

 Technology peripheralsAIPractice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platform
Technology peripheralsAIPractice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platformPractice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platform


1. Historical development of multi-modal large models

The picture above The photo is of the first Artificial Intelligence Workshop held at Dartmouth College in the United States in 1956. This conference is also considered to have kicked off the field of artificial intelligence. The attendees were mainly pioneers in the field of symbolic logic (except for those in the middle of the front row). neurobiologist Peter Milner).
However, this symbolic logic theory could not be realized for a long time, and even the first AI winter period came in the 1980s and 1990s. It was not until the recent implementation of large language models that we discovered that neural networks really carry this logical thinking. The work of neurobiologist Peter Milner inspired the later development of artificial neural networks, and it was for this reason that he was invited to participate in this academic seminar. meeting.

In 2012, Tesla’s self-driving director Andrew posted the picture above on his blog, showing then-U.S. President Obama joking with his subordinates. For artificial intelligence to understand this picture, it is not only a visual perception task, because in addition to identifying objects, it also needs to understand the relationship between them; only by knowing the physical principles of the scale can we know the story described in the picture: Obama steps on The man on the scale gained weight, causing him to make this strange expression while others laughed. Such logical thinking has obviously gone beyond the scope of pure visual perception. Therefore, visual cognition and logical thinking must be combined to get rid of the embarrassment of "artificial mental retardation". The importance and difficulty of multi-modal large models also reflect it's here.

The above picture is an anatomical structure diagram of the human brain. The language logical area in the picture corresponds to the large language model, while other areas are respectively Corresponding to different senses, including vision, hearing, touch, movement, memory, etc. Although the artificial neural network is not a brain neural network in the true sense, we can still get some inspiration from it, that is, when constructing a large model, different functions can be combined together. This is also the basic idea of multi-modal model construction.
1. What can multi-modal large models do?

Multi-modal large models can do a lot of things for us, such as video understanding. Large models can help us summarize the summary and key information of the video, This saves us time watching videos; large models can also help us perform post-analysis of videos, such as program classification, program ratings statistics, etc.; in addition, Vincentian graphs are also an important application field of multi-modal large models.
If the large model is combined with the movement of people or robots, an embodied intelligence will be generated, just like a person, planning the best path based on past experience. methods and apply them to new scenarios to solve some problems that have not been encountered before while avoiding risks; you can even modify the original plan during the execution process until you finally achieve success. This is also an application scenario with broad prospects.
2. Multi-modal large model

The above picture is some important nodes in the development process of multi-modal large model :
- The 2020 ViT model (Vision Transformer) is the beginning of a large model. For the first time, the Transformer architecture is used for other types of data (visual data) in addition to language and logical processing, and it is displayed It has good generalization ability;
- Then through the OpenAI open source CLIP model, it was once again proved that through the use of ViT and large language model, visual tasks have been achieved a lot. Strong long-tail generalization ability, that is, inferring previously unseen categories through common sense
- By 2023, a variety of multi-modal large models It gradually emerged, from PaLM-E (robot), to whisper (speech recognition), to ImageBind (image alignment), to Sam (semantic segmentation), and finally to geographical images; it also includes Microsoft's unified multi-modal architecture Kosmos2 , multimodal large models are developing rapidly.
- # Tesla also proposed the vision of a universal world model at CVPR in June.
As can be seen from the above figure, in just half a year, the large model has undergone many changes, and its iteration speed is very fast.
3. Modal alignment architecture

The above picture is multi-modal The general architecture diagram of a large state model includes a language model and a visual model. The alignment model is learned through a fixed language model and a fixed visual model; and alignment is to combine the vector space of the visual model and the vector space of the language model, and then in The understanding of the internal logical relationship between the two is completed in a unified vector space.
Both the Flamingo model and the BLIP2 model shown in the figure adopt similar structures (the Flamingo model uses the Perceiver architecture, while the BLIP2 model uses an improved version of the Transformer architecture); and then through various comparisons The learning method carries out pre-training, conducts a large amount of learning on a large number of tokens, and obtains better alignment effects; finally, the model is fine-tuned according to specific tasks.
2. Jiuzhang Yunji DataCanvas’ multi-modal large model platform
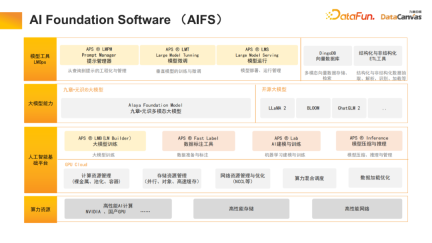
1. AI Foundation Software (AIFS)
Jiuzhang Yunji DataCanvas is an artificial intelligence basic software provider. It also provides computing resources (including GPU clusters), performs high-performance storage and network optimization, and provides large model training on this basis. Tools, including data annotation modeling experiment sandbox, etc. Jiuzhang Yunji DataCanvas not only supports common open source large models on the market, but also independently develops Yuanshi multi-modal large models. At the application layer, tools are provided to manage prompt words, fine-tune the model, and provide a model operation and maintenance mechanism. At the same time, a multi-modal vector database was also open sourced to enrich the basic software architecture.
2. Model tool LMOPS
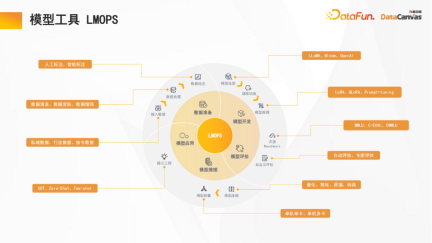
九章云Ji DataCanvas focuses on the optimization of the entire life cycle of development, including data preparation (data annotation supports manual annotation and intelligent annotation), model development, model evaluation (including horizontal and vertical evaluation), model reasoning (supports model quantification, knowledge distillation, etc. Accelerated inference mechanism), model application, etc.
3. LMB – Large Model Builder

When building the model, a lot of distributed Efficient optimization work, including data parallelism, Tensor parallelism, pipeline parallelism, etc. These distributed optimization tasks are completed with one click and support visual control, which can greatly reduce labor costs and improve development efficiency.
4. LMB –Large Model Builder

Tuning of large models has also been optimized, including common continue training, supervisor tuning, and human feedback in reinforcement learning. In addition, many optimizations have been made for Chinese, such as the automatic expansion of Chinese vocabulary. Because many Chinese words are not included in large open source models, these words may be split into multiple tokens; automatically expanding these words can allow the model to better use these words.
5. LMS – Large Model Serving

Serving of large models is also a very important component In part, the platform has also made a lot of optimizations in aspects such as model quantification and knowledge distillation, which greatly reduces the computing cost. It also accelerates the transformer and reduces its calculation amount through layer-by-layer knowledge distillation. At the same time, a lot of pruning work has been done (including structured pruning, sparse pruning, etc.), which has greatly improved the inference speed of large models.
In addition, the interactive dialogue process has also been optimized. For example, in a multi-turn dialogue Transformer, the key and value of each tensor can be remembered without repeated calculations. Therefore, it can be stored in Vector DB to realize the conversation history memory function and improve the user experience during the interaction process.
6. Prompt Manager
Prompt Manager, a large model prompt word design and construction tool, helps users design better prompt words and guide Large models generate more accurate, reliable, and expected output. This tool can not only provide development toolkit development mode for technical personnel, but also provide human-computer interaction operation mode for non-technical personnel, meeting the needs of different groups of people for using large models.
Its main functions include: AI model management, scene management, prompt word template management, prompt word development and prompt word application, etc.

The platform provides commonly used prompt word management tools to achieve version control, and provides commonly used templates to speed up the implementation of prompt words.
3. Practice of Jiuzhang Yunji DataCanvas multi-modal large model
1. Multi-modal large model - with memory
After introducing the platform functions, I will share the multi-modal large model development practice.

The picture above is the basic framework of the Jiuzhang Yunji DataCanvas multi-modal model, which is similar to many other models. What is different about the modal large model is that it contains memory, which can improve the reasoning capabilities of the open source large model.
Generally, the number of parameters of large open source models is relatively low. If a part of the parameters are used for memory, its reasoning ability will be significantly reduced. If memory is added to a large open source model, reasoning and memory capabilities will be improved at the same time.
In addition, similar to most models, multi-modal large models will also fix the large language model and fixed data encoding, and conduct separate modular training for the alignment function; therefore, all different The data modes will be aligned to the logical parts of the text; in the reasoning process, the language is first translated, then fused, and finally the reasoning work is performed.
2. Unstructured data ETL Pipeline

Due to the combination of our DingoDB multi-modal vector database It has multi-modal and ETL functions, so it can provide good unstructured data management capabilities. The platform provides pipeline ETL functions and has made many optimizations, including operator compilation, parallel processing, and cache optimization.
In addition, the platform provides a Hub that can reuse pipelines to achieve the most efficient development experience. At the same time, it supports many encoders on Huggingface, which can achieve optimal encoding of different modal data.
3. Multi-modal large model construction method
Jiuzhang Yunji DataCanvas uses the Yuanshi multi-modal large model as a base to support Users can choose other open source large models and also support users to use their own modal data for training.
The construction of a large multi-modal model is roughly divided into three stages:
- The first stage: fixed large language model and modal coding Machine training alignment and query;
- Second stage (optional, supports multi-modal search): fixed large language model, modal encoder, alignment and Query module, training retrieval module;
- The third stage (optional, for specific tasks): Instructions to fine-tune the large language model.
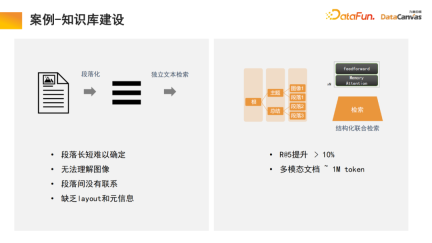
4. Case-Knowledge Base Construction
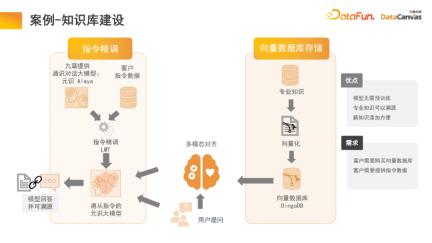
The memory architecture in large models can help us realize the construction of multi-modal knowledge base, which is actually the application of the model. Zhihu is a typical multi-modal knowledge base application module, and its professional knowledge can be traced.
In order to ensure the certainty and security of knowledge, it is often necessary to trace the source of professional knowledge. The knowledge base can help us realize this function, and it will also be more convenient to add new knowledge. , there is no need to modify the model parameters, just add the knowledge directly to the database.
Specifically, professional knowledge is used through the encoder to make different encoding choices, and at the same time, unified evaluation is performed based on different evaluation methods, and the selection of the encoder is realized through one-click evaluation. Finally, the encoder vectorization is applied and stored in the DingoDB multi-modal vector database, and then relevant information is extracted through the multi-modal module of the large model, and reasoning is performed through the language model.
The last part of the model often requires fine-tuning of instructions. Since the needs of different users are different, the entire multi-modal large model needs to be fine-tuned. Due to the special advantages of multimodal knowledge bases in organizing information, the model has the ability to learn and retrieve. This is also an innovation we made in the process of paragraphing text.
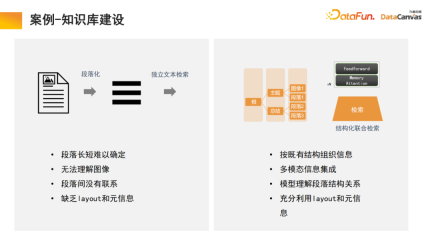
The general knowledge base is to divide the document into paragraphs, and then unlock each paragraph independently. This method is easily interfered by noise, and for many large documents, it is difficult to determine the standard for paragraph division.
In our model, the retrieval module performs learning, and the model automatically finds suitable structured information organization. For a specific product, start from the product manual, first locate the large catalog paragraph, and then locate the specific paragraph. At the same time, due to multi-modal information integration, in addition to text, it often also contains images, tables, etc., which can also be vectorized and combined with Meta information to achieve joint retrieval, thus improving retrieval efficiency.
It is worth mentioning that the retrieval module uses a memory attention mechanism, which can increase the recall rate by 10% compared to similar algorithms; at the same time, the memory attention mechanism can be used for multi-modal Document processing is also a very advantageous aspect.
##4. Thoughts and prospects for the future
1. Enterprise data management - Knowledge base
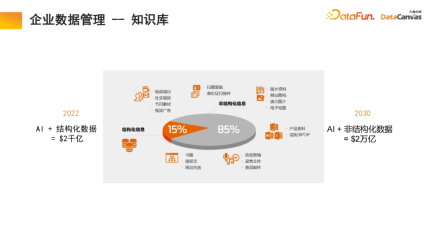
85% of data in an enterprise is unstructured data, and only 15% is structured data . In the past 20 years, artificial intelligence has mainly revolved around structured data. Unstructured data is very difficult to utilize and requires a lot of energy and cost to convert it into structured data. With the help of multi-modal large models and multi-modal knowledge bases, and through the new paradigm of artificial intelligence, the utilization of unstructured data in internal management of enterprises can be greatly improved, which may bring about a 10-fold increase in value in the future.
2. Knowledge base --> Agent

Multimodal knowledge base As the basis of the intelligent agent, the above functions such as R&D agent, customer service agent, sales agent, legal agent, human resources agent, and enterprise operation and maintenance agent can all be operated through the knowledge base.
Taking the sales agent as an example, a common architecture includes two agents existing at the same time, one of which is responsible for decision-making and the other is responsible for the analysis of the sales stage. Both modules can search for relevant information through multi-modal knowledge bases, including product information, historical sales statistics, customer portraits, past sales experience, etc. This information is integrated to help these two agents do the best and most correct work These decisions, in turn, help users obtain the best sales information, which is then recorded into a multi-modal database. This cycle continues to improve sales performance.
We believe that the most valuable companies in the future will be those that put intelligence into practice. I hope Jiuzhang Yunji DataCanvas can accompany you all the way and help each other.
The above is the detailed content of Practice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platform. For more information, please follow other related articles on the PHP Chinese website!

![Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AM
Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AMChatGPT is not accessible? This article provides a variety of practical solutions! Many users may encounter problems such as inaccessibility or slow response when using ChatGPT on a daily basis. This article will guide you to solve these problems step by step based on different situations. Causes of ChatGPT's inaccessibility and preliminary troubleshooting First, we need to determine whether the problem lies in the OpenAI server side, or the user's own network or device problems. Please follow the steps below to troubleshoot: Step 1: Check the official status of OpenAI Visit the OpenAI Status page (status.openai.com) to see if the ChatGPT service is running normally. If a red or yellow alarm is displayed, it means Open
 Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AM
Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AMOn 10 May 2025, MIT physicist Max Tegmark told The Guardian that AI labs should emulate Oppenheimer’s Trinity-test calculus before releasing Artificial Super-Intelligence. “My assessment is that the 'Compton constant', the probability that a race to
 An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AM
An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AMAI music creation technology is changing with each passing day. This article will use AI models such as ChatGPT as an example to explain in detail how to use AI to assist music creation, and explain it with actual cases. We will introduce how to create music through SunoAI, AI jukebox on Hugging Face, and Python's Music21 library. Through these technologies, everyone can easily create original music. However, it should be noted that the copyright issue of AI-generated content cannot be ignored, and you must be cautious when using it. Let’s explore the infinite possibilities of AI in the music field together! OpenAI's latest AI agent "OpenAI Deep Research" introduces: [ChatGPT]Ope
 What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AM
What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AMThe emergence of ChatGPT-4 has greatly expanded the possibility of AI applications. Compared with GPT-3.5, ChatGPT-4 has significantly improved. It has powerful context comprehension capabilities and can also recognize and generate images. It is a universal AI assistant. It has shown great potential in many fields such as improving business efficiency and assisting creation. However, at the same time, we must also pay attention to the precautions in its use. This article will explain the characteristics of ChatGPT-4 in detail and introduce effective usage methods for different scenarios. The article contains skills to make full use of the latest AI technologies, please refer to it. OpenAI's latest AI agent, please click the link below for details of "OpenAI Deep Research"
 Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AM
Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AMChatGPT App: Unleash your creativity with the AI assistant! Beginner's Guide The ChatGPT app is an innovative AI assistant that handles a wide range of tasks, including writing, translation, and question answering. It is a tool with endless possibilities that is useful for creative activities and information gathering. In this article, we will explain in an easy-to-understand way for beginners, from how to install the ChatGPT smartphone app, to the features unique to apps such as voice input functions and plugins, as well as the points to keep in mind when using the app. We'll also be taking a closer look at plugin restrictions and device-to-device configuration synchronization
 How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AM
How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AMChatGPT Chinese version: Unlock new experience of Chinese AI dialogue ChatGPT is popular all over the world, did you know it also offers a Chinese version? This powerful AI tool not only supports daily conversations, but also handles professional content and is compatible with Simplified and Traditional Chinese. Whether it is a user in China or a friend who is learning Chinese, you can benefit from it. This article will introduce in detail how to use ChatGPT Chinese version, including account settings, Chinese prompt word input, filter use, and selection of different packages, and analyze potential risks and response strategies. In addition, we will also compare ChatGPT Chinese version with other Chinese AI tools to help you better understand its advantages and application scenarios. OpenAI's latest AI intelligence
 5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AM
5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AMThese can be thought of as the next leap forward in the field of generative AI, which gave us ChatGPT and other large-language-model chatbots. Rather than simply answering questions or generating information, they can take action on our behalf, inter
 An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AM
An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AMEfficient multiple account management techniques using ChatGPT | A thorough explanation of how to use business and private life! ChatGPT is used in a variety of situations, but some people may be worried about managing multiple accounts. This article will explain in detail how to create multiple accounts for ChatGPT, what to do when using it, and how to operate it safely and efficiently. We also cover important points such as the difference in business and private use, and complying with OpenAI's terms of use, and provide a guide to help you safely utilize multiple accounts. OpenAI


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Notepad++7.3.1
Easy-to-use and free code editor

WebStorm Mac version
Useful JavaScript development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

