



This article is reprinted with the authorization of the Heart of Autonomous Driving public account. For reprinting, please contact the source of the original text
## 1. Woven Planet (Toyota subsidiary)’s plan: Urban Driver 2021
Although this article is from 21 years old, many new articles use it as a baseline for comparison, so it is necessary to understand its method
 ## After a rough look, the main purpose is to use Policy Gradients to learn the mapping function of State->Recent Action. With this mapping function, the entire execution trajectory can be deduced step by step. In the end, the loss is to let this The trajectory given by the deduction is as close as possible to the expert trajectory.
## After a rough look, the main purpose is to use Policy Gradients to learn the mapping function of State->Recent Action. With this mapping function, the entire execution trajectory can be deduced step by step. In the end, the loss is to let this The trajectory given by the deduction is as close as possible to the expert trajectory.
The effect should be pretty good at the time, so it can become the baseline for new algorithms.
2. Nanyang Technological University Program 1 Conditional Predictive Behavior Planning with Inverse Reinforcement Learning 2023.04 First use rules to enumerate many This behavior generated 10 to 30 trajectories. (Prediction results not used)
First use rules to enumerate many This behavior generated 10 to 30 trajectories. (Prediction results not used)
The Conditional Joint Prediction model looks like this:
 The basically great thing about this method is that it uses Conditional Joint Prediction to achieve good interactivity. The prediction gives the algorithm a certain gaming ability.
The basically great thing about this method is that it uses Conditional Joint Prediction to achieve good interactivity. The prediction gives the algorithm a certain gaming ability.
Use regular tree sampling, consider layer by layer, generate a conditional prediction for each sub-node of each layer, then use rules to score the prediction results and the main vehicle trajectory, and use some rules to classify illegal Kill it, and then use DP to generate the optimal trajectory in the future. The DP idea is somewhat similar to dp_path_optimizer in apollo, but with a time dimension added.
However, because there is one more dimension, after the number of subsequent expansions is too large, the solution space will still be large and the calculation amount will be too large. The method written in the current paper is to randomly discard the nodes after there are too many. Some nodes are added to ensure that the amount of calculation is controllable (it feels like it means that after too many nodes, it may be n levels later, and the impact may be smaller)
The main contribution of this article is to pass a continuous solution space through this tree shape The sampling rule transforms a Markov decision process, which is then solved using dp.
4. The latest joint plan of Nanyang Technological University and NVIDIA in October 2023: DTPP: Differentiable Joint Conditional Prediction and Cost Evaluation for Tree Policy Planning in Autonomous DrivingSee The title feels very Exciting:
1. Conditional Prediction ensures a certain gaming effect
2. It is derivable and can pass back the entire gradient so that prediction and IRL can be trained together. It is also a necessary condition for being able to build an end-to-end autonomous driving3. Tree Policy Planning, which may have certain interactive deduction capabilities
After reading it carefully, I found that this article is very informative and the method Very clever.
 After combining and improving NVIDIA’s TPP and Nanyang Polytechnic’s Conditional Predictive Behavior Planning with Inverse Reinforcement Learning, we successfully solved the problem of poor candidate trajectories in the previous Nanyang Polytechnic paper. Question
After combining and improving NVIDIA’s TPP and Nanyang Polytechnic’s Conditional Predictive Behavior Planning with Inverse Reinforcement Learning, we successfully solved the problem of poor candidate trajectories in the previous Nanyang Polytechnic paper. Question
The main modules of the paper plan include:
1. Conditional Prediction module, input a main vehicle historical trajectory prompt trajectory and obstacle vehicle historical trajectory, and give the predicted trajectory of the main vehicle approaching the prompt trajectory and The predicted trajectory of the obstacle vehicle is consistent with the behavior of the host vehicle.
2. The scoring module can score a main vehicle obstacle vehicle trajectory to see whether the trajectory resembles the behavior of an expert. The learning method is IRL.3. Tree Policy Search module, used to generate a bunch of candidate trajectories
Use the Tree Search algorithm to explore the feasible solution of the main vehicle. Each step in the exploration process takes the explored trajectory as input, uses the Conditional Prediction algorithm to generate the predicted trajectories of the main vehicle and the obstacle vehicle, and calls the scoring module to evaluate the trajectory. The pros and cons will affect the direction of the next search for expansion nodes. Through this method, you can generate some main vehicle trajectories that are different from other solutions, and consider the interaction with the obstacle vehicle when generating trajectories
Traditional IRL manually creates a lot of features. For example, in order to make the model differentiable, in this article, we directly use the ego context MLP of prediction to generate a Weight array (such as relative s, l and ttc) of a bunch of obstacles in the trajectory time dimension ( size = 1 * C), which implicitly represents the environmental information around the host vehicle, and then uses MLP to directly convert the multi-modal prediction results corresponding to the host vehicle trajectory into a Feature array (size = C * N, N refers to the candidate number of trajectories), and then the two matrices are multiplied to obtain the final trajectory score. Then IRL let the experts score the highest points. Personally, I feel that this may be for calculation efficiency, making the decoder as simple as possible, but there is still a certain loss of main vehicle information. If you do not pay attention to calculation efficiency, you can use some more complex networks to connect Ego Context and Predicted Trajectories, and the effect level should be better. good? Or if you give up differentiability, you can still consider adding manually set features, which should also improve the model effect.
In terms of time, this solution uses a method of re-encoding once and lightweight decoding multiple times, successfully reducing computing delays. The article points out that the delay can be compressed to 98 milliseconds
It belongs to the SOTA ranks among learning based planners, and the closed-loop effect is close to nuplan's No. 1 Rule Based scheme PDM mentioned in the previous article.
Summary
After looking at it, I feel that this paradigm is a pretty good idea. You can adjust the specific process yourself:
- Use the prediction model to guide some rules to generate some candidate ego trajectories
- For each trajectory, use Conditional Joint Prediction to make interactive predictions and generate agent predictions. Can improve gaming performance.
- IRL and other methods use the Conditional Joint Prediction results to score the previous main vehicle trajectory and select the optimal trajectory

need to be rewritten The content is: Original link: https://mp.weixin.qq.com/s/ZJtMU3zGciot1g5BoCe9Ow
The above is the detailed content of A review of end-to-end planning methods for autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

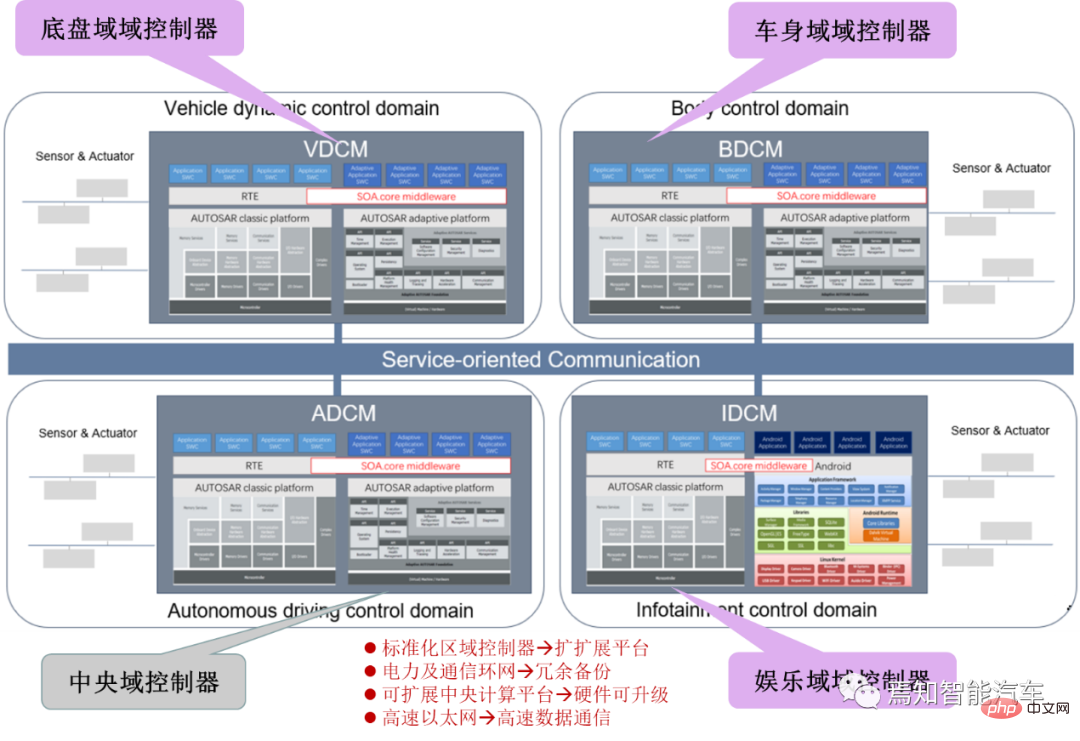 SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
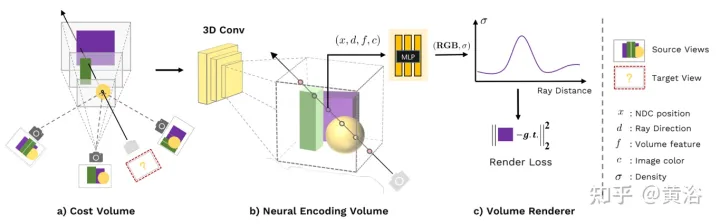 新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM
新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM新视角图像生成(NVS)是计算机视觉的一个应用领域,在1998年SuperBowl的比赛,CMU的RI曾展示过给定多摄像头立体视觉(MVS)的NVS,当时这个技术曾转让给美国一家体育电视台,但最终没有商业化;英国BBC广播公司为此做过研发投入,但是没有真正产品化。在基于图像渲染(IBR)领域,NVS应用有一个分支,即基于深度图像的渲染(DBIR)。另外,在2010年曾很火的3D TV,也是需要从单目视频中得到双目立体,但是由于技术的不成熟,最终没有流行起来。当时基于机器学习的方法已经开始研究,比
 多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM
多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM我们经常可以看到蜜蜂、蚂蚁等各种动物忙碌地筑巢。经过自然选择,它们的工作效率高到叹为观止这些动物的分工合作能力已经「传给」了无人机,来自英国帝国理工学院的一项研究向我们展示了未来的方向,就像这样:无人机 3D 打灰:本周三,这一研究成果登上了《自然》封面。论文地址:https://www.nature.com/articles/s41586-022-04988-4为了展示无人机的能力,研究人员使用泡沫和一种特殊的轻质水泥材料,建造了高度从 0.18 米到 2.05 米不等的结构。与预想的原始蓝图
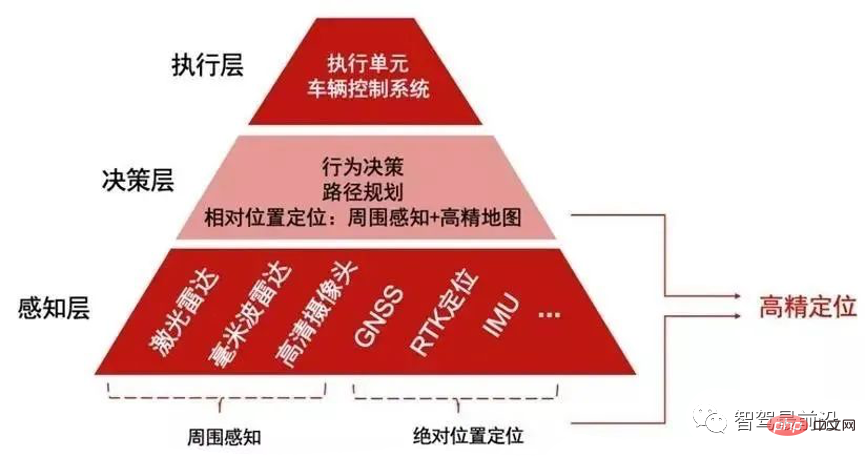 如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM
如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM与人类行走一样,自动驾驶汽车想要完成出行过程也需要有独立思考,可以对交通环境进行判断、决策的能力。随着高级辅助驾驶系统技术的提升,驾驶员驾驶汽车的安全性不断提高,驾驶员参与驾驶决策的程度也逐渐降低,自动驾驶离我们越来越近。自动驾驶汽车又称为无人驾驶车,其本质就是高智能机器人,可以仅需要驾驶员辅助或完全不需要驾驶员操作即可完成出行行为的高智能机器人。自动驾驶主要通过感知层、决策层及执行层来实现,作为自动化载具,自动驾驶汽车可以通过加装的雷达(毫米波雷达、激光雷达)、车载摄像头、全球导航卫星系统(G
 超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM
超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM实时全局光照(Real-time GI)一直是计算机图形学的圣杯。多年来,业界也提出多种方法来解决这个问题。常用的方法包通过利用某些假设来约束问题域,比如静态几何,粗糙的场景表示或者追踪粗糙探针,以及在两者之间插值照明。在虚幻引擎中,全局光照和反射系统Lumen这一技术便是由Krzysztof Narkowicz和Daniel Wright一起创立的。目标是构建一个与前人不同的方案,能够实现统一照明,以及类似烘烤一样的照明质量。近期,在SIGGRAPH 2022上,Krzysztof Narko
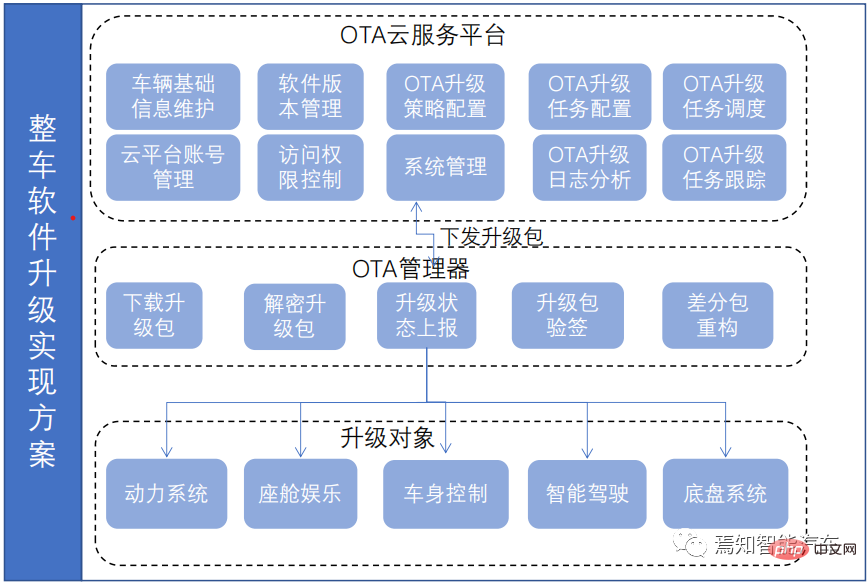 一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM
一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM由于智能汽车集中化趋势,导致在网络连接上已经由传统的低带宽Can网络升级转换到高带宽以太网网络为主的升级过程。为了提升车辆升级能力,基于为车主提供持续且优质的体验和服务,需要在现有系统基础(由原始只对车机上传统的 ECU 进行升级,转换到实现以太网增量升级的过程)之上开发一套可兼容现有 OTA 系统的全新 OTA 服务系统,实现对整车软件、固件、服务的 OTA 升级能力,从而最终提升用户的使用体验和服务体验。软件升级触及的两大领域-FOTA/SOTA整车软件升级是通过OTA技术,是对车载娱乐、导
 internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PM
internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PMinternet的基本结构与技术起源于ARPANET。ARPANET是计算机网络技术发展中的一个里程碑,它的研究成果对促进网络技术的发展起到了重要的作用,并未internet的形成奠定了基础。arpanet(阿帕网)为美国国防部高级研究计划署开发的世界上第一个运营的封包交换网络,它是全球互联网的始祖。
 施一公等团队登Science封面:AI与冷冻电镜揭示「原子级」NPC结构,生命科学突破Apr 11, 2023 pm 05:22 PM
施一公等团队登Science封面:AI与冷冻电镜揭示「原子级」NPC结构,生命科学突破Apr 11, 2023 pm 05:22 PM开始正文之前,我们先来看一张图片,在下图中,很明显可以看出,图的右半部分所代表的信息更加丰富,结构也更清晰。而左半部分 2016 年的图,则结构较为单一,代表的信息比较少:其实上面展示的是核孔复合体(NPC)图像。核孔复合体,由约 1000 个蛋白质亚基组成,担负着真核生物细胞核与细胞质之间繁忙的运输大分子的任务,也是其连接胞质和细胞核的唯一双向通道。除了协调运输外,NPC 还组织必要的转录、mRNA 成熟、剪接体和核糖体组装等重要生命活动。NPC 强大的作用,已然成为疾病突变和宿主 - 病原


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

WebStorm Mac version
Useful JavaScript development tools

Atom editor mac version download
The most popular open source editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

