
Home >Technology peripherals >AI >Code Data Augmentation in Deep Learning: A Review of 89 Researches in 5 Years
Code Data Augmentation in Deep Learning: A Review of 89 Researches in 5 Years

- 王林forward
- 2023-11-23 14:33:441320browse
With the rapid development of deep learning and large-scale models, the pursuit of innovative technologies continues to increase. In this process, data augmentation technology has shown a value that cannot be ignored
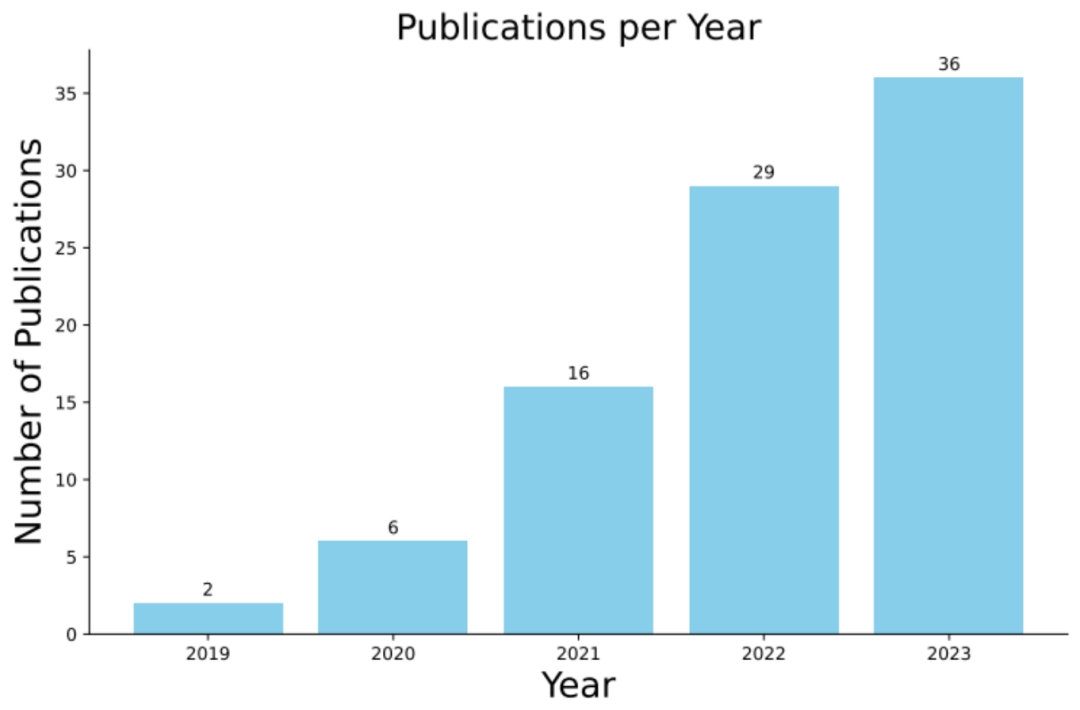
Recently, researchers from Monash University, Singapore Management University, Huawei Noah’s Ark Laboratory, and Beijing University of Aeronautics and Astronautics and the Australian National University jointly conducted a survey of 89 related research papers in the past five years, and released a comprehensive review on the application of code data enhancement in deep learning.

- ##Paper address: https://arxiv.org/abs/2305.19915
- Project address: https://github.com/terryyz/DataAug4Code
This review not only explores code data in depth The application of enhancement technology in the field of deep learning also looks forward to its future development potential. As a technique to increase the diversity of training samples without collecting new data, code data augmentation has gained widespread application in machine learning research. These techniques are of significant significance for improving the performance of data-driven models in resource-poor areas.
#However, in the field of code modeling, the potential of this approach has not yet been fully exploited. Code modeling is an emerging field at the intersection of machine learning and software engineering, involving the application of machine learning techniques to solve a variety of coding tasks, such as code completion, code summarization, and defect detection. The multimodal nature of code data (programming language and natural language) poses unique challenges for customizing data augmentation methods. Jointly released by industry agencies. It not only reveals code data enhancement techniques in depth, but also provides guidance for future research and applications. We believe that this review will inspire more researchers to become interested in the application of code data augmentation in deep learning and promote further exploration and development in this field
Background Introduction
The rise and development of code models
: Code models are trained based on a large number of source code corpora and can accurately simulate the context of code snippets. From the early adoption of deep learning architectures such as LSTM and Seq2Seq to the later incorporation of pre-trained language models, these models have shown excellent performance in downstream tasks across multiple sources. For example, some models take into account the data flow of the program during the pre-training stage, which is the semantic level structure of the code and is used to capture the relationship between variables. The significance of data enhancement technology
: Data enhancement technology increases the diversity of training samples through data synthesis, thereby improving the model in all aspects (such as accuracy and robustness) performance. In the field of computer vision, for example, commonly used data augmentation methods include image cropping, flipping, and color adjustment. In natural language processing, data augmentation relies heavily on language models that can rewrite context by replacing words or rewriting sentences. Speciality of code data enhancement
: Unlike images and plain text, source code is restricted by the strict syntax rules of the programming language, so Enhanced flexibility is low. Most data augmentation methods for code must adhere to specific transformation rules to maintain the functionality and syntax of the original code snippet. A common practice is to use a parser to build a concrete syntax tree of the source code and then convert it into an abstract syntax tree, simplifying the representation while retaining key information such as identifiers and control flow statements. These transformations are the basis of rule-based data augmentation methods, and they help simulate more diverse code representations in the real world, improving the robustness of code models trained with augmented data. In-depth exploration of code data enhancement methods
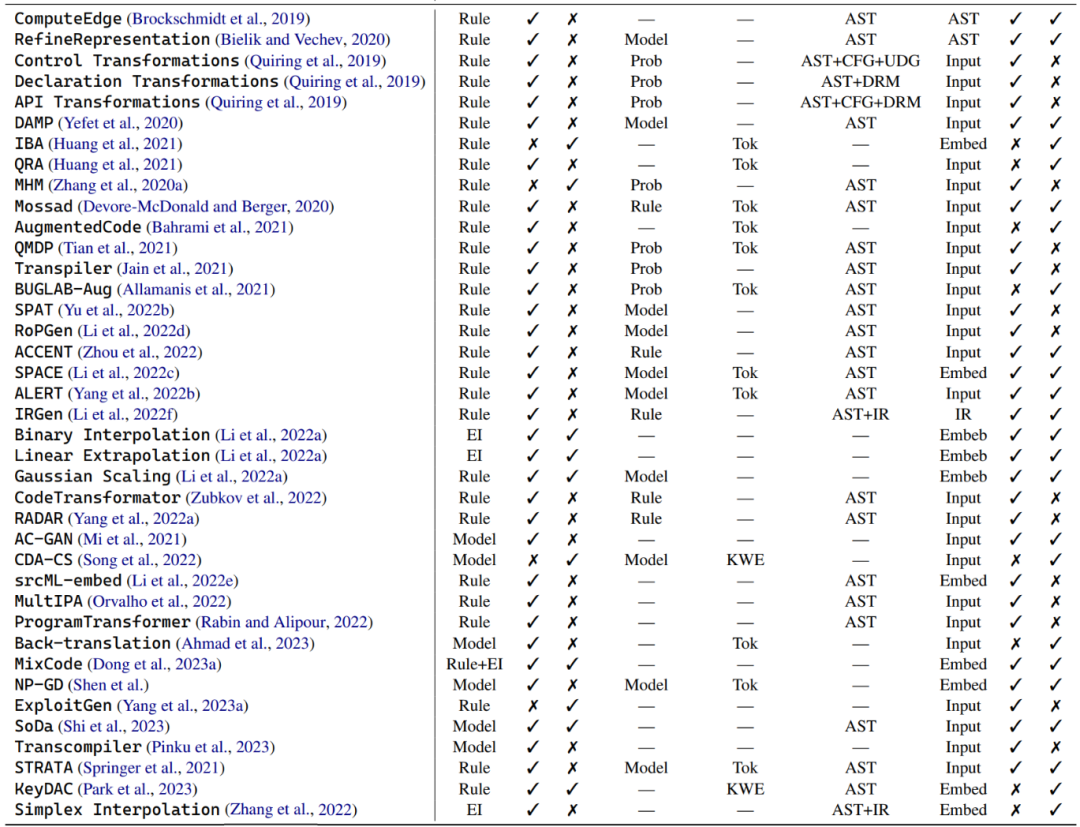
In an in-depth exploration of the world of code data enhancement, the author divides these technologies into three main categories : Rule-based techniques, model-based techniques, and example interpolation techniques. These different branches are briefly described below.
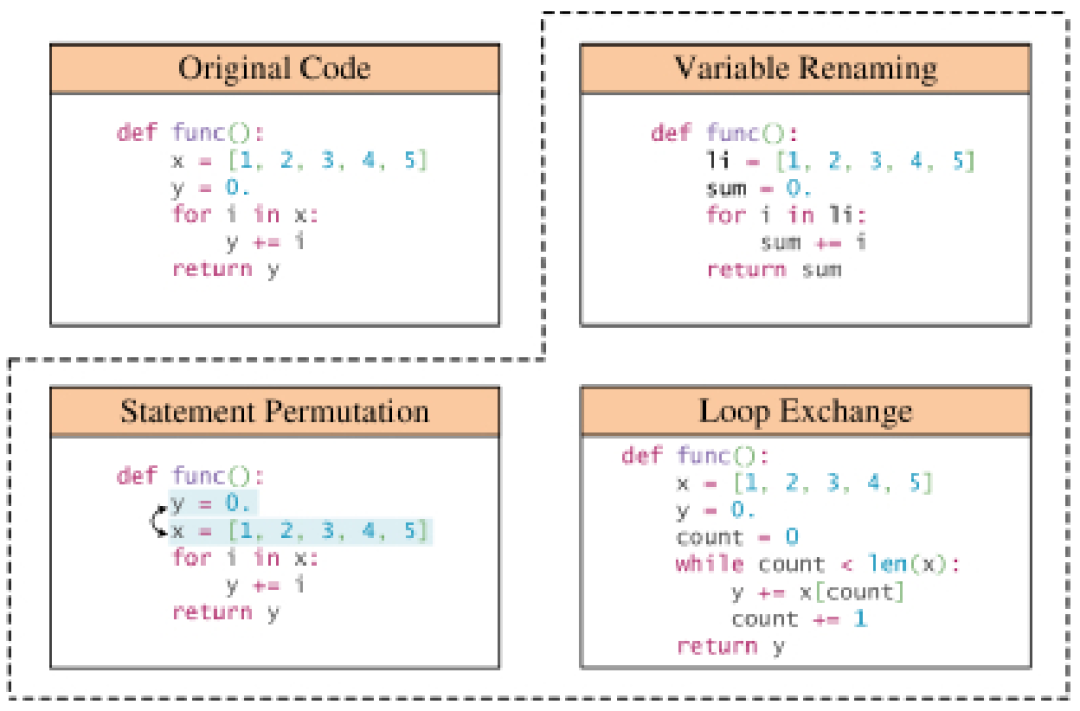
Rule-based technology: Many data enhancement methods utilize predetermined rules to transform programs while ensuring that syntax rules and semantics are not violated. These transformations include operations such as replacing variable names, renaming method names, and inserting invalid code. In addition to basic program syntax, some transformations also consider deeper structural information, such as control flow graphs and use-definition chains. There is a subset of rule-based data enhancement techniques that focus on enhancing the natural language context in code snippets, including docstrings and comments.
Model-based techniques : A series of data augmentation techniques for code models designed to train Various models to enhance data. For example, some studies utilize Auxiliary Classification Generative Adversarial Networks (ACGAN) to generate augmentations. Other studies have trained generative adversarial networks to improve both code generation and code search capabilities. These methods are mainly designed specifically for code models and aim to enhance the representation and context understanding of code in different ways.
Example Interpolation Technique: This type of data augmentation technique originates from Mixup, which interpolates the input and the values of two or more actual samples. label to operate. For example, given a binary classification task in computer vision and two images of a dog and a cat, these data augmentation methods can blend the inputs of the two images and their corresponding labels together according to randomly selected weights. However, in the code world, the application of these methods is limited by unique program syntax and functionality. Compared to surface-level interpolation, most example interpolation data augmentation methods fuse multiple real examples into a single input through model embedding. For example, there is research on combining rule-based techniques with Mixup to mix original code snippets and their transformed representations.

Strategy and Technology
In practical applications, the design and effectiveness of data augmentation techniques for code models are affected by multiple factors, such as computational cost, sample diversity, and model robustness. This section highlights these factors, providing insights and tips for designing and optimizing suitable data augmentation methods.
Method Stacking: In the previous discussion, many data augmentation strategies were proposed simultaneously in a single work with the purpose of enhancing the model performance. Typically, this combination includes two types: the same type of data augmentation or a mixture of different data augmentation methods. The former is usually applied to rule-based data augmentation techniques, where the starting point is that a single code transformation cannot fully represent the diverse coding styles and implementations in the real world. Several works have demonstrated that fusing multiple types of data augmentation techniques can enhance the performance of code models. For example, a rule-based transcoding scheme and model-based data augmentation are combined to create an enhanced corpus for model training. While other research is enhanced on programming languages, including two data enhancement techniques: rule-based non-keyword extraction and model-based non-keyword replacement.
Optimization: In certain scenarios, such as enhancing robustness and minimizing computational cost, select specific enhanced sample candidates to It's important. The authors refer to this goal-directed candidate selection as optimization in data augmentation. The article mainly introduces three strategies: probabilistic selection, model-based selection and rule-based selection. Probabilistic selection optimizes by sampling from a probability distribution, while model-based selection is guided by the model in selecting the most appropriate examples. In rule-based selection, specific predetermined rules or heuristics are used to select the most appropriate examples.
Probabilistic selection: The author specifically selected three representative probabilistic selection strategies, including MHM, QMDP and BUGLAB-Aug . MHM employs the Metropolis-Hastings probabilistic sampling method, a Markov Chain Monte Carlo technique for selecting adversarial examples with identifier replacement. QMDP uses Q-learning methods to strategically select and execute rule-based structural transformations.
Model-based selection: Some data augmentation techniques that adopt this strategy use the gradient information of the model to guide the selection of enhancement examples. A typical method is the data augmentation MP method, which optimizes based on the model loss, selects and generates adversarial examples through variable renaming. SPACE selects and perturbs embeddings of code identifiers via gradient ascent, with the goal of maximizing the performance impact of the model while maintaining the semantic and syntactic correctness of the programming language.
Rule-based selection : Rule-based selection is a powerful method that uses predetermined fitness functions or rules. This approach often relies on decision indicators. For example, IRGen uses a genetic algorithm-based optimization technique and a fitness function based on IR similarity. While ACCENT and RA data augmentation R use evaluation metrics such as BLEU and CodeBLEU respectively to guide the selection and replacement process to achieve maximum adversarial impact.
Application scenarios
The data enhancement method can be directly applied to several common code scenarios
Adversarial Examples for Robustness: Robustness is a critical and complex dimension in software engineering. Designing effective data augmentation techniques to generate adversarial examples to identify and mitigate vulnerabilities in code models has become a research hotspot in recent years. Multiple studies have further strengthened the robustness of the code model by testing and enhancing the robustness of the model using various data augmentation methods.
Low resource areas: In the field of software engineering, programming language resources are seriously imbalanced. Popular programming languages like Python and Java play major roles in open source repositories, while many languages like Rust are very resource-poor. Code models are often trained based on open source repositories and forums, and imbalances in programming language resources may adversely affect their performance on resource-starved programming languages. Applying data augmentation methods in low-resource domains is a recurring theme.
Retrieval enhancement: In the field of natural language processing and coding, the data enhancement application of retrieval enhancement has attracted more and more attention. These retrieval enhancement frameworks for code models incorporate retrieval enhancement examples from the training set when pre-training or fine-tuning the code model. This enhancement method improves the parameter efficiency of the model.
Contrastive learning: Contrastive learning is another application area where data augmentation methods are deployed in code scenarios. It enables the model to learn an embedding space in which similar samples are close to each other and dissimilar samples are further apart. Data augmentation methods are used to construct samples that are similar to positive samples to improve model performance in tasks such as defect detection, clone detection, and code search.
The following articles discuss several common coding tasks and the application of data augmentation work on the evaluation data set, including clone detection, defect detection and repair, code summarization, code Search, code generation and code translation
Challenges and opportunities
In terms of code data enhancement, the author believes that there are many significant challenges. However, it is these challenges that bring new possibilities and exciting opportunities to the field
Theoretical Discussion: Currently , there is a clear gap in the in-depth exploration and theoretical understanding of data augmentation methods in code. Most existing research focuses on the fields of image processing and natural language, viewing data augmentation as a method to apply pre-existing knowledge about data or task invariance. When turning to code, while previous work introduced new methods or demonstrated how data augmentation techniques can be effective, they often overlooked the why and how, especially from a mathematical perspective. The discrete nature of the code makes theoretical discussions even more important. Theoretical discussions enable everyone to understand data augmentation from a broader perspective than just in terms of experimental results.
More research on pre-trained models: In recent years, pre-trained code models have been widely used in the code field. Self-supervision of large-scale corpora has accumulated a wealth of knowledge. Although many studies have utilized pre-trained code models for data augmentation, most attempts are still limited to mask token replacement or direct generation after fine-tuning. Exploiting the data augmentation potential of large-scale language models is an emerging research opportunity in the coding world.
Different from the previous way of using pre-trained models in data enhancement, these works have opened the era of "hint-based data enhancement". However, hint-based data augmentation exploration remains a relatively untouched area of research in the code world. Rewritten content: Different from the previous way of using pre-trained models in data enhancement, these works usher in the era of "hint-based data enhancement". However, there is still relatively little research on hint-based data augmentation in the coding domain
Processing domain-specific data: Author focused survey Data augmentation techniques for common downstream tasks in your code. However, the authors realize that there is still a small amount of research on other task-specific data in the coding domain. For example, API recommendation and API sequence generation can be considered part of the coding tasks. The authors observed a gap in data augmentation techniques between these two different levels, providing opportunities for future work to explore.
More exploration of project-level code and low-resource programming languages: Existing approaches in terms of function-level code snippets and common programming languages Sufficient progress has been made. At the same time, enhancement methods for low-resource languages, although in greater demand, are relatively scarce. Exploration in these two directions is still limited, and the authors believe that they may be promising directions.
mitigating social bias: As code models advance in software development, they may be used to develop human-centered applications Programs, such as human resources and education, where biased procedures can lead to unfair and unethical decisions for underrepresented populations. While social bias in NLP has been well studied and can be mitigated through data augmentation, social bias in code has not yet received attention.
Small sample learning: In a small sample scenario, the model needs to achieve performance comparable to traditional machine learning models, but the training data Extremely limited. Data augmentation methods provide a straightforward solution to this problem. However, there is limited work on employing data augmentation methods in small sample scenarios. In a few sample scenarios, the author feels that this is an interesting question how to provide the model with rapid generalization and problem-solving capabilities by generating high-quality augmented data.
Multimodal Applications: It is important to note that focusing only on function-level code snippets does not accurately represent real-world programming situations of complexity and nuance. In this case, developers usually work on multiple files and folders at the same time. Although these multimodal applications are becoming increasingly popular, no research has applied data augmentation methods to them. One of the challenges is to effectively bridge the embedding representations of each modality in code models, which has been studied in visual-verbal multimodal tasks.
Lack of Uniformity: The current code data augmentation literature presents a challenging landscape in which the most popular approaches are often characterized For auxiliary. Some empirical studies have attempted to compare data augmentation methods for code models. However, these works do not exploit most existing advanced data augmentation methods. While well-established data augmentation frameworks exist for computer vision (such as the default augmentation library in PyTorch) and NLP (such as NL-Augmenter), corresponding libraries for general-purpose data augmentation techniques for code models are conspicuously missing. Furthermore, since existing data augmentation methods are often evaluated using various datasets, it is difficult to determine their effectiveness. Therefore, the authors believe that the progress of data augmentation research will be greatly promoted by establishing standardized and unified benchmark tasks, as well as datasets for comparing and evaluating the effectiveness of different augmentation methods. This will pave the way for a more systematic and comparative understanding of the strengths and limitations of these methods.
The above is the detailed content of Code Data Augmentation in Deep Learning: A Review of 89 Researches in 5 Years. For more information, please follow other related articles on the PHP Chinese website!