



In terms of learning, GPT-4 is a great student. After digesting a large amount of human data, it has mastered various knowledge and can even inspire mathematician Terence Tao during chats.
At the same time, it has also become an excellent teacher, and it not only teaches book knowledge, but also teaches the robot to turn pens.

The robot, called Eureka, is the result of research from Nvidia, the University of Pennsylvania, Caltech, and the University of Texas at Austin. This research combines research on large language models and reinforcement learning: GPT-4 is used to refine the reward function, and reinforcement learning is used to train robot controllers.
With the ability to write code in GPT-4, Eureka has excellent reward function design capabilities. Its independently generated rewards are better than those of human experts in 83% of tasks. This ability allows robots to complete many tasks that were not easy to complete before, such as turning pens, opening drawers and cabinets, throwing and catching balls, dribbling, and operating scissors. However, this is all done in a virtual environment for the time being.



#In addition, Eureka also implements a new type of in -context RLHF, which is able to incorporate natural language feedback from human operators to guide and align reward functions. It can provide powerful auxiliary functions for robot engineers and help engineers design complex motion behaviors. Jim Fan, a senior AI scientist at NVIDIA and one of the authors of the paper, likened this research to "Voyager (the outer galaxy space probe developed and built by the United States) in physics simulator API space."

It is worth mentioning that this research is completely open source, the open source address is as follows:

- Paper link: https://arxiv.org/pdf/2310.12931.pdf
- Project link: https://eureka-research.github.io/
- Code link: https://github.com/eureka-research/Eureka
Paper Overview
Large language models (LLM) excel in high-level semantic planning for robotic tasks (such as Google SayCan, RT-2 robots), but whether they can be used to learn complex low-level manipulation tasks, such as turning a pen, remains an open question. Existing attempts require extensive domain expertise to construct task prompts or learn only simple skills, falling far short of human-level flexibility.

Google’s RT-2 robot.
On the other hand, reinforcement learning (RL) has achieved impressive results in flexibility and many other aspects (such as OpenAI’s Rubik’s Cube-playing robot hand), but requires human design The engineer carefully constructs the reward function to accurately codify and provide the learning signal for the desired behavior. Since many real-world reinforcement learning tasks only provide sparse rewards that are difficult to use for learning, reward shaping is needed in practice to provide progressive learning signals. Despite its importance, the reward function is notoriously difficult to design. A recent survey found that 92% of reinforcement learning researchers and practitioners surveyed said they engaged in manual trial and error when designing rewards, and 89% said the rewards they designed were suboptimal and led to unintended consequences. Behavior.
Given that reward design is so important, we can’t help but ask, is it possible to develop a general reward programming algorithm using state-of-the-art coding LLM (such as GPT-4)? These LLMs have excellent performance in code writing, zero-shot generation, and in-context learning, and have greatly improved the performance of programming agents. Ideally, such reward design algorithms should have human-level reward generation capabilities, be scalable to a wide range of tasks, automate the tedious trial-and-error process without human supervision, while being compatible with human supervision to ensure safety. sex and consistency.
This paper proposes a reward design algorithm EUREKA (full name is Evolution-driven Universal REward Kit for Agent) driven by LLM. This algorithm has achieved the following achievements:
#1. The performance of reward design has reached human level in 29 different open source RL environments, including 10 different robot forms ( Quadruped robots, quadrotor robots, biped robots, manipulators, and several dexterous hands, see Figure 1. Without any task-specific prompts or reward templates, EUREKA’s autonomously generated rewards outperformed humans in 83% of tasks Expert rewards and achieved an average normalized improvement of 52%.

2. Solve the dexterity that was previously unachievable through manual reward engineering Operational tasks. Take the pen-turning problem as an example, in which a hand with five fingers needs to quickly rotate a pen according to a preset rotation configuration and rotate as many cycles as possible. By combining EUREKA with the course Combined with learning, the researcher demonstrated the operation of rapid pen rotation for the first time on a simulated anthropomorphic "Shadow Hand" (see the bottom of Figure 1).
3. Reinforcement learning based on human feedback (RLHF) provides a new gradient-free context learning method that can generate more efficient and human-aligned reward functions based on various forms of human input. The paper shows that EUREKA can generate from existing human reward functions Benefit and improve. Similarly, the researchers also demonstrated EUREKA's ability to use human text feedback to assist in the design of reward functions, which helps capture subtle human preferences.
With Unlike previous L2R work that used LLM to assist reward design, EUREKA has no specific task prompts, reward templates, and a small number of examples. In experiments, EUREKA performed significantly better than L2R, thanks to its ability to generate and improve free-form, expressive capabilities Strong reward program.
EUREKA’s generality benefits from three key algorithm design choices: environment as context, evolutionary search, and reward reflection.
First, by taking the environment source code as context, EUREKA can generate executable reward functions from zero samples in the backbone encoding LLM (GPT-4). Then, EUREKA iteratively Proposing batches of reward candidates and refining the most promising rewards within the LLM context window greatly improves the quality of rewards. This in-context improvement is achieved through reward reflection, which is a reward based on policy training statistics Quality text summary, enabling automatic and targeted reward editing.
Figure 3 shows an example of EUREKA’s zero-sample reward, as well as various improvements accumulated during the optimization process. In order to ensure that EUREKA can Extending its reward search to its maximum potential, EUREKA uses GPU-accelerated distributed reinforcement learning on IsaacGym to evaluate intermediate rewards, which provides up to three orders of magnitude improvements in policy learning speed, making EUREKA a broadly applicable algorithm that Naturally expands as the amount of calculation increases.

as shown in picture 2. The researchers are committed to open-sourcing all prompts, environments, and generated reward functions to facilitate further research on LLM-based reward design.

Method introduction
EUREKA can independently write the reward algorithm, specifically How to achieve this, let’s see below.
EUREKA consists of three algorithmic components: 1) using the environment as context, thereby supporting zero-shot generation of executable rewards; 2) evolutionary search, iteratively proposing and refining reward candidates; 3 ) rewards reflection and supports fine-grained reward improvements.
Environment as context
This article recommends directly providing the original environment code as context. With only minimal instructions, EUREKA can generate rewards in different environments with zero samples. An example of EUREKA output is shown in Figure 3. EUREKA expertly combines existing observation variables (e.g., fingertip position) in the provided environment code and produces a valid reward code - all without any environment-specific hint engineering or reward templates.
However, the generated reward may not always be executable on the first try, and even if it is executable, it may be sub-optimal. This raises a question, that is, how to effectively overcome the suboptimality of single-sample reward generation?

Evolutionary Search
Then, the paper introduces how evolutionary search is Solving problems such as the sub-optimal solutions mentioned above. They are refined in such a way that in each iteration, EUREKA samples several independent outputs of the LLM (line 5 in Algorithm 1). Since each iteration (generations) is independently and identically distributed, as the number of samples increases, the probability of errors in all reward functions in the iteration decreases exponentially.


##Bonus Reflection
To provide more complex and targeted reward analysis, this paper proposes building automated feedback to summarize policy training dynamics in text. Specifically, given that the EUREKA reward function requires individual components in the reward program (such as the reward components in Figure 3), we track the scalar values of all reward components at intermediate policy checkpoints throughout the training process.
Although it is very simple to build this kind of reward reflection process, due to the dependencies of the reward optimization algorithm, this way of building it is very important. That is, whether the reward function is efficient is affected by the specific choice of RL algorithm, and the same reward can behave very differently even under the same optimizer given differences in hyperparameters. By detailing how RL algorithms optimize individual reward components, reward reflection enables EUREKA to produce more targeted reward edits and synthesize reward functions that better synergize with fixed RL algorithms.

Experiment
The experimental part conducts a comprehensive evaluation of Eureka, including the ability to generate reward functions , the ability to solve new tasks and the ability to integrate various human inputs.
The experimental environment includes 10 different robots and 29 tasks, among which these 29 tasks are implemented by the IsaacGym simulator. Experiments were conducted using 9 original environments from IsaacGym (Isaac), covering a variety of robot morphologies from quadrupeds, bipeds, quadcopters, manipulators, and dexterous hands of robots. In addition to this, the paper ensures depth of evaluation by including 20 tasks from the Dexterity benchmark.

Eureka can generate superhuman level reward functions. Across 29 tasks, the reward function given by Eureka performed better than the reward written by experts on 83% of the tasks, with an average improvement of 52%. In particular, Eureka achieves greater gains in the high-dimensional Dexterity benchmark environment.

Eureka is able to evolve reward searches so that rewards continue to improve over time. By combining large-scale reward search and detailed reward reflection feedback, Eureka gradually produces better rewards, eventually surpassing human levels.

Eureka also generates novel rewards. This paper evaluates the novelty of Eureka rewards by computing the correlation between Eureka rewards and human rewards on all Isaac tasks. As shown in the figure, Eureka mainly generates weakly correlated reward functions, which outperform human reward functions. Additionally, we observe that the more difficult the task, the less relevant the Eureka reward is. In some cases, Eureka rewards were even negatively correlated with human rewards, yet significantly outperformed them.

#To realize that the robot's dexterous hand can continuously turn the pen, the operating program needs to have as many cycles as possible. This paper addresses this task by (1) instructing Eureka to generate a reward function used to redirect pens to random target configurations, and then (2) using Eureka rewards to fine-tune this pre-trained policy to achieve the desired pen sequence-rotation configuration. . As shown in the figure, the Eureka spinner quickly adapted to the strategy and successfully rotated for many cycles in succession. In contrast, neither pre-trained nor learned-from-scratch policies can complete a single epoch of rotation.
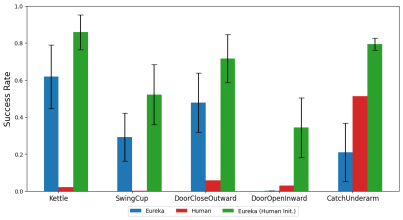
This paper also investigates whether it is advantageous for Eureka to start with a human reward function initialization. As shown, Eureka improves and benefits from human rewards regardless of their quality.

Eureka also implements RLHF, which can combine human feedback to modify rewards, thereby gradually guiding the agent to complete safer and more human-friendly tasks. Behavior. The example shows how Eureka teaches a humanoid robot to run upright with some human feedback that replaces the previous automatic reward reflection.

Humanoid robot learns running gait through Eureka.
For more information, please refer to the original paper.
The above is the detailed content of With GPT-4, the robot has learned how to spin a pen and plate walnuts.. For more information, please follow other related articles on the PHP Chinese website!

 从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM
从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM1 前言在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM
普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。陈丹琦 普
 解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM
解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,
 Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM
Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM3月27号,Stability AI的创始人兼首席执行官Emad Mostaque在一条推文中宣布,Stable Diffusion XL 现已可用于公开测试。以下是一些事项:“XL”不是这个新的AI模型的官方名称。一旦发布稳定性AI公司的官方公告,名称将会更改。与先前版本相比,图像质量有所提高与先前版本相比,图像生成速度大大加快。示例图像让我们看看新旧AI模型在结果上的差异。Prompt: Luxury sports car with aerodynamic curves, shot in a
 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM
五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM人工智能就是一个「拼财力」的行业,如果没有高性能计算设备,别说开发基础模型,就连微调模型都做不到。但如果只靠拼硬件,单靠当前计算性能的发展速度,迟早有一天无法满足日益膨胀的需求,所以还需要配套的软件来协调统筹计算能力,这时候就需要用到「智能计算」技术。最近,来自之江实验室、中国工程院、国防科技大学、浙江大学等多达十二个国内外研究机构共同发表了一篇论文,首次对智能计算领域进行了全面的调研,涵盖了理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。论文链接:https://spj.scien
 什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM
什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM译者 | 李睿审校 | 孙淑娟近年来, Transformer 机器学习模型已经成为深度学习和深度神经网络技术进步的主要亮点之一。它主要用于自然语言处理中的高级应用。谷歌正在使用它来增强其搜索引擎结果。OpenAI 使用 Transformer 创建了著名的 GPT-2和 GPT-3模型。自从2017年首次亮相以来,Transformer 架构不断发展并扩展到多种不同的变体,从语言任务扩展到其他领域。它们已被用于时间序列预测。它们是 DeepMind 的蛋白质结构预测模型 AlphaFold
 AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM
AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM说起2010年南非世界杯的最大网红,一定非「章鱼保罗」莫属!这只位于德国海洋生物中心的神奇章鱼,不仅成功预测了德国队全部七场比赛的结果,还顺利地选出了最终的总冠军西班牙队。不幸的是,保罗已经永远地离开了我们,但它的「遗产」却在人们预测足球比赛结果的尝试中持续存在。在艾伦图灵研究所(The Alan Turing Institute),随着2022年卡塔尔世界杯的持续进行,三位研究员Nick Barlow、Jack Roberts和Ryan Chan决定用一种AI算法预测今年的冠军归属。预测模型图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver CS6
Visual web development tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

