

 Technology peripheralsAIIn-depth discussion on the application of multi-modal fusion perception algorithm in autonomous driving
Technology peripheralsAIIn-depth discussion on the application of multi-modal fusion perception algorithm in autonomous drivingIn-depth discussion on the application of multi-modal fusion perception algorithm in autonomous driving

Please contact the source to obtain permission to reprint this article. This article was published by the Autonomous Driving Heart public account
1 Introduction
More Modal sensor fusion means complementary, stable and safe information, and has long been an important part of autonomous driving perception. However, insufficient information utilization, noise in the original data, and misalignment between various sensors (such as out-of-synchronization of timestamps) have all resulted in limited fusion performance. This article comprehensively surveys existing multi-modal autonomous driving perception algorithms. Sensors include LiDAR and cameras, focusing on target detection and semantic segmentation, and analyzes more than 50 documents. Different from the traditional classification method of fusion algorithms, this paper classifies this field into two major categories and four sub-categories based on the different fusion stages. In addition, this article analyzes existing problems in the current field and provides reference for future research directions.
2 Why is multimodality needed?
This is because the single-modal perception algorithm has inherent flaws. For example, lidar is generally installed higher than the camera. In complex real-life driving scenarios, objects may be blocked in the front-view camera. In this case, it is possible to use lidar to capture the missing target. However, due to the limitations of the mechanical structure, LiDAR has different resolutions at different distances and is easily affected by extremely severe weather, such as heavy rain. Although both sensors can do very well when used alone, from a future perspective, the complementary information of LiDAR and cameras will make autonomous driving safer at the perception level.
Recently, multi-modal perception algorithms for autonomous driving have made great progress. These advances include cross-modal feature representation, more reliable modal sensors, and more complex and stable multi-modal fusion algorithms and techniques. However, only a few reviews [15, 81] focus on the methodology itself of multimodal fusion, and most of the literature is classified according to traditional classification rules, namely pre-fusion, deep (feature) fusion and post-fusion, and mainly focuses on The stage of feature fusion in the algorithm, whether it is data level, feature level or proposal level. There are two problems with this classification rule: first, the feature representation of each level is not clearly defined; second, it treats the two branches of lidar and camera from a symmetrical perspective, thus blurring the relationship between feature fusion and feature fusion in the LiDAR branch. The case of data-level feature fusion in the camera branch. In summary, although the traditional classification method is intuitive, it is no longer suitable for the development of current multi-modal fusion algorithms, which to a certain extent hinders researchers from conducting research and analysis from a systematic perspective
3 tasks And open competition
Common perception tasks include target detection, semantic segmentation, depth completion and prediction, etc. This article focuses on detection and segmentation, such as the detection of obstacles, traffic lights, traffic signs, and segmentation of lane lines and freespace. The autonomous driving perception task is shown in the figure below:

Common public data sets mainly include KITTI, Waymo and nuScenes. The following figure summarizes the data sets related to autonomous driving perception and their Features
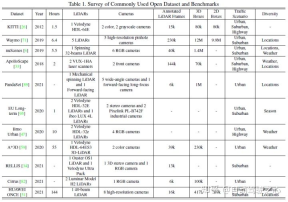
4 Fusion method
Multimodal fusion is inseparable from the data expression form. The data representation of the image branch is relatively simple. Generally speaking, it refers to RGB format or grayscale image, but the lidar branch is highly dependent on data format. Different data formats derive completely different downstream model designs. In summary, it includes three general directions: point-based, volume-based. Voxel and point cloud representation based on 2D mapping.
Traditional classification methods divide multi-modal fusion into the following three types:
- Pre-fusion (data-level fusion) refers to the direct fusion of raw sensor data of different modalities through spatial alignment.
- Deep fusion (feature-level fusion) refers to the fusion of cross-modal data in feature space through cascade or element multiplication.
- Post-fusion (target-level fusion) refers to fusing the prediction results of each modal model to make the final decision.
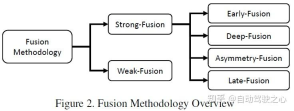
The article uses the classification method in the figure below, which is generally divided into strong fusion and weak fusion. Strong fusion can be subdivided into front fusion, deep fusion, asymmetric fusion and post-fusion
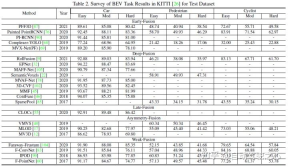
This article uses KITTI’s 3D detection task and BEV detection task to horizontally compare the performance of various multi-modal fusion algorithms. The following figure is the result of the BEV detection test set:
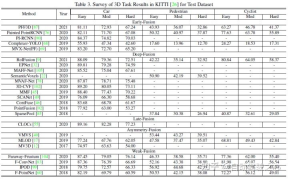
The following is an example of the results of the 3D detection test set:
5 Strong fusion
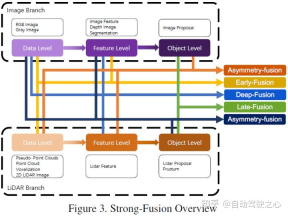
According to the different combination stages represented by lidar and camera data, this article subdivides strong fusion into: pre-fusion, Deep fusion, asymmetric fusion and post-fusion. As shown in the figure above, it can be seen that each sub-module of strong fusion is highly dependent on lidar point cloud rather than camera data.
Pre-fusion
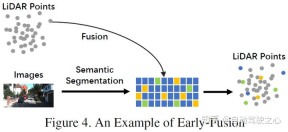
Different from the traditional data-level fusion definition, the latter is a direct fusion of each modality data at the original data level through spatial alignment and projection In this approach, early fusion fuses LiDAR data at the data level and camera data at the data level or at the feature level. An example of early fusion could be the model in Figure 4. Rewritten content: Different from the traditional data-level fusion definition, which is a method to directly fuse each modality data through spatial alignment and projection at the original data level. Early fusion refers to the fusion of LiDAR data and camera data or feature-level data at the data level. The model in Figure 4 is an example of early fusion
Different from the pre-fusion defined by traditional classification methods, the pre-fusion defined in this article refers to the direct fusion of each modal data through spatial alignment and projection at the original data level. Method, the former fusion refers to the fusion of LiDAR data at the data level, and the fusion of image data at the data level or feature level. The schematic diagram is as follows:
In the LiDAR branch, point cloud There are many expression methods, such as reflection map, voxelized tensor, front view/distance view/BEV view, pseudo point cloud, etc. Although these data have different intrinsic characteristics in different backbone networks, except for pseudo point clouds [79], most of the data are generated through certain rule processing. In addition, compared with feature space embedding, these LiDAR data are highly interpretable and can be directly visualized. In the image branch, the data-level definition in the strict sense refers to RGB or gray image, but this definition lacks universality and rationality. Therefore, this paper expands the data-level definition of image data in the pre-fusion stage to include data-level and feature-level data. It is worth mentioning that this article also regards the prediction results of semantic segmentation as a type of pre-fusion (image feature level). On the one hand, it is helpful for 3D target detection, and on the other hand, it is because of the "target level" of semantic segmentation. Features are different from the final target-level proposal of the entire task
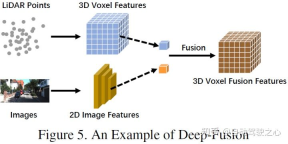
Deep FusionDeep fusion, also called feature-level fusion, refers to the feature level in the lidar branch Fuse multimodal data, but at the dataset and feature level of the image branch. For example, some methods use feature lifting to obtain embedding representations of LiDAR point clouds and images respectively, and fuse the features of the two modalities through a series of downstream modules. However, unlike other strong fusions, deep fusion sometimes fuses features in a cascade manner, both of which exploit raw and high-level semantic information. The schematic diagram is as follows:
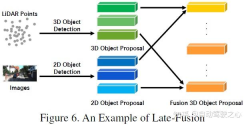
Post-fusion, which can also be called target-level fusion, refers to the processing of multiple modalities. The prediction results (or proposals) are fused. For example, some post-fusion methods utilize the output of LiDAR point clouds and images for fusion [55]. The proposal data format for both branches should be consistent with the final results, but there may be differences in quality, quantity, and accuracy. Post-fusion can be seen as an integration method for multi-modal information optimization of the final proposal. The schematic diagram is as follows:
The last type of strong fusion is asymmetric fusion, which refers to the fusion of target-level information of one branch and data-level or feature-level information of other branches. The above three fusion methods treat each branch of multi-modality equally, while asymmetric fusion emphasizes that at least one branch is dominant, and other branches provide auxiliary information to predict the final result. The figure below is a schematic diagram of asymmetric fusion. In the proposal stage, asymmetric fusion only has the proposal of one branch, and then the fusion is the proposal of all branches.
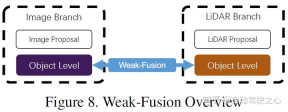
6 The difference between weak fusion
and strong fusion is that the weak fusion method does not directly fuse data, features or targets from multi-modal branches, but processes the data in other forms . The figure below shows the basic framework of the weak fusion algorithm. Methods based on weak fusion usually use certain rule-based methods to utilize data from one modality as a supervision signal to guide the interaction of another modality. For example, the 2D proposal from CNN in the image branch may cause truncation in the original LiDAR point cloud, and weak fusion directly inputs the original LiDAR point cloud into the LiDAR backbone to output the final proposal.
7 Other methods of integration
There are also some works that do not belong to any of the above paradigms because they are within the framework of model design A variety of fusion methods are used in [39], which combines deep fusion and post-fusion, and [77] combines front-front fusion. These methods are not the mainstream methods of fusion algorithm design, and are classified into other fusion methods in this article.
8 Opportunities of multi-modal fusion
In recent years, multi-modal fusion methods for autonomous driving perception tasks have made rapid progress, starting from higher-level features representation to more complex deep learning models. However, there are still some outstanding issues that need to be resolved. This article summarizes several possible future improvement directions as follows.
More advanced fusion methods
The current fusion model has problems of misalignment and information loss [13, 67, 98]. In addition, flat fusion operations also hinder further improvements in perceptual task performance. The summary is as follows:
- Misalignment and information loss: The internal and external differences between cameras and LiDAR are very large, and the data of the two modes need to be coordinate aligned. Traditional front-fusion and depth-fusion methods utilize calibration information to project all LiDAR points directly into the camera coordinate system and vice versa. However, due to the installation location and sensor noise, this pixel-by-pixel alignment is not accurate enough. Therefore, some works utilize surrounding information to supplement it to obtain better performance. In addition, some other information is lost during the conversion process of input and feature spaces. Usually, the projection of dimensionality reduction operations inevitably leads to a large amount of information loss, such as the loss of height information in mapping 3D LiDAR point clouds to 2D BEV images. Therefore, you can consider mapping multi-modal data to another high-dimensional space designed for fusion, so as to effectively utilize the original data and reduce information loss.
- More reasonable fusion operations: Many current methods use cascade or element multiplication for fusion. These simple operations may fail to fuse data with widely different distributions, making it difficult to fit semantic red dogs between the two modalities. Some works attempt to use more complex cascade structures to fuse data and improve performance. In future research, mechanisms such as bilinear mapping can fuse features with different characteristics and are also directions that can be considered.
Multi-source information utilization
The forward-looking single-frame image is a typical scenario for autonomous driving perception tasks. However, most frameworks can only utilize limited information and do not design auxiliary tasks in detail to facilitate the understanding of driving scenarios. The summary is as follows:
- Use more potential information: Existing methods lack the effective use of information from multiple dimensions and sources. Most focus on single-frame multi-modal data in the front view. This results in other meaningful data being underutilized, such as semantic, spatial and scene context information. Some works attempt to use semantic segmentation results to assist the task, while other models potentially exploit intermediate layer features of the CNN backbone. In autonomous driving scenarios, many downstream tasks with explicit semantic information may greatly improve object detection performance, such as the detection of lane lines, traffic lights, and traffic signs. Future research can combine downstream tasks to jointly build a complete semantic understanding framework for urban scenes to improve perception performance. Furthermore, [63] incorporates inter-frame information to improve performance. Time series information contains serialized monitoring signals, which can provide more stable results compared to single-frame methods. Therefore, future work could consider more deeply exploiting temporal, contextual, and spatial information to achieve performance breakthroughs.
- Self-supervised representation learning: Mutually supervised signals naturally exist in cross-modal data sampled from the same real-world scene but from different angles. However, due to the lack of in-depth understanding of the data, current methods are unable to mine the interrelationships between various modalities. Future research can focus on how to use multi-modal data for self-supervised learning, including pre-training, fine-tuning or contrastive learning. Through these state-of-the-art mechanisms, fusion algorithms will deepen the model's deeper understanding of the data while achieving better performance.
Inherent Sensor Issues
Real-world scenarios and sensor height can affect domain bias and resolution. These shortcomings will hinder the large-scale training and real-time operation of deep learning models for autonomous driving
- Domain bias: In autonomous driving perception scenarios, the raw data extracted by different sensors are accompanied by severe domain-related features. Different cameras have different optical properties, and LiDAR can vary from mechanical to solid-state structures. What's more, the data itself will have domain biases, such as weather, season, or geographic location, even if it was captured by the same sensor. This causes the generalization of the detection model to be affected and cannot effectively adapt to new scenarios. Such flaws hinder the collection of large-scale datasets and the reusability of original training data. Therefore, the future can focus on finding a method to eliminate domain bias and adaptively integrate different data sources.
- Resolution Conflict: Different sensors usually have different resolutions. For example, the spatial density of LiDAR is significantly lower than that of images. No matter which projection method is used, information loss will occur because the corresponding relationship cannot be found. This may result in the model being dominated by data from one specific modality, whether due to different resolutions of the feature vectors or an imbalance in the raw information. Therefore, future work could explore a new data representation system compatible with sensors of different spatial resolutions.
9Reference
[1] https://zhuanlan.zhihu.com/p/470588787
[2] Multi-modal Sensor Fusion for Auto Driving Perception: A Survey

Original link: https://mp.weixin.qq.com/s/usAQRL18vww9YwMXRvEwLw
The above is the detailed content of In-depth discussion on the application of multi-modal fusion perception algorithm in autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Notepad++7.3.1
Easy-to-use and free code editor

WebStorm Mac version
Useful JavaScript development tools

Dreamweaver Mac version
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

