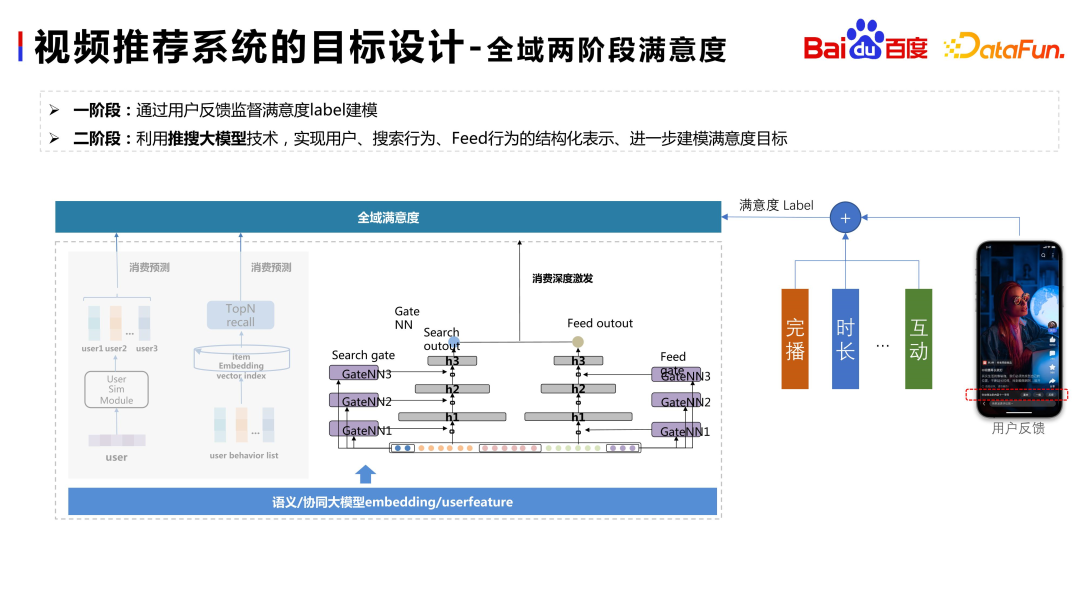
In addition to the above basic goals, we will also design some The high-level goal is no longer simply to use user feedback. For example, as shown on the right side of the figure above, we have launched a model based on user satisfaction feedback. In the first stage, through dense signals such as broadcast completion and duration, simple rules or models are used to fit user satisfaction feedback to obtain a relatively dense user satisfaction label. In the second stage, a satisfaction model is built based on this label, using the Embedding generated by the large-scale push search model, Wenxin underlying Embedding, and user portrait and behavior sequence feature modeling to evaluate the satisfaction gain of the recommended domain relative to the search domain. . If a user has consumed a certain point of interest in search, the recommendation system can recommend higher-quality content based on the satisfaction model, which can make the integration of search and push more smooth and better migrate search interests to the feed.
4. Long Term Value Modeling (Long Term Value)
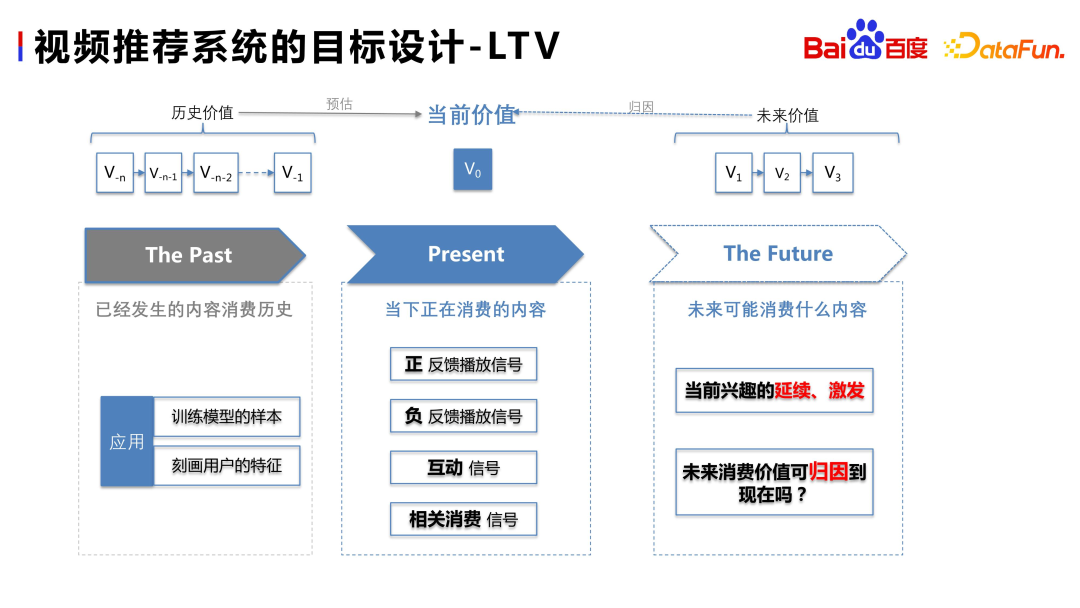
Introduced in the previous article how Estimate play time and interaction for current content. We can use users' historical consumption behavior as samples or features to predict whether the upcoming content will have positive or negative feedback, and whether there will be satisfactory interaction and consumption
We can further think about whether there is a relationship between the user's future consumption content and the current consumption content? For example, if users are watching Guo Degang's videos now, and if they continue to consume Yu Qian's videos on the next Nth day, are these Yu Qian's videos "inspired" by Guo Degang's videos? Can consuming future points of interest be considered a “continuation” of current points of interest? The answer is yes. Therefore, we introduced the LTV system into the system to attribute future long-term value content to the recommendation of the current video
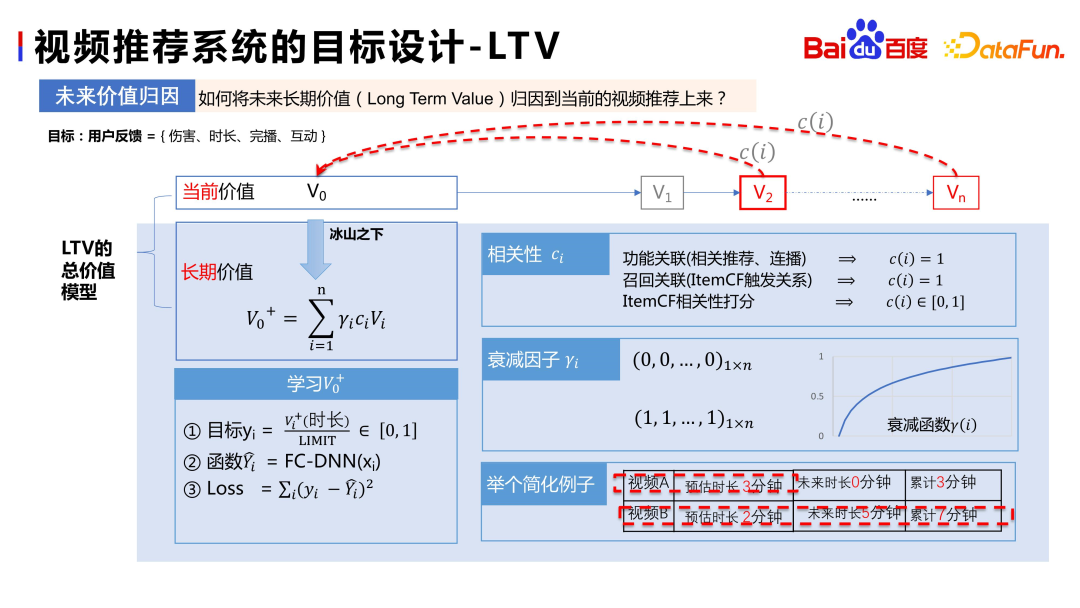
Assumption V0 is the value of the current video, V1, V2,... Vn is the video that the user will consume in the future, assuming V 2 and Vn are satisfactory consumption and are a continuation of V0 , so they can be attributed to V0 .
There are many attribution methods. According to the business scenario of Baidu Feed, attribution includes the following three parts:
- Function attribution: If you view the mounted resources through relevant recommendations, then this part of the resource consumption signal can be attributed to V0 .
- # Attribution of recall association: For example, the recall stage is implicitly recalled through itemCF and so on.
- Correlation: For example, the correlation between resources can be measured through multi-modal embedding or recommended large model embedding, such as Vn is higher than V0 With the correlation score, the value of Vn can be attributed to V0 Come up.
Of course, this attribution is weighted. We use the time interval from V0 , and V0 's correlation and other factors to adjust the attribution weight of the user's future video consumption, thereby obtaining the long-term value of the current video V0 . After having a long-term value goal, learning is relatively simple. The first step is to normalize the goal, and then directly model it.
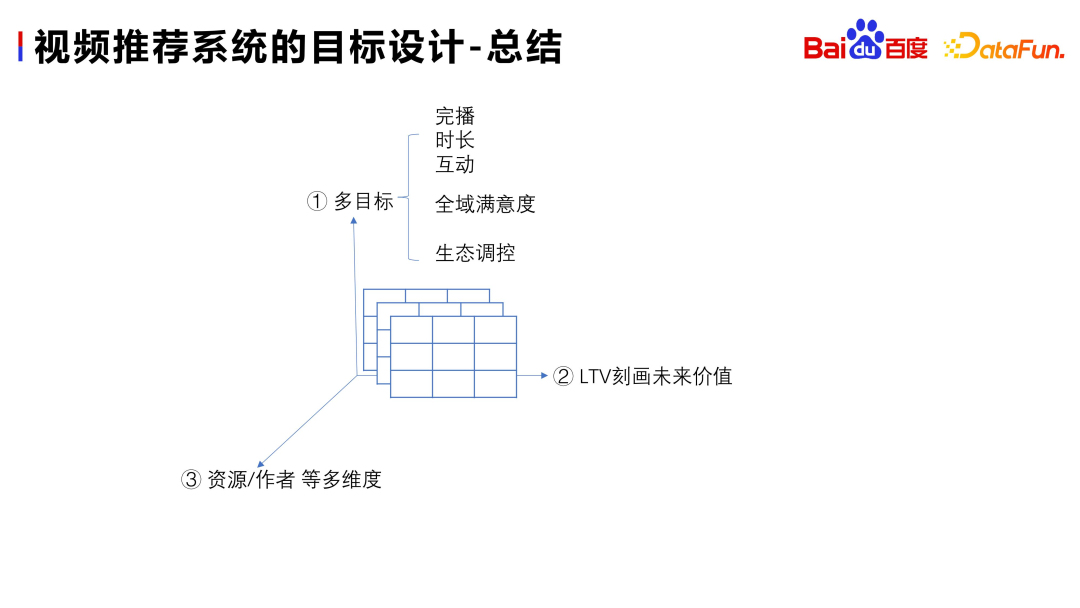
Based on the abstraction and combing of the business status quo, we will start from the following three directions to make a brief summary when designing the recommendation system goals
- Multiple objectives, first carry out basic physical target modeling, followed by modeling of some high-level targets, to describe the satisfaction of the whole scene, and at the same time, the ecology needs to be Regulation.
- #Characterize the value of the future.
- #In addition to the resource dimension, other dimensions can also be considered, such as the modeling of the author dimension.
To comprehensively consider various development directions, the goals of the recommendation system need to be approached from multiple angles
5, Baidu Feed model technology change, linkage experience evolution
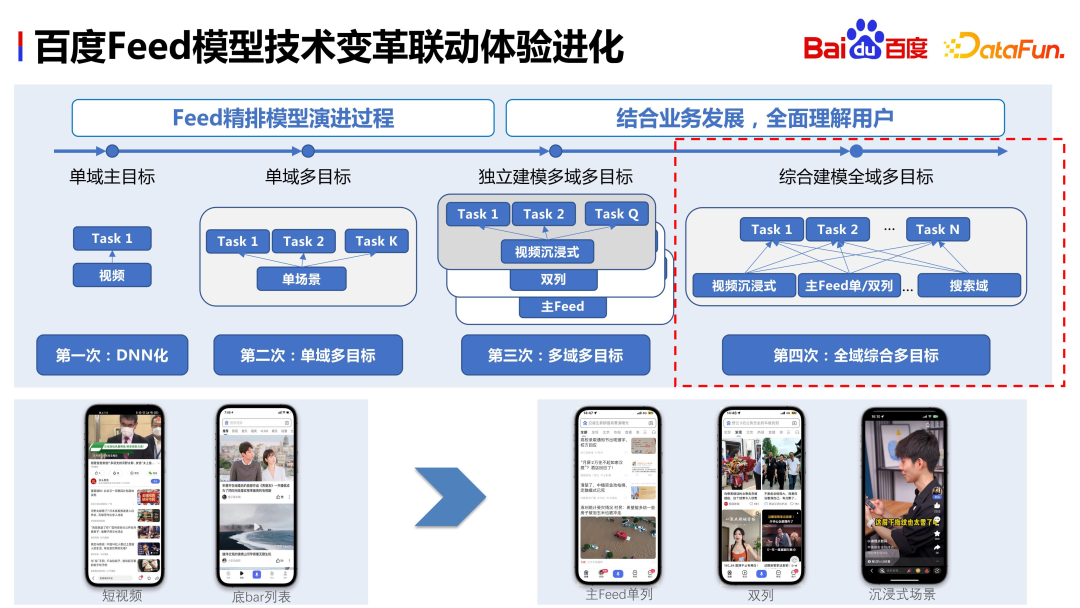
The development of Baidu’s recommendation scenarios has been divided into three main scenarios:
- "Recommended" information flow: It has existed for many years.
- "Discover" scene: In contrast, the main feed is more information-oriented, while "Discover" is more relaxed and lively, and close to life.
- "Immersive" scene: consumption flow in the form of pure video.
The development and evolution of Baidu products has led to the gradual change of ranking goals. Initially, it only had the main goal of a single field, and then developed into multiple fields and multiple goals. Now it has achieved comprehensive modeling in all fields, integrating samples from multiple fields to achieve full sharing of information. The following will introduce the specific content of comprehensive modeling in all fields
6. Cross-domain multi-objective modeling
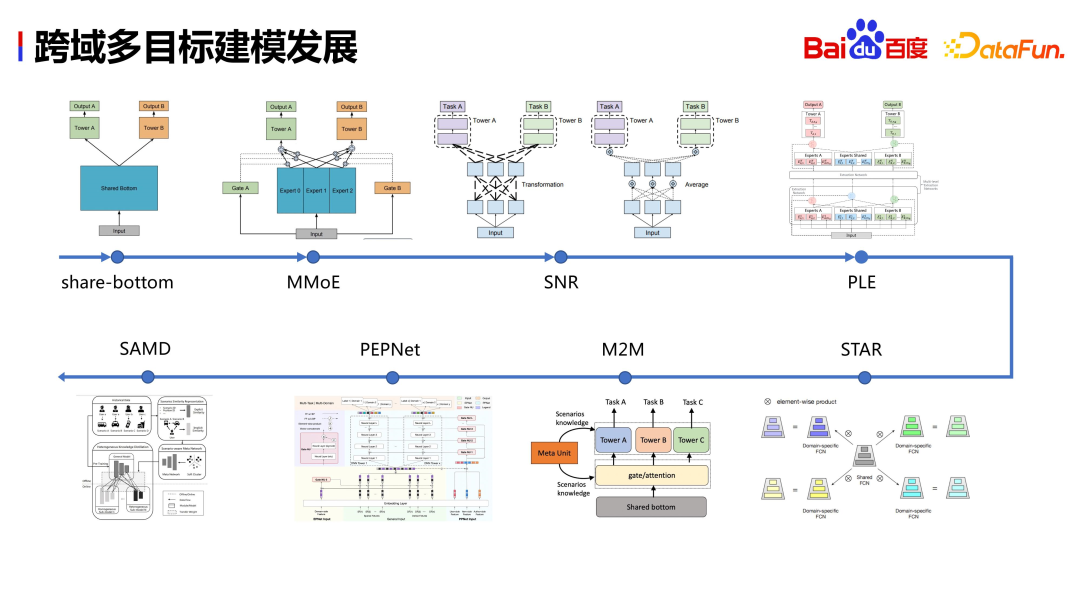
First of all, let’s take a look at what the industry has done. Whether it is MMoE, PLE, or the STAR network, PEPNet and other structures that Alibaba is working on, as well as companies such as Google and Tencent, they are sparing no effort to design various network structures based on their own businesses, hoping to share them in heterogeneous scenarios. More useful information. These works mainly solve two problems:
- The migration problem of cross-domain signals, and how to better migrate between two different domains to achieve cross-domain information sharing.
- The problem of negative transfer between multiple targets is the seesaw effect of multiple targets.
The same Baidu recommendation system also faces these two problems.
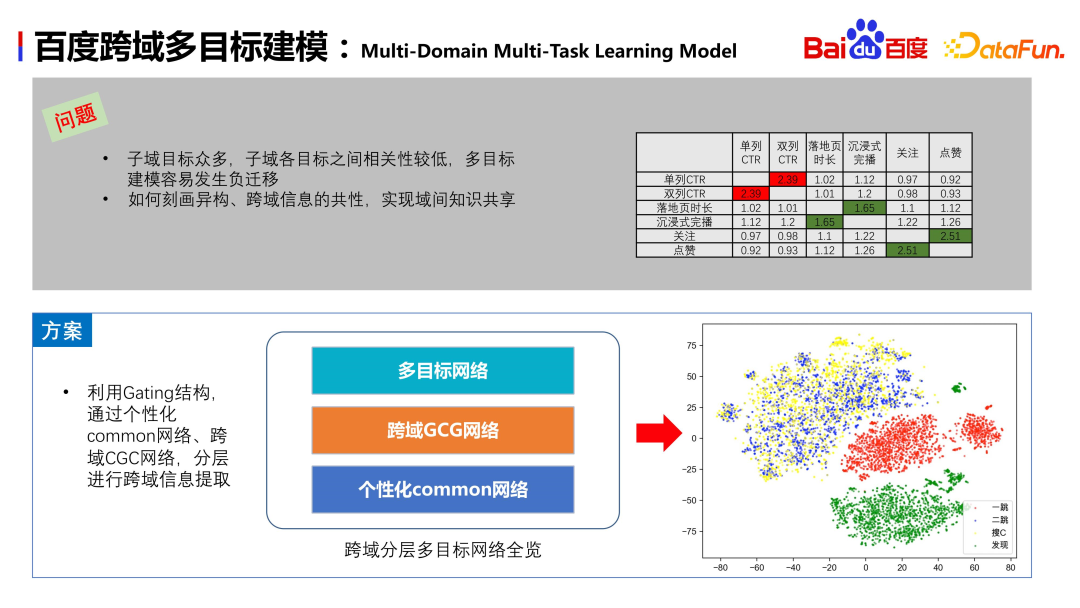
There are many different sub-domain targets in Baidu’s scenario, and the correlation between these targets is low. This can lead to negative migration between multiple targets. To solve this problem, one needs to analyze the PNRs between different targets and find out the correlation differences between them. In other words, how to describe user information in heterogeneous scenarios and how to implement the migration of heterogeneous information are issues that need to be solved by the model structure
According to Baidu’s business needs, we A cross-domain hierarchical multi-objective network structure is designed, using the Gating structure. This structure is mainly divided into three layers: the first is the personalized sharing network as the bottom layer; the second layer is the GCG network for cross-domain information extraction; and the last layer is the multi-objective network of sub-domains. Through this design, we can perform multi-objective estimation for each domain while sharing information
This solution has a significant improvement compared with single-domain multi-objective, and it is online for the first time AUC increases by about 3-9 thousand points. As shown in the lower right corner of the above figure, after obtaining the embedding of user characteristics in multiple domains and performing a TSNE dimensionality reduction, except that search C and second hop are relatively close, the distinction between the other two scenarios is still relatively obvious, indicating that The model can learn the differences between scenes. It is reasonable that there is not much difference between the search C and second-hop scenarios. They are both video scenarios, and the user's interaction and interest are not very different.
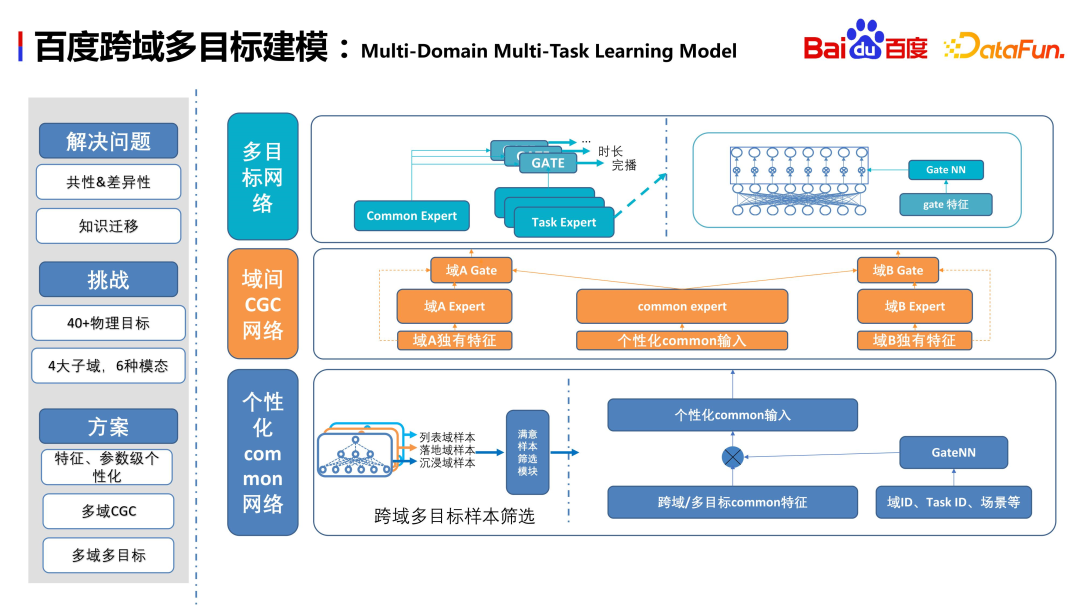
Baidu business scenarios have more than 40 physical targets, 4 large subdomains, and 6 forms. Including videos, graphics, dynamics, mini programs, etc. We hope that the model can perform well in many complex businesses. Let’s briefly introduce the model structure. The first layer is the common network, which serves as the base for domain division, screening satisfactory samples of multiple targets in each scene, and realizing personalized embedding mapping through the gate network. The second layer is the extraction of inter-domain information, which implements unique features and personalized shared features within the domain through the CGC network. The two jointly construct cross-domain information extraction. The advantage is that it not only retains the information richness within the domain, but also extracts the shared information of heterogeneous scenes. The third layer is multi-objective modeling of subdomains. We also have a corresponding paper being published on this topic. Friends who are interested in the details can read the paper.
##4. Multi-target fusion
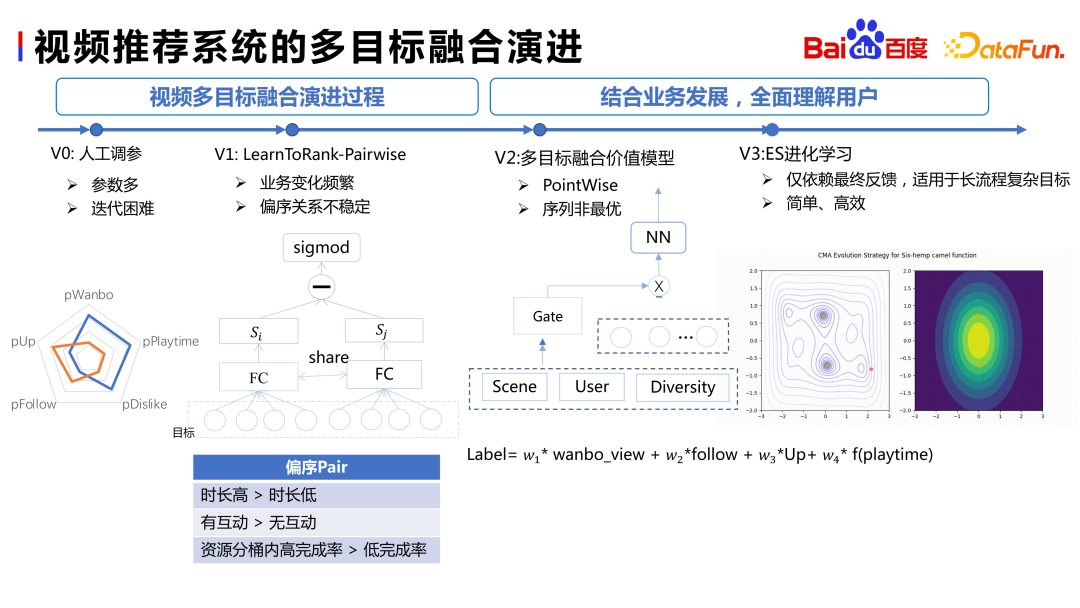
Baidu’s multi-objective integration evolution process is similar to that of the industry. The first is prior knowledge fusion, which although simple and straightforward, requires a lot of manpower. Then we upgraded to LTR, and the effect was remarkable. However, the disadvantage was that it required frequent adjustments when the business changed. At the same time, the partial order relationship also changed with changes in business and user stratification. Afterwards, we adopted a multi-objective fusion value model, using a sequential optimal approach. After short-term use, we upgraded to the method we are using now - ES (Evolution Strategy) evolutionary learning
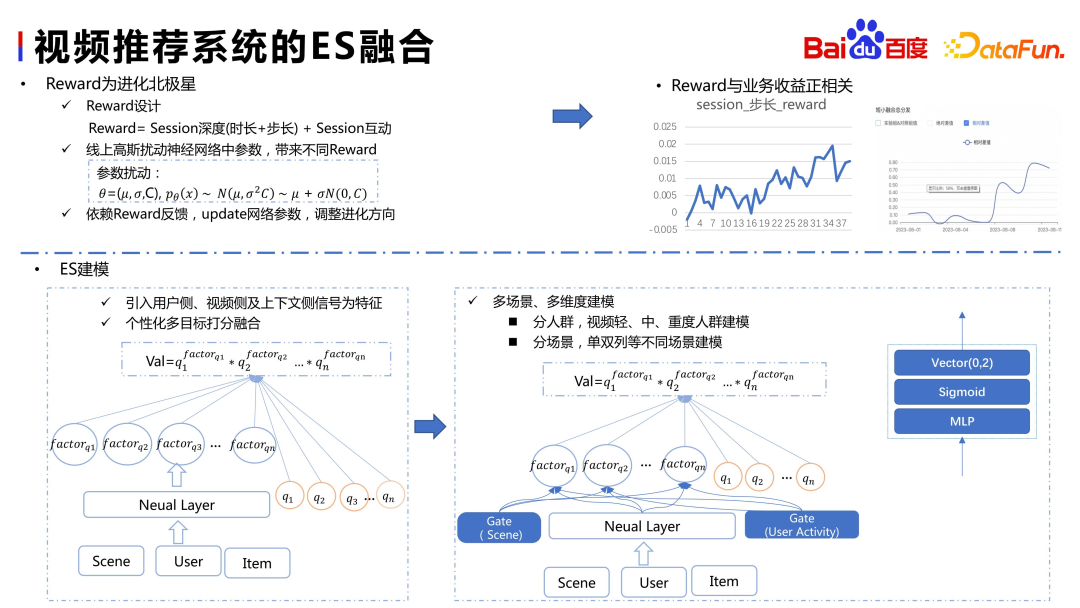
To use ES, you first need to define a reward, which is the North Star indicator. Baidu's rewards are the depth of the session (duration + step) and interaction. The business indicators corresponding to duration and step are duration and video playback volume. These two indicators reflect user retention, that is, LT. In addition, there is interactive information, which represents the user's accumulation of assets in the APP, such as paying attention to the author's behavior. In fact, he hopes to be able to find the author after he updates. Whether it is increasing the number of consumption or interactions, we hope that users can use this APP for a longer period of time
Our initial version is a simple heuristic model, while the current online ES performs more advanced calculations, such as introducing information about different scenarios and groups of people
The above is the detailed content of Practice and thinking on Baidu video recommendation cross-domain multi-objective estimation and fusion. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to implement a recommendation system in PHP?
- Tips on using cache to handle recommendation system optimization algorithms in Golang.
- PHP implements the recommendation system and personalized recommendation functions in the knowledge question and answer website.
- How to develop recommendation system functionality using Redis and Perl
- How to use Workerman to implement a real-time location-based recommendation system