

 Technology peripheralsAIThrough 8 billion parameters OtterHD, the Chinese team of Nanyang Polytechnic brings you the experience of counting camels in 'Along the River During Qingming Festival'
Technology peripheralsAIThrough 8 billion parameters OtterHD, the Chinese team of Nanyang Polytechnic brings you the experience of counting camels in 'Along the River During Qingming Festival'
Want to know how many camels are in "Along the River During Qingming Festival"? Let’s take a look at this multi-modal model that supports UHD input.
Recently, a Chinese team from Nanyang Polytechnic built the 8 billion parameter multi-modal large model OtterHD based on Fuyu-8B.

Paper address: https://arxiv.org/abs/2311.04219
with restrictions Unlike traditional models of fixed-size visual encoders, OtterHD-8B has the ability to handle flexible input sizes, ensuring its versatility under various inference needs.
At the same time, the team also proposed a new benchmark test MagnifierBench, which can carefully evaluate LLM's ability to distinguish the minute details and spatial relationships of objects in large-size images.
Experimental results show that the performance of OtterHD-8B is significantly better than similar models in directly processing high-resolution inputs
Effect Demonstration
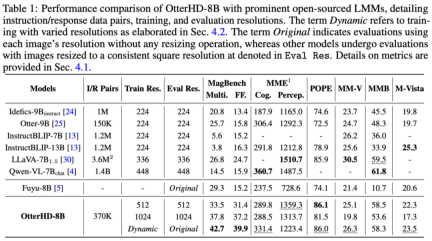
As shown below, we ask how many camels are in the Qingming River Scene (part). The image input reaches 2446x1766 pixels, and the model can also answer the question successfully. .
Faced with the apple-counting problem that GPT4-V once confused, the model successfully calculated that it contained 11 apples

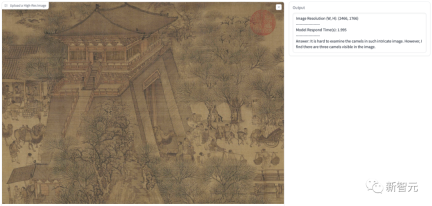
In addition to the high-definition input example shown in the paper, we also conducted some tests. In the figure below, we let the model assume that the user It's a PhD from Cambridge University, explaining what this picture means.
The model's answer accurately identified the Black Hole and White Hole information in the picture, and identified it as a tunnel-like structure, and then gave a detailed explanation. .
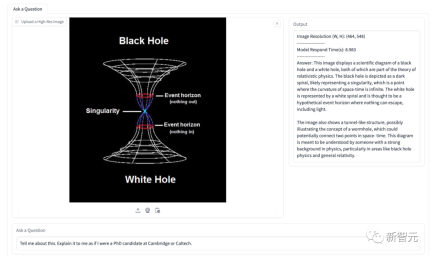
In the diagram below, the model is asked to explain the situation regarding energy share. The model successfully identifies several energy types shown in the figure and accurately presents their proportions over time
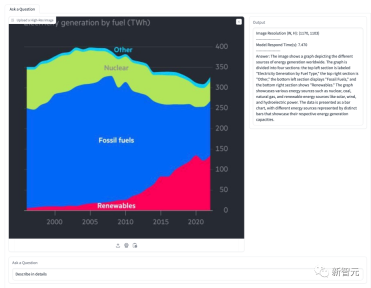
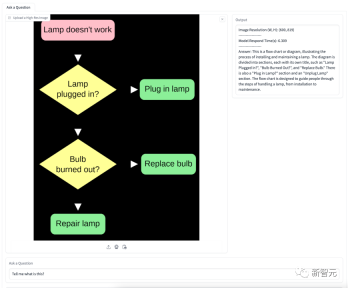
Figure is about the flow chart of changing a light bulb. The model accurately understands the meaning of the flow chart and gives step-by-step detailed guidance.
8 billion parameter command fine-tuning OtterHD-8B
Fuyu-8B’s OtterHD-8B is the first An open source instruction to fine-tune large language models trained on inputs up to 1024×1024, which is noteworthy
Additionally, during inference, it can be further extended to larger Resolution (such as 1440×1440).
Training details
In preliminary experiments, the team found that Fuyu was good at training certain The benchmark performed poorly in responding to specific instructions, which resulted in very weak model performance on MME and MMBench
To address these issues, the team performed instruction fine-tuning, based on 370K Mixed data adjusts the Fuyu model and refers to the similar instruction template of LLaVA-1.5 to standardize the format of model answers
In the training phase, all data sets are organized into instructions/responses Yes, summarized into a unified dataloader and uniformly sampled to ensure representative integrity.
In order to improve the performance of the modeling code, the team adopted FlashAttention-2 and the operator fusion technology in the FlashAttention resource library
With the help of Fuyu’s simplified architecture , as shown in Figure 2, these modifications significantly improved GPU utilization and throughput

# Specifically, the method proposed by the team can Full parameter training is completed in 3 hours/epoch on an 8×A100 GPU, while it only takes 1 hour per epoch after LoRA fine-tuning.
When training the model using the AdamW optimizer, the batch size is 64, the learning rate is set to 1×10^-5, and the weight decay is 0.1.
Ultra-fine evaluation benchmark MagnifierBench
The human visual system can naturally perceive the details of objects within the field of view, but the benchmark currently used to test LMM There is no particular focus on assessing competencies in this area.
With the advent of the Fuyu and OtterHD models, we are extending the resolution of the input image to a larger range for the first time.
To this end, the team created a new test benchmark MagnifierBench covering 166 images and a total of 283 sets of questions based on the Panoptic Scene Graph Generation (PVSG) data set.
The PVSG dataset consists of video data, which contains a large number of messy and complex scenes, especially first-person housework videos.
During the annotation phase, the team carefully examined every question-answer pair in the dataset, eliminating those that involved large objects, or that were easily answered with common sense knowledge. For example, most remote controls are black, which is easy to guess, but colors such as red and yellow are not included in this list.
As shown in Figure 3, the types of questions designed by MagnifierBench include recognition, number, color-related questions, etc. An important criterion for this dataset is that the questions must be complex enough that even the annotator must be in full-screen mode or even zoom in on the image to answer accurately

Compared with short answers, LMM is better at generating extended answers in conversational environments.
-Multiple choice questions
The problem faced by this model is that there are multiple options to choose from. To guide the model to choose a letter (such as A, B, C) as the answer, the team preceded the question with a letter from a given choice as a prompt. In this case, only the answer that exactly matches the correct option will be considered the correct answer
- Open question
Multiple options will simplify the task because random guessing has a 25% chance of being correct. Furthermore, this does not reflect real-life scenarios faced by chat assistants, as users typically do not provide predefined options to the model. To eliminate this potential bias, the team also asked the model questions in a straightforward, open-ended manner with no prompt options.
Experimental analysis
The research results show that although many models achieve high scores on established benchmarks such as MME and POPE, they fail to perform well on MagnifierBench The performance is often unsatisfactory. The OtterHD-8B, on the other hand, performed well on MagnifierBench.
In order to further explore the effect of increasing the resolution and test the generalization ability of OtterHD at different, possibly higher resolutions, the team conducted experiments on Otter8B using fixed or dynamic resolutions. The x-axis shows that as the resolution increases, more image tokens are sent to the language decoder, thus providing more image details.
Experimental results show that as the resolution increases, the performance of MagnifierBench also improves accordingly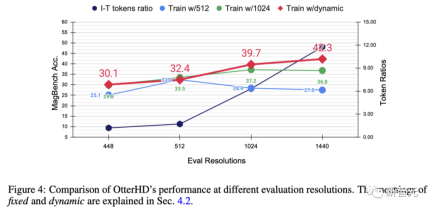
As the resolution increases, the ratio of images to text gradually increases. This is because the average number of text tokens remains the same. This change highlights the importance of LMM resolution, especially for tasks that require complex visual association.

Furthermore, the performance difference between fixed and dynamic training methods highlights the advantages of dynamic resizing, especially in preventing overfitting at specific resolutions.
The dynamic strategy also has the advantage of allowing the model to adapt to higher resolutions (1440) even if it has not been seen during training
Some comparisons




##Conclusion
Based on the innovative architecture of Fuyu-8B, the research team proposed the OtterHD-8B model, It can effectively handle images of various resolutions and get rid of the limitations of fixed resolution input in most LMMs
At the same time, OtterHD-8B is very good at processing high-resolution images. Excellent performance
This becomes especially evident in the new MagnifierBench benchmark. The purpose of this benchmark is to evaluate the LMM's ability to recognize details in complex scenes, highlighting the importance of more flexible support for different resolutions
The above is the detailed content of Through 8 billion parameters OtterHD, the Chinese team of Nanyang Polytechnic brings you the experience of counting camels in 'Along the River During Qingming Festival'. For more information, please follow other related articles on the PHP Chinese website!

 解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM
解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM译者 | 布加迪审校 | 孙淑娟目前,没有用于构建和管理机器学习(ML)应用程序的标准实践。机器学习项目组织得不好,缺乏可重复性,而且从长远来看容易彻底失败。因此,我们需要一套流程来帮助自己在整个机器学习生命周期中保持质量、可持续性、稳健性和成本管理。图1. 机器学习开发生命周期流程使用质量保证方法开发机器学习应用程序的跨行业标准流程(CRISP-ML(Q))是CRISP-DM的升级版,以确保机器学习产品的质量。CRISP-ML(Q)有六个单独的阶段:1. 业务和数据理解2. 数据准备3. 模型
 人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM
人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM人工智能(AI)在流行文化和政治分析中经常以两种极端的形式出现。它要么代表着人类智慧与科技实力相结合的未来主义乌托邦的关键,要么是迈向反乌托邦式机器崛起的第一步。学者、企业家、甚至活动家在应用人工智能应对气候变化时都采用了同样的二元思维。科技行业对人工智能在创建一个新的技术乌托邦中所扮演的角色的单一关注,掩盖了人工智能可能加剧环境退化的方式,通常是直接伤害边缘人群的方式。为了在应对气候变化的过程中充分利用人工智能技术,同时承认其大量消耗能源,引领人工智能潮流的科技公司需要探索人工智能对环境影响的
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM
条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM条形统计图用“直条”呈现数据。条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条,然后把这些直条按一定的顺序排列起来;从条形统计图中很容易看出各种数量的多少。条形统计图分为:单式条形统计图和复式条形统计图,前者只表示1个项目的数据,后者可以同时表示多个项目的数据。
 自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PM
自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PMarXiv论文“Sim-to-Real Domain Adaptation for Lane Detection and Classification in Autonomous Driving“,2022年5月,加拿大滑铁卢大学的工作。虽然自主驾驶的监督检测和分类框架需要大型标注数据集,但光照真实模拟环境生成的合成数据推动的无监督域适应(UDA,Unsupervised Domain Adaptation)方法则是低成本、耗时更少的解决方案。本文提出对抗性鉴别和生成(adversarial d
 数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM
数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM数据通信中的信道传输速率单位是bps,它表示“位/秒”或“比特/秒”,即数据传输速率在数值上等于每秒钟传输构成数据代码的二进制比特数,也称“比特率”。比特率表示单位时间内传送比特的数目,用于衡量数字信息的传送速度;根据每帧图像存储时所占的比特数和传输比特率,可以计算数字图像信息传输的速度。
 数据分析方法有哪几种Dec 15, 2020 am 09:48 AM
数据分析方法有哪几种Dec 15, 2020 am 09:48 AM数据分析方法有4种,分别是:1、趋势分析,趋势分析一般用于核心指标的长期跟踪;2、象限分析,可依据数据的不同,将各个比较主体划分到四个象限中;3、对比分析,分为横向对比和纵向对比;4、交叉分析,主要作用就是从多个维度细分数据。
 聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM
聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块。这两个模块主要区别如下:json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式;json 是我们可以直观阅读的,而 pickle 不可以;json 是可互操作的,在 Python 系统之外广泛使用,而 pickle 则是 Python 专用的;默认情况下,json 只能表示 Python 内置类型的子集,不能表示自定义的


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SublimeText3 Chinese version
Chinese version, very easy to use

