
 Technology peripheralsAIDeepMind pointed out that 'Transformer cannot generalize beyond pre-training data,' but some people questioned it.
Technology peripheralsAIDeepMind pointed out that 'Transformer cannot generalize beyond pre-training data,' but some people questioned it.
Is Transformer destined to be unable to solve new problems beyond "training data"?
Speaking of the impressive capabilities demonstrated by large language models, one of them is by providing samples in context, asking the model to generate a response, thereby achieving the ability of few-shot learning. This relies on the underlying machine learning technology "Transformer model", and they can also perform contextual learning tasks in areas other than language.
Based on past experience, it has been proven that for task families or function classes that are well represented in the pre-trained mixture, there is almost no cost in selecting appropriate function classes for contextual learning. Therefore, some researchers believe that Transformer can generalize well to tasks or functions distributed in the same distribution as the training data. However, a common but unresolved question is: how do these models perform on samples that are inconsistent with the training data distribution?
In a recent study, researchers from DeepMind explored this issue with the help of empirical research. They explain the generalization problem as follows: "Can a model generate good predictions with in-context examples using functions that do not belong to any basic function class in the mixture of pre-trained data?" from a function not in any of the base function classes seen in the pretraining data mixture? )》
The focus of this article is to explore the few samples of the data used in the pre-training process to the resulting Transformer model influence on learning ability. In order to solve this problem, the researchers first studied Transformer's ability to select different function classes for model selection during the pre-training process (Section 3), and then answered the OOD generalization problem of several key cases (Section 4)

Paper link: https://arxiv.org/pdf/2311.00871.pdf
The following situations were found in their research: First, pre-training The Transformer is very difficult to predict convex combinations of functions extracted from pre-trained function classes; secondly, although the Transformer can effectively generalize to rarer parts of the function class space, the Transformer still fails when the task exceeds its distribution range. An error occurred
Transformer cannot generalize to cognition beyond the pre-training data, so it cannot solve problems beyond cognition

In general Said, the contributions of this article are as follows:
Pre-train the Transformer model using a mixture of different function classes for context learning, and describe the characteristics of the model selection behavior ;
For functions that are “inconsistent” with the function classes in the pre-training data, the behavior of the pre-trained Transformer model in context learning was studied
Strong evidence has shown that models can perform model selection among pre-trained function classes during context learning with little additional statistical cost, but there is also limited evidence that the model's context learning behavior can exceed its The range of pre-training data.
This researcher believes that this may be good news for security, at least the model will not act as it pleases

However, some people pointed out that the model used in this paper is not suitable - the "GPT-2 scale" means that the model in this paper is about 1.5 billion parameters, which is indeed difficult to generalize. 

#Next, let’s take a look at the details of the paper.
Model selection phenomenon
When pre-training data mixtures of different function classes, you will face a problem: when the model encounters a problem supported by the pre-training mixture How to choose between different function classes when using context samples?
It was found in the study that the model is able to make the best (or close to the best) predictions when it is exposed to contextual samples related to the function class in the pre-training data. The researchers also observed the model's performance on functions that do not belong to any single component function class, and in Section 4 we discuss functions that are completely unrelated to the pre-training data
First of all, we start with the study of linear functions. We can see that linear functions have attracted widespread attention in the field of context learning. Last year, Percy Liang and others from Stanford University published a paper "What Can Transformers Learn in Context?" A case study of a simple function class" shows that the pre-trained transformer performs very well in learning new linear function contexts, almost reaching the optimal level
They considered two models in particular: one is in dense A model trained on a linear function (all coefficients of a linear model are non-zero) and the other is a model trained on a sparse linear function (only 2 coefficients out of 20 are non-zero). Each model performed comparably to linear regression and Lasso regression on the new dense linear function and sparse linear function, respectively. In addition, the researchers compared these two models with models pretrained on a mixture of sparse linear functions and dense linear functions.

As shown in Figure 1, the model's performance on a  mixture in context learning is similar to a model pretrained on only one function class. Since the performance of the hybrid pre-trained model is similar to the theoretical optimal model of Garg et al. [4], the researchers infer that the model is also close to optimal. The ICL learning curve in Figure 2 shows that this context model selection ability is relatively consistent with the number of context examples provided. You can also see in Figure 2 that for specific function classes, various non-trivial weights are used.
mixture in context learning is similar to a model pretrained on only one function class. Since the performance of the hybrid pre-trained model is similar to the theoretical optimal model of Garg et al. [4], the researchers infer that the model is also close to optimal. The ICL learning curve in Figure 2 shows that this context model selection ability is relatively consistent with the number of context examples provided. You can also see in Figure 2 that for specific function classes, various non-trivial weights are used. 

 In fact, Figure 3b shows that when the samples provided in the context come from very sparse or very dense functions, the prediction results are almost identical to those of the model pretrained using only sparse data or only using dense data. . However, in between, when the number of non-zero coefficients ≈ 4, the hybrid predictions deviate from those of the purely dense or purely sparse pretrained Transformer.
In fact, Figure 3b shows that when the samples provided in the context come from very sparse or very dense functions, the prediction results are almost identical to those of the model pretrained using only sparse data or only using dense data. . However, in between, when the number of non-zero coefficients ≈ 4, the hybrid predictions deviate from those of the purely dense or purely sparse pretrained Transformer.
This shows that the model pretrained on the mixture does not simply select a single function class to predict, but predicts an outcome in between.
Limitations of model selection abilityNext, the researchers examined the ICL generalization ability of the model from two perspectives. First, the ICL performance of functions that the model has not been exposed to during training is tested; second, the ICL performance of extreme versions of functions that the model has been exposed to during pre-training is evaluated.
In these two cases, studies find little evidence of out-of-distribution generalization. When the function differs greatly from the function seen during pre-training, the prediction will be unstable; when the function is close enough to the pre-training data, the model can approximate well
Transformer’s predictions at moderate sparsity levels (nnz = 3 to 7) are not similar to the predictions of any function class provided by pre-training, but are somewhere in between, as shown in Figure 3a. Therefore, we can infer that the model has some kind of inductive bias that enables it to combine pre-trained function classes in a non-trivial way. For example, we can suspect that the model can generate predictions based on the combination of functions seen during pre-training. To test this hypothesis, we explored the ability to perform ICL on linear functions, sinusoids, and convex combinations of the two. They focus on the one-dimensional case to make it easier to evaluate and visualize the nonlinear function class
Figure 4 shows that while the model is pretrained on a mixture of linear functions and sinusoids (i.e.  ) Able to make good predictions on either of these two functions separately, it cannot fit a convex combination of the two. This suggests that the linear function interpolation phenomenon shown in Figure 3b is not a generalizable inductive bias of Transformer context learning. However, it continues to support the narrower assumption that when the context sample is close to the function class learned in pre-training, the model is able to select the best function class for prediction.
) Able to make good predictions on either of these two functions separately, it cannot fit a convex combination of the two. This suggests that the linear function interpolation phenomenon shown in Figure 3b is not a generalizable inductive bias of Transformer context learning. However, it continues to support the narrower assumption that when the context sample is close to the function class learned in pre-training, the model is able to select the best function class for prediction.

For more research details, please refer to the original paper
The above is the detailed content of DeepMind pointed out that 'Transformer cannot generalize beyond pre-training data,' but some people questioned it.. For more information, please follow other related articles on the PHP Chinese website!

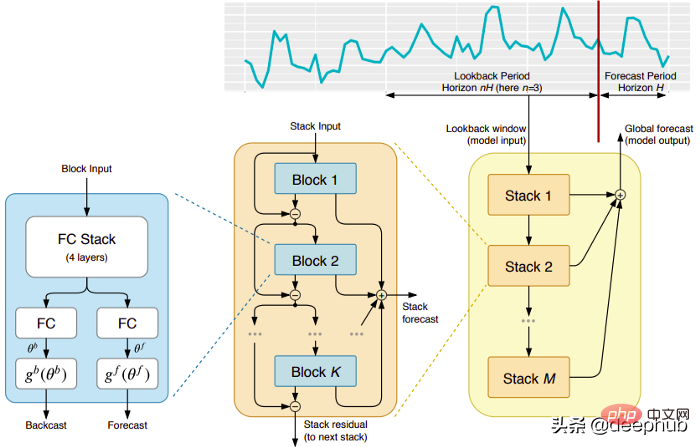 五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PM
五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PMMakridakisM-Competitions系列(分别称为M4和M5)分别在2018年和2020年举办(M6也在今年举办了)。对于那些不了解的人来说,m系列得比赛可以被认为是时间序列生态系统的一种现有状态的总结,为当前得预测的理论和实践提供了经验和客观的证据。2018年M4的结果表明,纯粹的“ML”方法在很大程度上胜过传统的统计方法,这在当时是出乎意料的。在两年后的M5[1]中,最的高分是仅具有“ML”方法。并且所有前50名基本上都是基于ML的(大部分是树型模型)。这场比赛看到了LightG
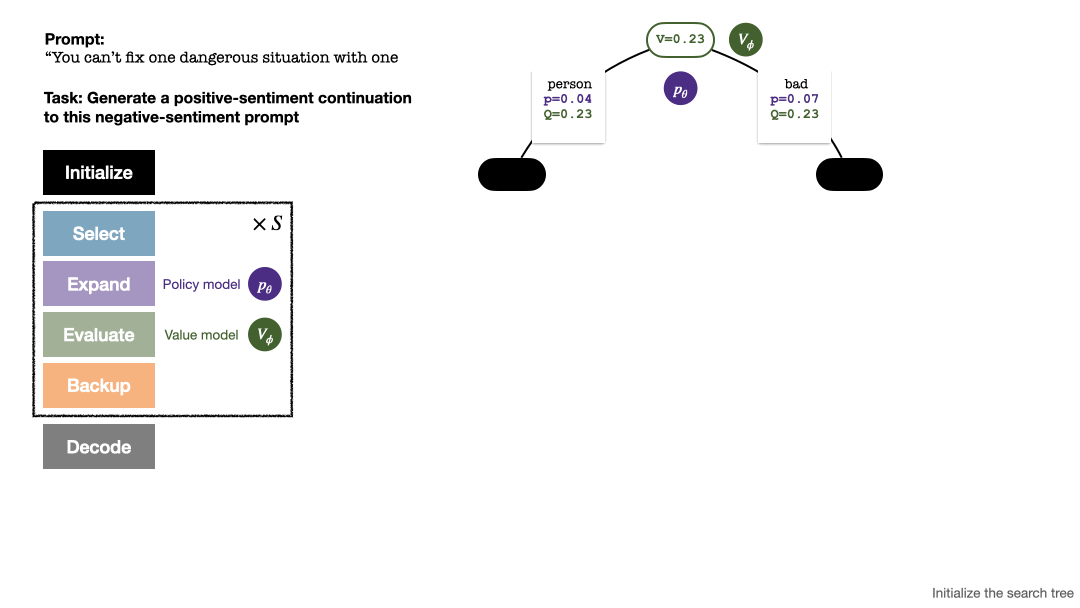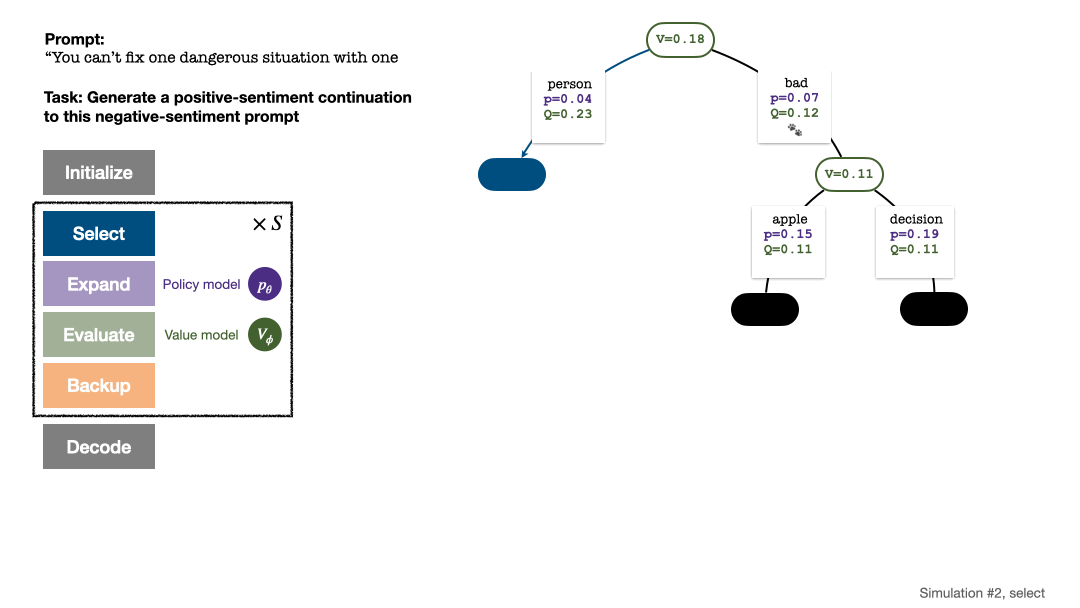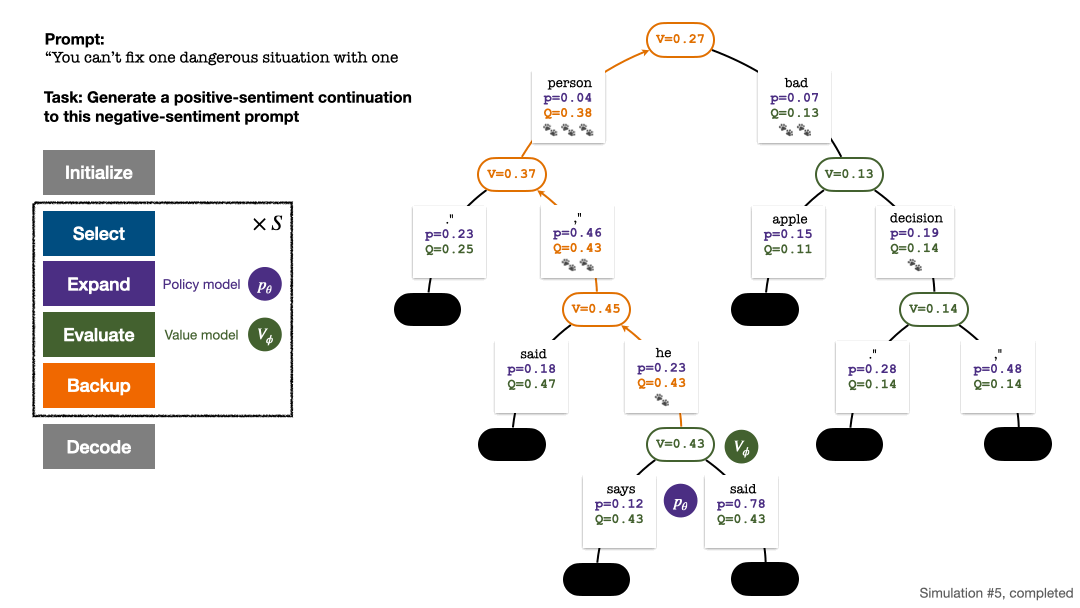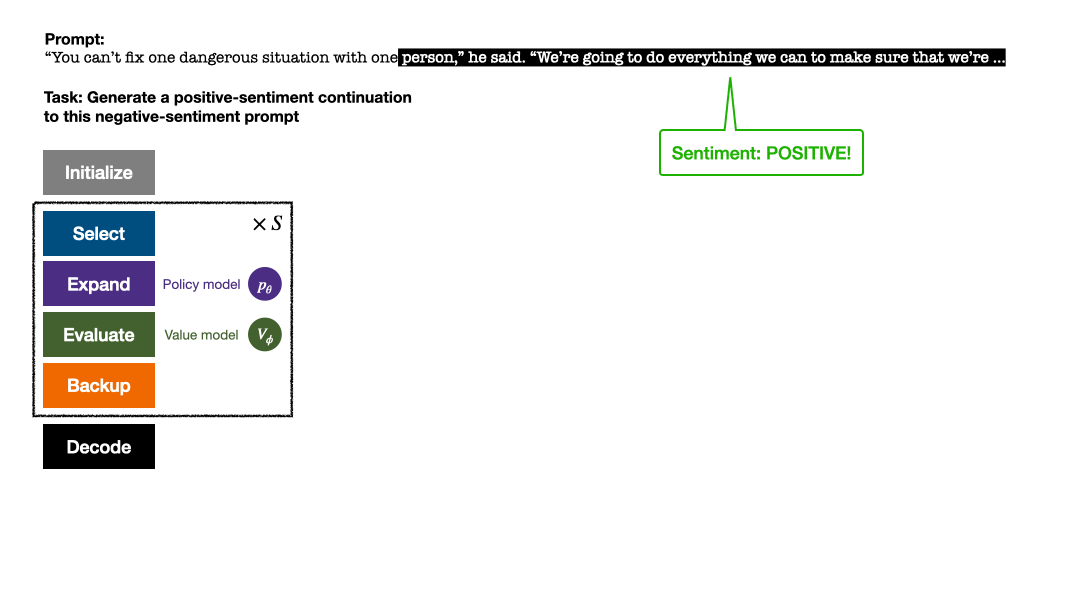 RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM
RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM在一项最新的研究中,来自UW和Meta的研究者提出了一种新的解码算法,将AlphaGo采用的蒙特卡洛树搜索算法(Monte-CarloTreeSearch,MCTS)应用到经过近端策略优化(ProximalPolicyOptimization,PPO)训练的RLHF语言模型上,大幅提高了模型生成文本的质量。PPO-MCTS算法通过探索与评估若干条候选序列,搜索到更优的解码策略。通过PPO-MCTS生成的文本能更好满足任务要求。论文链接:https://arxiv.org/pdf/2309.150
 MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM
MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM编辑|X传统意义上,发现所需特性的分子过程一直是由手动实验、化学家的直觉以及对机制和第一原理的理解推动的。随着化学家越来越多地使用自动化设备和预测合成算法,自主研究设备越来越接近实现。近日,来自MIT的研究人员开发了由集成机器学习工具驱动的闭环自主分子发现平台,以加速具有所需特性的分子的设计。无需手动实验即可探索化学空间并利用已知的化学结构。在两个案例研究中,该平台尝试了3000多个反应,其中1000多个产生了预测的反应产物,提出、合成并表征了303种未报道的染料样分子。该研究以《Autonom
 AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM
AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM作者|陈旭鹏编辑|ScienceAI由于神经系统的缺陷导致的失语会导致严重的生活障碍,它可能会限制人们的职业和社交生活。近年来,深度学习和脑机接口(BCI)技术的飞速发展为开发能够帮助失语者沟通的神经语音假肢提供了可行性。然而,神经信号的语音解码面临挑战。近日,约旦大学VideoLab和FlinkerLab的研究者开发了一个新型的可微分语音合成器,可以利用一个轻型的卷积神经网络将语音编码为一系列可解释的语音参数(例如音高、响度、共振峰频率等),并通过可微分神经网络将这些参数合成为语音。这个合成器
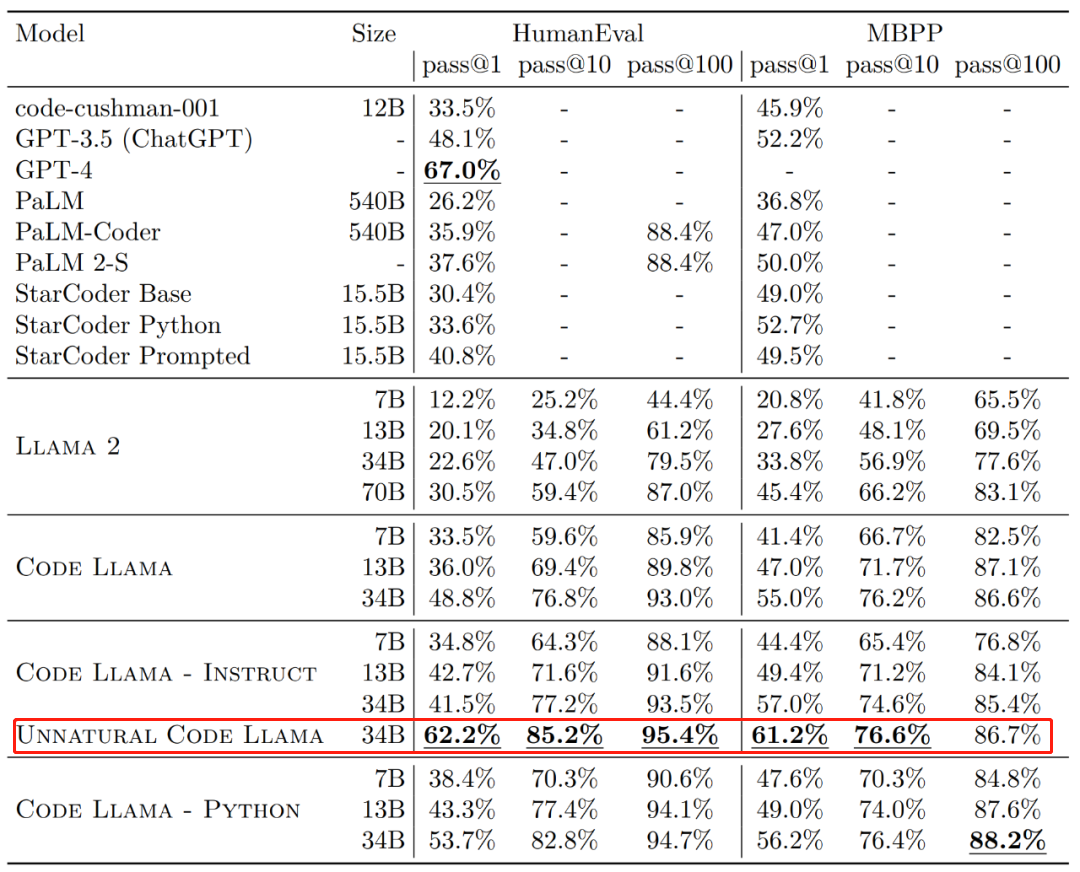 Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM
Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM昨天,Meta开源专攻代码生成的基础模型CodeLlama,可免费用于研究以及商用目的。CodeLlama系列模型有三个参数版本,参数量分别为7B、13B和34B。并且支持多种编程语言,包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash。Meta提供的CodeLlama版本包括:代码Llama,基础代码模型;代码羊-Python,Python微调版本;代码Llama-Instruct,自然语言指令微调版就其效果来说,CodeLlama的不同版
 准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM
准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM编辑|紫罗可合成分子的化学空间是非常广阔的。有效地探索这个领域需要依赖计算筛选技术,比如深度学习,以便快速地发现各种有趣的化合物。将分子结构转换为数字表示形式,并开发相应算法生成新的分子结构是进行化学发现的关键。最近,英国格拉斯哥大学的研究团队提出了一种基于电子密度训练的机器学习模型,用于生成主客体binders。这种模型能够以简化分子线性输入规范(SMILES)格式读取数据,准确率高达98%,从而实现对分子在二维空间的全面描述。通过变分自编码器生成主客体系统的电子密度和静电势的三维表示,然后通
 手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM
手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM一个普通人用一台手机就能制作电影特效的时代已经来了。最近,一个名叫Simulon的3D技术公司发布了一系列特效视频,视频中的3D机器人与环境无缝融合,而且光影效果非常自然。呈现这些效果的APP也叫Simulon,它能让使用者通过手机摄像头的实时拍摄,直接渲染出CGI(计算机生成图像)特效,就跟打开美颜相机拍摄一样。在具体操作中,你要先上传一个3D模型(比如图中的机器人)。Simulon会将这个模型放置到你拍摄的现实世界中,并使用准确的照明、阴影和反射效果来渲染它们。整个过程不需要相机解算、HDR
 NVIDIA、Mila、Caltech联合发布LLM结合药物发现的多模态分子结构-文本模型Jan 14, 2024 pm 08:00 PM
NVIDIA、Mila、Caltech联合发布LLM结合药物发现的多模态分子结构-文本模型Jan 14, 2024 pm 08:00 PM作者|刘圣超编辑|凯霞从2021年开始,大语言和多模态的结合席卷了机器学习科研界。随着大模型和多模态应用的发展,我们是否可以将这些技术应用于药物发现呢?而且,这些自然语言的文本描述是否可以为这个具有挑战性的问题带来新的视角呢?答案是肯定的,并且我们对此持乐观态度近日,加拿大蒙特利尔学习算法研究院(Mila)、NVIDIAResearch、伊利诺伊大学厄巴纳-香槟分校(UIUC)、普林斯顿大学和加州理工学院的研究团队,通过对比学习策略共同学习分子的化学结构和文本描述,提出了一种多模态分子结构-文本


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

Notepad++7.3.1
Easy-to-use and free code editor

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

