
 Technology peripheralsAIAmazon Cloud Technology vector database preview version now on sale, high performance helps accelerate AI applications
Technology peripheralsAIAmazon Cloud Technology vector database preview version now on sale, high performance helps accelerate AI applicationsAmazon Cloud Technology vector database preview version now on sale, high performance helps accelerate AI applications

Amazon Cloud Technology launched seven generative AI innovation projects at the New York Summit held on July 26, 2023, which further lowered the threshold for using generative AI, allowing enterprises to focus more on core business and improve production efficiency. One of the eye-catching projects is Amazon Cloud Technology’s upcoming vector database-related innovations. They have released a preview version of Amazon Cloud Technology’s vector engine

Recently, Amazon Cloud Technology released a preview version of the Amazon OpenSearch Serverless vector engine. This release marks a major advancement in cloud search services, providing users with simple, high-performance and scalable similarity search capabilities
In February 2023, Amazon Cloud Technology has been rated as the leader in cloud database management systems by Gartner for eight consecutive years. This honor is not accidental, but a full affirmation of Amazon Cloud Technology's unremitting pursuit of technological innovation and excellence.
So, what is the performance of the preview version of Amazon Cloud Technology's vector engine? Can it afford the public’s expectations of it?
We all know that in this era, generative AI is being rapidly adopted by various industries because it can process big data, automate content generation and provide human-like interactive responses. AI applications such as integrated chatbots, question-and-answer systems, and personalized recommendations use natural language search and query to understand semantics, user intent, and generate anthropomorphic responses, which have revolutionized user experience and digital platform interaction.
Machine learning search and generative AI applications require the use of vector embeddings to represent digital forms of text, images, audio and video to generate dynamic content. These embeddings are trained on user data to express the semantics and context of the information. This process does not need to rely on external data sources or applications. Users hope that the vector database can be easily built and quickly moved from prototype to production environment so that they can focus on differentiated applications

The Amazon OpenSearch Serverless vector engine was launched based on these changes in needs. It extends the search capabilities of Amazon OpenSearch and can store, search, and trace billions of vector embeddings in real time to achieve similarity matching and semantic search. No need to consider infrastructure issues
Therefore, its performance can be roughly summarized as the following characteristics:
The rewritten content is: First, the Amazon OpenSearch Serverless vector engine trial version is naturally robust. Users don’t need to worry about back-end infrastructure selection, optimization, and scaling. The engine automatically adjusts resources to adapt to changing workloads and demands, ensuring fast performance and right scale at all times. Whether the number of vectors increases from thousands to hundreds of millions, the engine can scale seamlessly without reindexing or reloading data, making infrastructure expansion more convenient
Rewritten content: Second, independent computing resources. The vector engine provides independent computing resources for indexing and workload search, enabling seamless acquisition, update, and deletion of vectors in real time, ensuring that user query performance is not affected. Data is stored long-term in Amazon S3 with the same data durability guarantees. Although in preview, the engine is designed for production environments and has redundancy mechanisms to deal with outages and failures
Third, the results provided are accurate and reliable. Customers use OpenSearch kNN search in managed clusters to implement semantic search and personalized recommendations for applications. The vector engine provides the same user experience as the Serverless environment and is simple and easy to use. Amazon OpenSearch serverless vector engine is based on the k-nearest neighbor (kNN) search function of the OpenSearch project. It supports distance indicators such as Euclidean distance, cosine distance, and dot product. It can accommodate 16,000 dimensions and is suitable for various basic models and AI/ML models. Can provide users with accurate and reliable search results

Amazon Cloud Technology plans to launch two features to reduce first-time collection costs for customers. In addition to the great performance mentioned above, first of all, they will launch a new dev-test option that allows users to launch collections without backups or replicas, thereby reducing the cost of entry by 50%. Data durability is still ensured via the vector engine saved in Amazon S3. Secondly, they will also provide an initial phase configuration of 0.5 OCU resources, which can be expanded based on actual workload needs to further reduce costs. This feature works with tens to hundreds of thousands of vectors (depending on the dimensions). In addition, Amazon Cloud Technology has lowered the minimum required OCU from 4 per hour to 1 per hour to provide more support
Amazon Cloud Technology’s ambitions certainly don’t stop there. They are also continuing to work hard to optimize the performance and memory usage of vector graphics, including improving functions such as caching and merging
In the near future, we look forward to Amazon Cloud Technology officially launching the OpenSearch Serverless vector engine. By then, generative AI may enter a whole new field
The above is the detailed content of Amazon Cloud Technology vector database preview version now on sale, high performance helps accelerate AI applications. For more information, please follow other related articles on the PHP Chinese website!

 An AI Space Company Is BornMay 12, 2025 am 11:07 AM
An AI Space Company Is BornMay 12, 2025 am 11:07 AMThis article showcases how AI is revolutionizing the space industry, using Tomorrow.io as a prime example. Unlike established space companies like SpaceX, which weren't built with AI at their core, Tomorrow.io is an AI-native company. Let's explore
 10 Machine Learning Internships in India (2025)May 12, 2025 am 10:47 AM
10 Machine Learning Internships in India (2025)May 12, 2025 am 10:47 AMLand Your Dream Machine Learning Internship in India (2025)! For students and early-career professionals, a machine learning internship is the perfect launchpad for a rewarding career. Indian companies across diverse sectors – from cutting-edge GenA
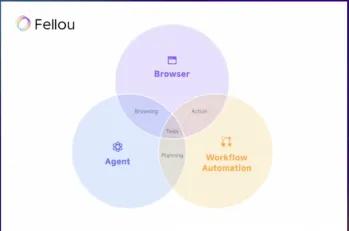 Try Fellou AI and Say Goodbye to Google and ChatGPTMay 12, 2025 am 10:26 AM
Try Fellou AI and Say Goodbye to Google and ChatGPTMay 12, 2025 am 10:26 AMThe landscape of online browsing has undergone a significant transformation in the past year. This shift began with enhanced, personalized search results from platforms like Perplexity and Copilot, and accelerated with ChatGPT's integration of web s
 Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AM
Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AMCyberattacks are evolving. Gone are the days of generic phishing emails. The future of cybercrime is hyper-personalized, leveraging readily available online data and AI to craft highly targeted attacks. Imagine a scammer who knows your job, your f
 Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AM
Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AMIn his inaugural address to the College of Cardinals, Chicago-born Robert Francis Prevost, the newly elected Pope Leo XIV, discussed the influence of his namesake, Pope Leo XIII, whose papacy (1878-1903) coincided with the dawn of the automobile and
 FastAPI-MCP Tutorial for Beginners and Experts - Analytics VidhyaMay 11, 2025 am 10:56 AM
FastAPI-MCP Tutorial for Beginners and Experts - Analytics VidhyaMay 11, 2025 am 10:56 AMThis tutorial demonstrates how to integrate your Large Language Model (LLM) with external tools using the Model Context Protocol (MCP) and FastAPI. We'll build a simple web application using FastAPI and convert it into an MCP server, enabling your L
 Dia-1.6B TTS : Best Text-to-Dialogue Generation Model - Analytics VidhyaMay 11, 2025 am 10:27 AM
Dia-1.6B TTS : Best Text-to-Dialogue Generation Model - Analytics VidhyaMay 11, 2025 am 10:27 AMExplore Dia-1.6B: A groundbreaking text-to-speech model developed by two undergraduates with zero funding! This 1.6 billion parameter model generates remarkably realistic speech, including nonverbal cues like laughter and sneezes. This article guide
 3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AM
3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AMI wholeheartedly agree. My success is inextricably linked to the guidance of my mentors. Their insights, particularly regarding business management, formed the bedrock of my beliefs and practices. This experience underscores my commitment to mentor


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Atom editor mac version download
The most popular open source editor

