
 DatabaseMysql TutorialHow to realize MySQL underlying optimization: application and optimization of data statistics and analysis
DatabaseMysql TutorialHow to realize MySQL underlying optimization: application and optimization of data statistics and analysis

How to realize MySQL underlying optimization: application and optimization of data statistics and analysis
With the rapid development of the Internet, the importance of data to enterprises has become more and more prominent. As a commonly used open source relational database management system, MySQL's underlying optimization is crucial to the performance of data statistics and analysis applications. This article will focus on how to implement MySQL underlying optimization to improve the efficiency of data statistics and analysis applications.
1. Index optimization
1.1 Creating appropriate indexes
Indexes are the key to improving MySQL query performance. When performing data statistics and analysis, we often need to perform complex query operations, so appropriate index design is particularly important. By analyzing query statements, determining the most commonly used query conditions and sorting fields, and creating indexes for these fields, query efficiency can be greatly improved.
For example, if we often query and sort a table named "users" according to the "age" field, we can use the following SQL statement to create an index:
CREATE INDEX age_index ON users (age);
1.2 Remove redundant indexes
Although indexes can improve query performance, too many indexes will occupy additional storage space and increase the cost of write operations. Therefore, when performing index optimization, redundant indexes also need to be removed.
By querying the MySQL system table "information_schema.statistics", we can obtain the index information of each table. Determine whether there are redundant indexes based on the number of queries and updates. If an index is rarely used or updated, consider removing it.
For example, we can use the following SQL statement to find out unused indexes:
SELECT *
FROM information_schema.statistics
WHERE table_schema = 'your_database_name'
AND index_name NOT IN (SELECT index_name
FROM information_schema.query_statistics)
ORDER BY table_name, index_name;2. Query optimization
2.1 Avoid full table scan
Full table scan is a less efficient query method, and its performance is particularly obvious when the amount of data is large. When performing data statistics and analysis, full table scans should be avoided as much as possible.
By analyzing query conditions and sorting fields, use appropriate indexes or use covering indexes (Covering Index) to improve query efficiency. A covering index is a special index that contains all the required fields and can improve query performance by avoiding access to the main index or data rows.
For example, we often need to count the number of user logins within a certain period of time. You can use the following SQL statement:
SELECT COUNT(*) AS login_count FROM users WHERE login_time BETWEEN '2022-01-01' AND '2022-03-31';
In order to optimize this query, you can create an index for the "login_time" field. And use the following SQL statement:
SELECT COUNT(*) AS login_count FROM users WHERE login_time BETWEEN '2022-01-01' AND '2022-03-31' AND other_columns...; -- 这里的"other_columns"表示需要参与覆盖索引的其他字段
2.2 Use LIMIT to limit the result set
When performing data statistics and analysis, it is usually necessary to obtain only part of the data rather than all the data. In order to reduce the burden on the database, you can use the LIMIT keyword to limit the size of the result set.
For example, if we need to obtain the information of the 10 recently registered users, we can use the following SQL statement:
SELECT * FROM users ORDER BY register_time DESC LIMIT 10;
Using LIMIT can avoid unnecessary data transmission and improve query performance.
3. Concurrency optimization
3.1 Reasonably set the number of concurrent connections
The number of concurrent connections refers to the number of clients connected to the MySQL database at the same time. Excessive number of concurrent connections It will increase the load on the database system and reduce performance.
According to the system's hardware configuration and database size, set the number of concurrent connections reasonably to avoid the impact of too many connections on the system.
3.2 Use transaction management
When performing data statistics and analysis, there are often a large number of read and write operations. Failure to use transaction management may result in data inconsistency or loss.
Using transactions can process multiple operations as a unit, ensuring data consistency and improving concurrent processing capabilities.
For example, when we update user points, we need to record the user's point change history. You can use the following SQL statement:
START TRANSACTION; UPDATE users SET points = points + 100 WHERE user_id = 1; INSERT INTO points_history (user_id, points_change) VALUES (1, 100); COMMIT;
4. Application and optimization examples of data statistics and analysis
Suppose we have a table named "order" to store the user's order information. We need to count the number of orders for each user and sort them according to the order quantity. You can use the following SQL statement for optimization:
SELECT user_id, COUNT(*) AS order_count FROM orders GROUP BY user_id ORDER BY order_count DESC LIMIT 10;
In order to improve the performance of this query, you can create an index for the "user_id" field and use a covering index, as shown below:
CREATE INDEX user_id_index ON orders (user_id); SELECT user_id, COUNT(*) AS order_count FROM orders USE INDEX (user_id_index) GROUP BY user_id ORDER BY order_count DESC LIMIT 10;
Through optimization Indexes and query statements can improve the performance and efficiency of data statistics and analysis applications.
To sum up, through methods such as index optimization, query optimization and concurrency optimization, the underlying optimization of MySQL can be achieved and the efficiency of data statistics and analysis applications can be improved. For large-scale data processing, more specific optimization methods need to be adjusted according to specific business needs and data conditions. I hope the content of this article will be helpful to readers.
The above is the detailed content of How to realize MySQL underlying optimization: application and optimization of data statistics and analysis. For more information, please follow other related articles on the PHP Chinese website!

 一文详解Python数据分析模块Numpy切片、索引和广播Apr 10, 2023 pm 02:56 PM
一文详解Python数据分析模块Numpy切片、索引和广播Apr 10, 2023 pm 02:56 PMNumpy切片和索引ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。ndarray 数组可以基于 0 ~ n-1 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。高级索引整数数组索引以下实例获取数组中 (0,0),(1,1
 Python中的机器学习是什么?Jun 04, 2023 am 08:52 AM
Python中的机器学习是什么?Jun 04, 2023 am 08:52 AM近年来,机器学习(MachineLearning)成为了IT行业中最热门的话题之一,Python作为一种高效的编程语言,已经成为了许多机器学习实践者的首选。本文将会介绍Python中机器学习的概念、应用和实现。一、机器学习概念机器学习是一种让机器通过对数据的分析、学习和优化,自动改进性能的技术。其主要目的是让机器能够在数据中发现存在的规律,从而获得对未来
 如何利用 Go 语言进行数据分析和机器学习?Jun 10, 2023 am 09:21 AM
如何利用 Go 语言进行数据分析和机器学习?Jun 10, 2023 am 09:21 AM随着互联网技术的发展和大数据的普及,越来越多的公司和机构开始关注数据分析和机器学习。现在,有许多编程语言可以用于数据科学,其中Go语言也逐渐成为了一种不错的选择。虽然Go语言在数据科学上的应用不如Python和R那么广泛,但是它具有高效、并发和易于部署等特点,因此在某些场景中表现得非常出色。本文将介绍如何利用Go语言进行数据分析和机器学习
 数据挖掘和数据分析的区别是什么?Dec 07, 2020 pm 03:16 PM
数据挖掘和数据分析的区别是什么?Dec 07, 2020 pm 03:16 PM区别:1、“数据分析”得出的结论是人的智力活动结果,而“数据挖掘”得出的结论是机器从学习集【或训练集、样本集】发现的知识规则;2、“数据分析”不能建立数学模型,需要人工建模,而“数据挖掘”直接完成了数学建模。
 Python量化交易实战:获取股票数据并做分析处理Apr 15, 2023 pm 09:13 PM
Python量化交易实战:获取股票数据并做分析处理Apr 15, 2023 pm 09:13 PM量化交易(也称自动化交易)是一种应用数学模型帮助投资者进行判断,并且根据计算机程序发送的指令进行交易的投资方式,它极大地减少了投资者情绪波动的影响。量化交易的主要优势如下:快速检测客观、理性自动化量化交易的核心是筛选策略,策略也是依靠数学或物理模型来创造,把数学语言变成计算机语言。量化交易的流程是从数据的获取到数据的分析、处理。数据获取数据分析工作的第一步就是获取数据,也就是数据采集。获取数据的方式有很多,一般来讲,数据来源主要分为两大类:外部来源(外部购买、网络爬取、免费开源数据等)和内部来源
 MySQL中的大数据分析技巧Jun 14, 2023 pm 09:53 PM
MySQL中的大数据分析技巧Jun 14, 2023 pm 09:53 PM随着大数据时代的到来,越来越多的企业和组织开始利用大数据分析来帮助自己更好地了解其所面对的市场和客户,以便更好地制定商业策略和决策。而在大数据分析中,MySQL数据库也是经常被使用的一种工具。本文将介绍MySQL中的大数据分析技巧,为大家提供参考。一、使用索引进行查询优化索引是MySQL中进行查询优化的重要手段之一。当我们对某个列创建了索引后,MySQL就可
 AI牵引工业软件新升级,数据分析与人工智能在探索中进化Jun 05, 2023 pm 04:04 PM
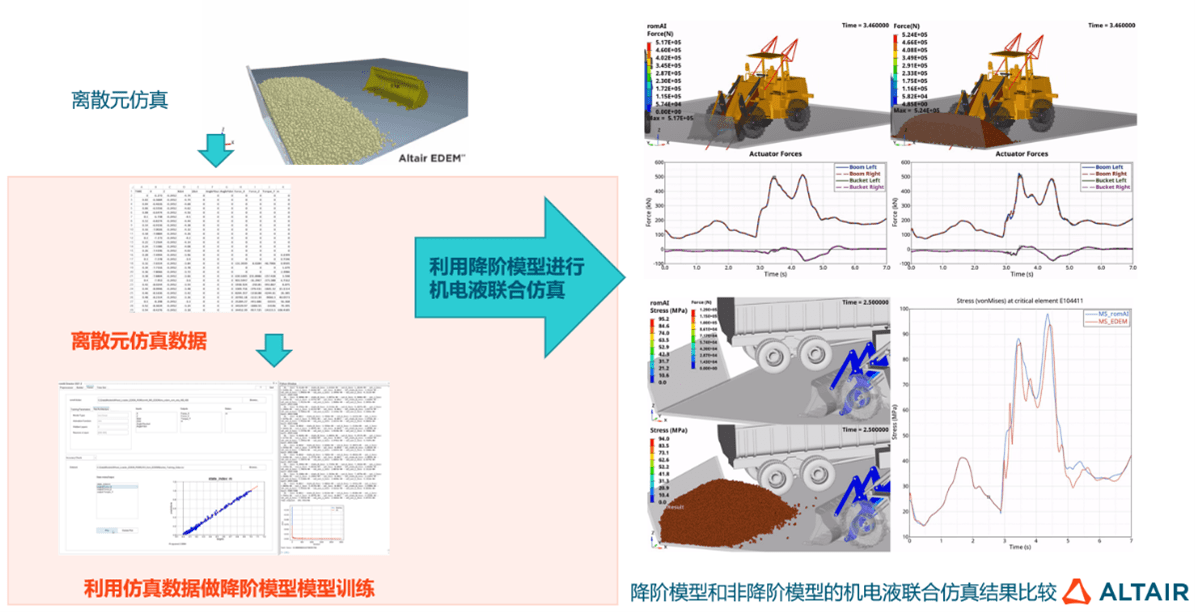
AI牵引工业软件新升级,数据分析与人工智能在探索中进化Jun 05, 2023 pm 04:04 PMCAE和AI技术双融合已成为企业研发设计环节数字化转型的重要应用趋势,但企业数字化转型绝不仅是单个环节的优化,而是全流程、全生命周期的转型升级,数据驱动只有作用于各业务环节,才能真正助力企业持续发展。数字化浪潮席卷全球,作为数字经济核心驱动,数字技术逐步成为企业发展新动能,助推企业核心竞争力进化,在此背景下,数字化转型已成为所有企业的必选项和持续发展的前提,拥抱数字经济成为企业的共同选择。但从实际情况来看,面向C端的产业如零售电商、金融等领域在数字化方面走在前列,而以制造业、能源重工等为代表的传
 为何军事人工智能初创公司近年来备受追捧Apr 13, 2023 pm 01:34 PM
为何军事人工智能初创公司近年来备受追捧Apr 13, 2023 pm 01:34 PM俄乌冲突爆发 2 周后,数据分析公司 Palantir 的首席执行官亚历山大·卡普 (Alexander Karp) 向欧洲领导人提出了一项建议。在公开信中,他表示欧洲人应该在硅谷的帮助下实现武器现代化。Karp 写道,为了让欧洲“保持足够强大以战胜外国占领的威胁”,各国需要拥抱“技术与国家之间的关系,以及寻求摆脱根深蒂固的承包商控制的破坏性公司与联邦政府部门之间的资金关系”。而军队已经开始响应这项号召。北约于 6 月 30 日宣布,它正在创建一个 10 亿美元的创新基金,将投资于早期创业公司和


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

WebStorm Mac version
Useful JavaScript development tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

