
Home >Technology peripherals >AI >Can your GPU run large models such as Llama 2? Try it out with this open source project
Can your GPU run large models such as Llama 2? Try it out with this open source project

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-10-23 14:29:011533browse
In an era where computing power is king, can your GPU run large models (LLM) smoothly?
Many people find it difficult to give an exact answer to this question and do not know how to calculate GPU memory. Because seeing which LLMs a GPU can handle is not as easy as looking at the model size, models can take up a lot of memory during inference (KV cache), e.g. llama-2-7b has a sequence length of 1000 and requires 1GB of additional memory. Not only that, during model training, KV cache, activation and quantization will occupy a lot of memory.
We can’t help but wonder if we can know the above memory usage in advance. In recent days, a new project has appeared on GitHub that can help you calculate how much GPU memory is needed during training or inference of LLM. Not only that, with the help of this project, you can also know the detailed memory distribution and evaluation methods. Quantization method, maximum context length processed and other issues to help users choose the GPU configuration that suits them.
Project address: https://github.com/RahulSChand/gpu_poor
Not only that, This project is still interactive, as shown below. It can calculate the GPU memory required to run LLM. It is as simple as filling in the blanks. The user only needs to enter some necessary parameters, and finally click the blue button, and the answer will be Out.
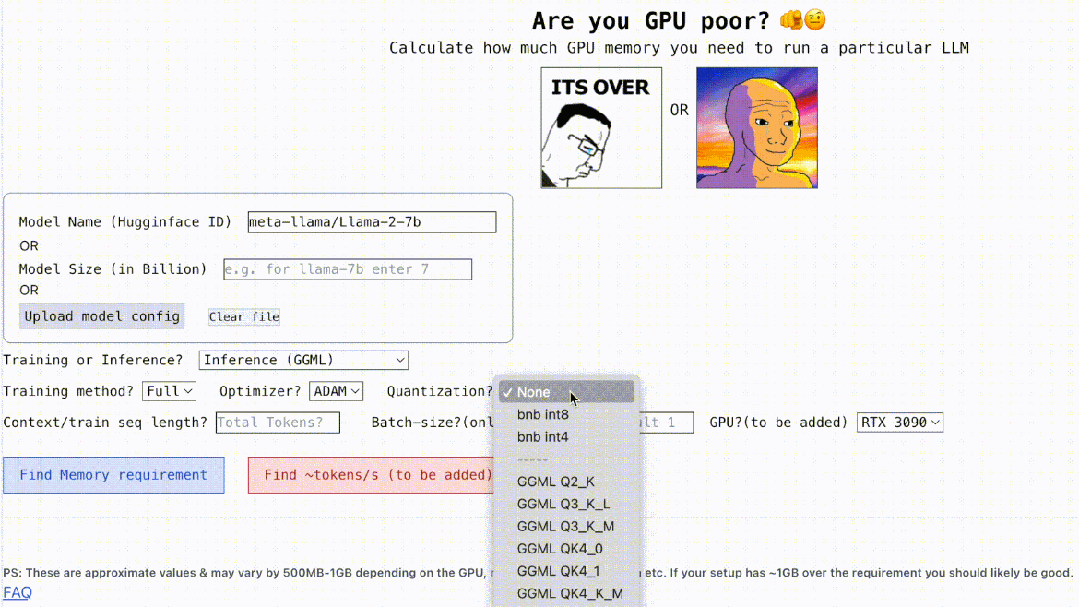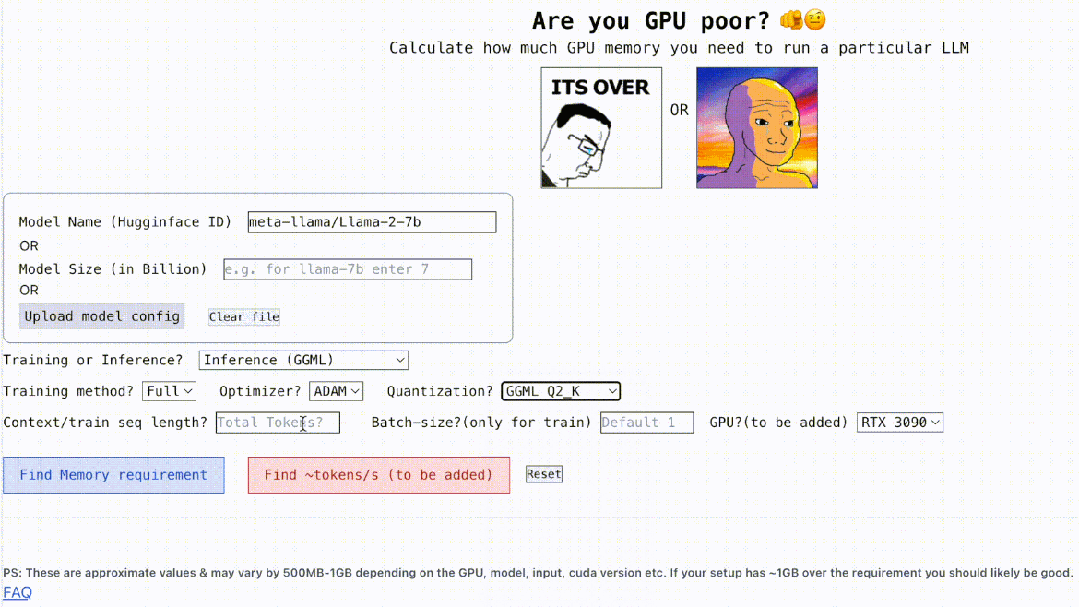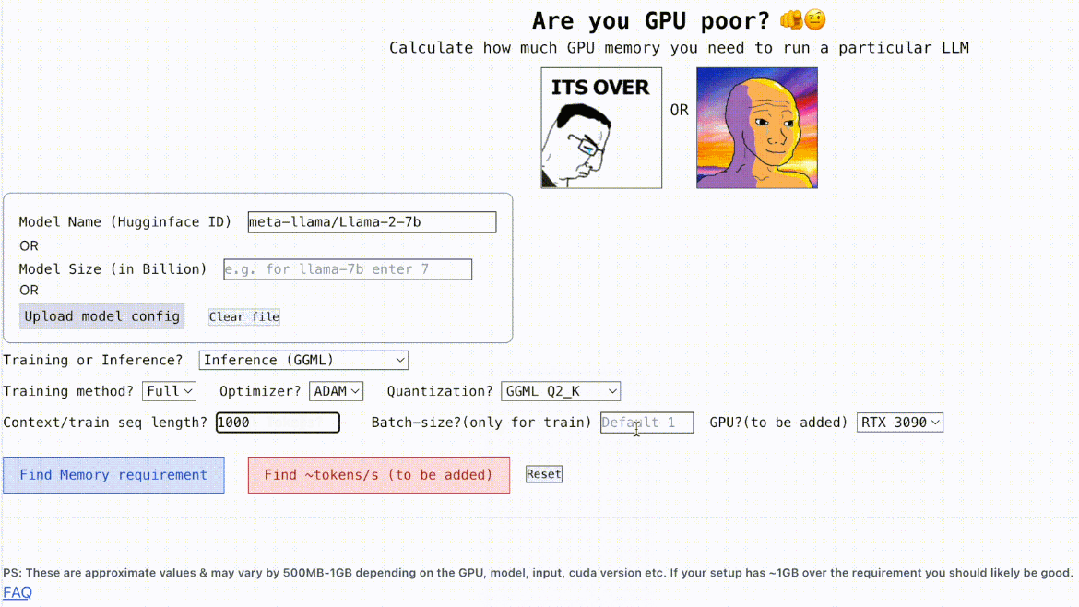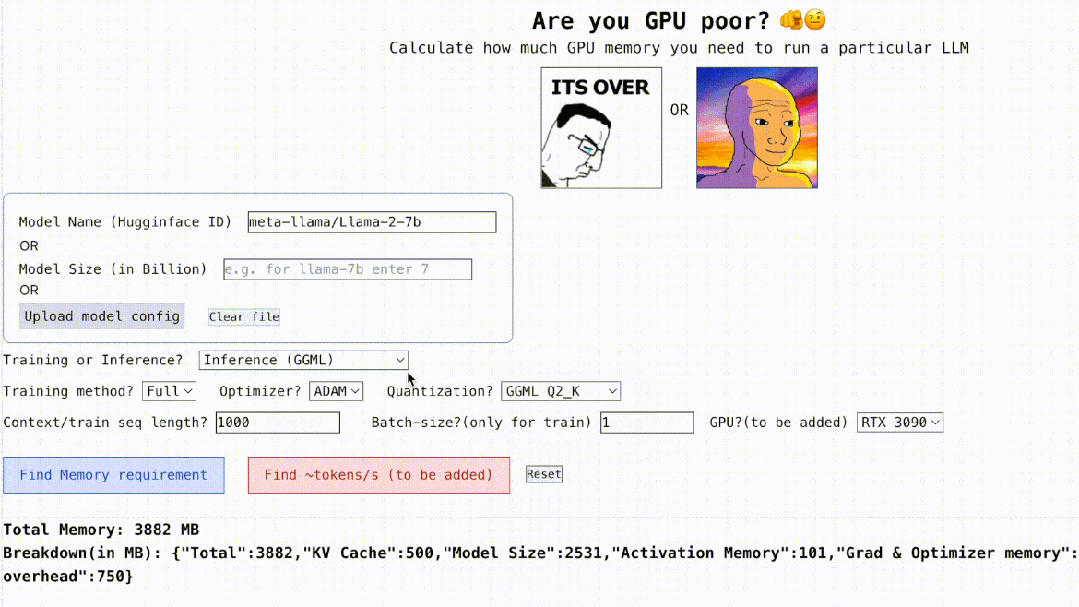
Interaction address: https://rahulschand.github.io/gpu_poor/
Final The output format is like this:
{"Total": 4000,"KV Cache": 1000,"Model Size": 2000,"Activation Memory": 500,"Grad & Optimizer memory": 0,"cuda + other overhead":500}
As for why this project is done, the author Rahul Shiv Chand said that there are the following reasons:
- When running LLM on GPU, what quantization method should be used to adapt to the model;
- What is the maximum context length that GPU can handle;
- What kind of fine-tuning method is more suitable for you? Full? LoRA? Or QLoRA?
- What is the maximum batch that can be used during fine-tuning;
- Which task is consuming the GPU? Memory, how to adjust it so that LLM can adapt to the GPU.
So, how do we use it?
The first is the processing of the model name, ID and model size. You can enter the model ID on Huggingface (e.g. meta-llama/Llama-2-7b). Currently, the project has hardcoded and saved model configurations for the top 3000 most downloaded LLMs on Huggingface.
If you use a custom model or Hugginface ID is not available, then you need to upload the json configuration (refer to the project example) or only enter the model size (for example, llama-2-7b is 70 billion) will do.
Then comes quantization. Currently, the project supports bitsandbytes (bnb) int8/int4 and GGML (QK_8, QK_6, QK_5, QK_4, QK_2). The latter is only used for inference, while bnb int8/int4 can be used for both training and inference.
The last step is inference and training. During the inference process, use HuggingFace implementation or use vLLM or GGML methods to find the vRAM used for inference; during the training process, find the vRAM for full model fine-tuning. Or use LoRA (the current project has hard-coded r=8 configured for LoRA) or QLoRA for fine-tuning.
However, the project authors stated that the final results may vary depending on the user model, input data, CUDA version, and quantification tools. In the experiment, the author tried to take these factors into account and ensure that the final result was within 500MB. The table below is where the author cross-checked the memory usage of the 3b, 7b and 13b models provided on the website compared to what the author obtained on the RTX 4090 and 2060 GPUs. All values are within 500MB.
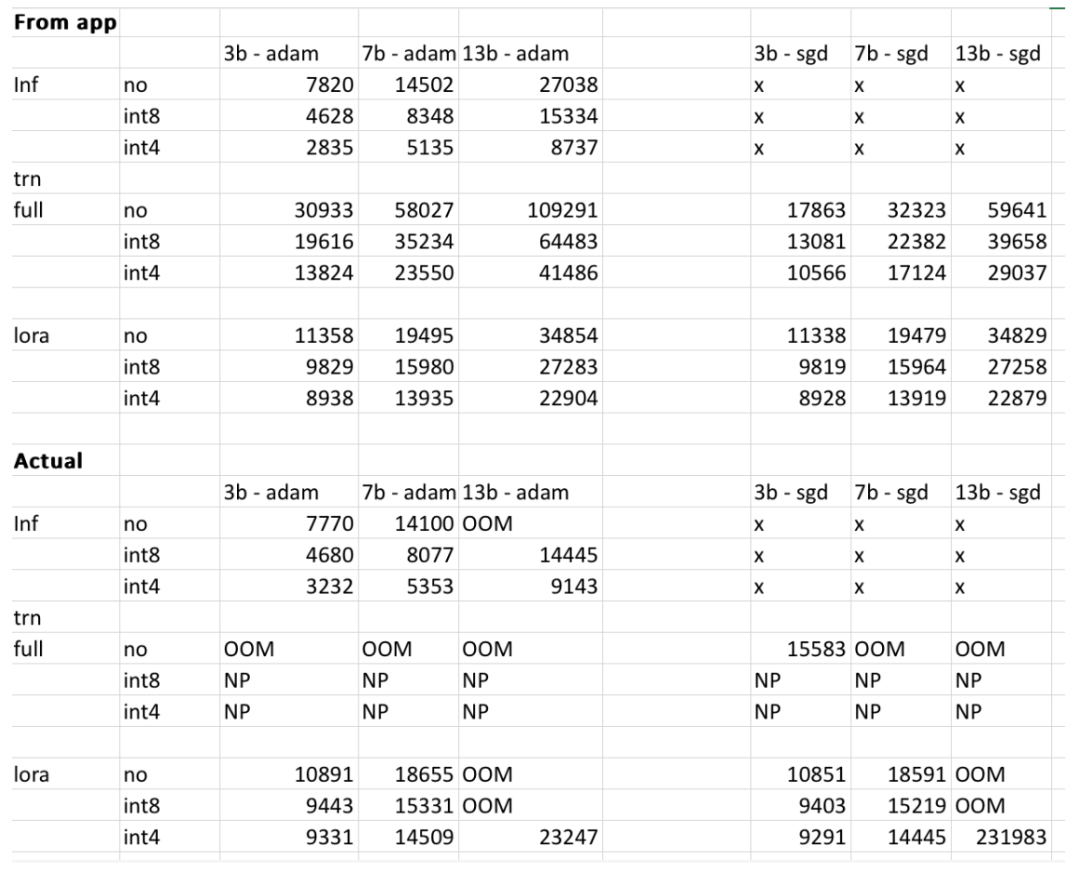
Interested readers can experience it for themselves. If the given results are inaccurate, the project author said that the project will be optimized and improved in a timely manner. project.
The above is the detailed content of Can your GPU run large models such as Llama 2? Try it out with this open source project. For more information, please follow other related articles on the PHP Chinese website!