



With the advent of large-scale language models such as GPT-3, major breakthroughs have been made in the field of natural language processing (NLP). These language models have the ability to generate human-like text and have been widely used in various scenarios such as chatbots and translation

However, when it comes to specialization and customization When used in application scenarios, general-purpose large language models may be insufficient in terms of professional knowledge. Fine-tuning these models with specialized corpora is often expensive and time-consuming. "Retrieval Enhanced Generation" (RAG) provides a new technology solution for professional applications.

Below we mainly introduce how RAG works, and use a practical example to use the product manual as a professional corpus and use GPT-3.5 Turbo as a question and answer model to verify its effectiveness sex.
Case: Develop a chatbot that can answer questions related to a specific product. The enterprise has a unique user manual
RAG INTRODUCTION
RAG provides an effective solution for domain-specific questions and answers. It mainly converts industry knowledge into vectors for storage and retrieval, combines the retrieval results with user questions to form prompt information, and finally uses large models to generate appropriate answers. By combining the retrieval mechanism and language model, the responsiveness of the model is greatly enhanced
The steps to create a chatbot program are as follows:
- Read the PDF (user manual PDF file) and use chunk_size Tokenize 1000 tokens.
- Create vectors (you can use OpenAI EmbeddingsAPI to create vectors).
- Store vectors in the local vector library. We will use ChromaDB as the vector database (the vector database can also be replaced by Pinecone or other products).
- User issues prompt with query/question.
- Retrieve knowledge context data from the vector database based on the user's questions. This knowledge context data will be used in conjunction with the cue words in subsequent steps to enhance the cue words, often referred to as contextual enrichment.
- The prompt word containing the user question is passed to LLM along with enhanced contextual knowledge
- LLM answers based on this context.
Hands-on development
(1) Set up a Python virtual environment Set up a virtual environment to sandbox our Python to avoid any version or dependency conflicts. Execute the following command to create a new Python virtual environment.
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
The content that needs to be rewritten is: (2) Generate OpenAI key
Using GPT requires an OpenAI key for access

The content that needs to be rewritten is: (3) Installation of dependent libraries
Various dependencies required by the installation program. Includes the following libraries:
- lanchain: A framework for developing LLM applications.
- chromaDB: This is VectorDB for persistent vector embeddings.
- unstructured: used to preprocess Word/PDF documents.
- tiktoken: Tokenizer framework
- pypdf: A framework for reading and processing PDF documents.
- openai: Access the OpenAI framework.
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
Create an environment variable to store the OpenAI key.
export OPENAI_API_KEY=<openai-key></openai-key>
(4) Convert the user manual PDF file into a vector and store it in ChromaDB
Import all the dependent libraries and functions that need to be used
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
Read PDF, tokenize document and split document.
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
Create a chroma collection and a local directory to store chroma data. Then, create a vector (embeddings) and store it in ChromaDB.
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()
After executing this code, you should see a folder that has been created to store the vectors.

After storing the vector embedding in ChromaDB, you can use the ConversationalRetrievalChain API in LangChain to start a chat history component
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
After initializing langchan, we You can use it to chat/Q A. In the code below, a question entered by the user is accepted, and after the user enters 'done', the question is passed to LLM to get the reply and print it out.
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])


In short
RAG combines the advantages of language models such as GPT with the advantages of information retrieval. By utilizing specific knowledge context information to enhance the richness of prompt words, the language model is able to generate more accurate answers relevant to the knowledge context. RAG provides a more efficient and cost-effective solution than "fine-tuning", providing customizable interactive solutions for industry applications or enterprise applications
The above is the detailed content of Improve engineering efficiency - enhanced search generation (RAG). For more information, please follow other related articles on the PHP Chinese website!

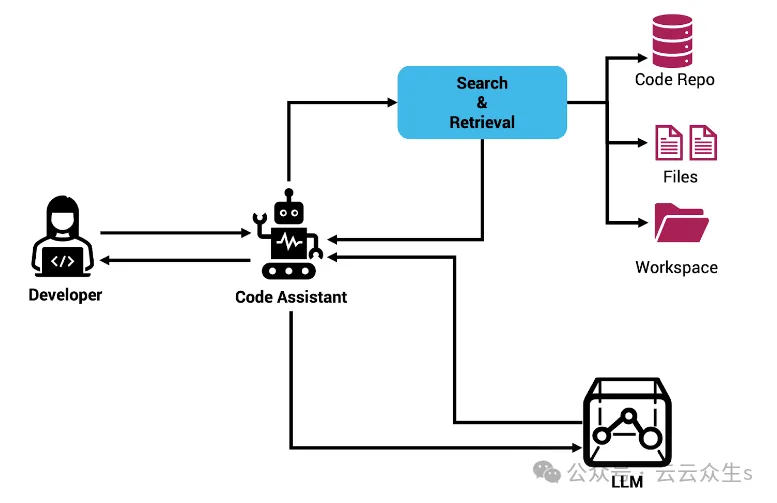 使用Rag和Sem-Rag提供上下文增强AI编码助手Jun 10, 2024 am 11:08 AM
使用Rag和Sem-Rag提供上下文增强AI编码助手Jun 10, 2024 am 11:08 AM通过将检索增强生成和语义记忆纳入AI编码助手,提升开发人员的生产力、效率和准确性。译自EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG,作者JanakiramMSV。虽然基本AI编程助手自然有帮助,但由于依赖对软件语言和编写软件最常见模式的总体理解,因此常常无法提供最相关和正确的代码建议。这些编码助手生成的代码适合解决他们负责解决的问题,但通常不符合各个团队的编码标准、惯例和风格。这通常会导致需要修改或完善其建议,以便将代码接受到应
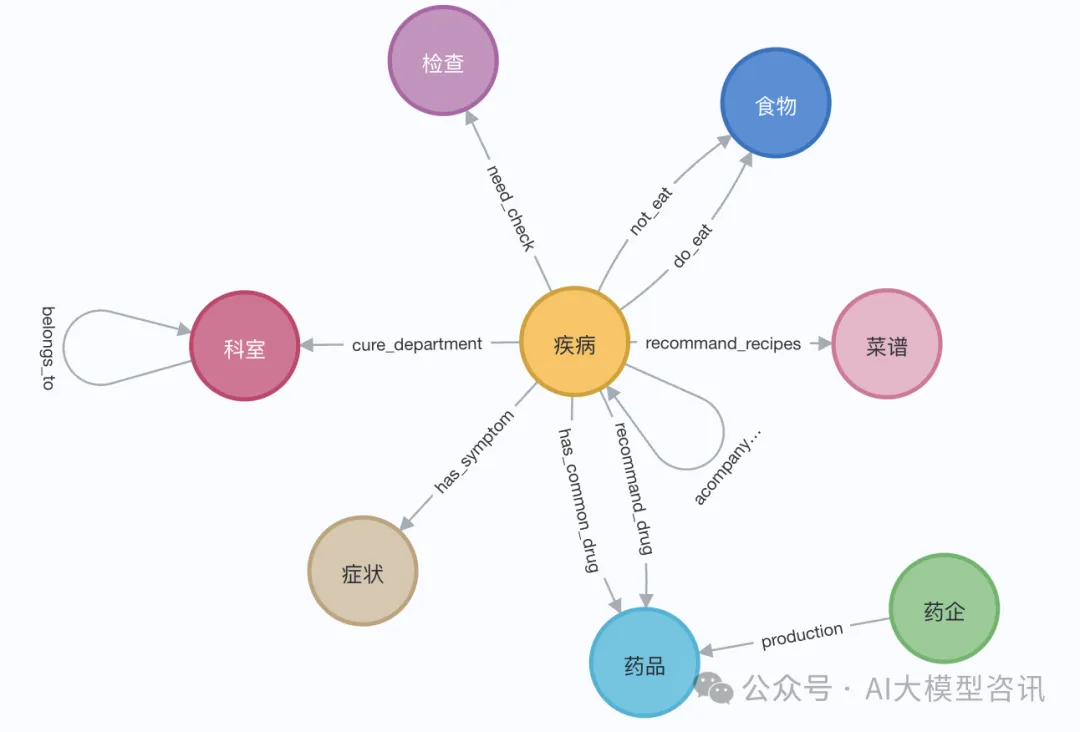 知识图谱检索增强的GraphRAG(基于Neo4j代码实现)Jun 12, 2024 am 10:32 AM
知识图谱检索增强的GraphRAG(基于Neo4j代码实现)Jun 12, 2024 am 10:32 AM图检索增强生成(GraphRAG)正逐渐流行起来,成为传统向量搜索方法的有力补充。这种方法利用图数据库的结构化特性,将数据以节点和关系的形式组织起来,从而增强检索信息的深度和上下文关联性。图在表示和存储多样化且相互关联的信息方面具有天然优势,能够轻松捕捉不同数据类型间的复杂关系和属性。而向量数据库则处理这类结构化信息时则显得力不从心,它们更专注于处理高维向量表示的非结构化数据。在RAG应用中,结合结构化化的图数据和非结构化的文本向量搜索,可以让我们同时享受两者的优势,这也是本文将要探讨的内容。构
 利用知识图谱增强RAG模型的能力和减轻大模型虚假印象Jan 14, 2024 pm 06:30 PM
利用知识图谱增强RAG模型的能力和减轻大模型虚假印象Jan 14, 2024 pm 06:30 PM在使用大型语言模型(LLM)时,幻觉是一个常见问题。尽管LLM可以生成流畅连贯的文本,但其生成的信息往往不准确或不一致。为了防止LLM产生幻觉,可以利用外部的知识来源,比如数据库或知识图谱,来提供事实信息。这样一来,LLM可以依赖这些可靠的数据源,从而生成更准确和可靠的文本内容。向量数据库和知识图谱向量数据库向量数据库是一组表示实体或概念的高维向量。它们可以用于度量不同实体或概念之间的相似性或相关性,通过它们的向量表示进行计算。一个向量数据库可以根据向量距离告诉你,“巴黎”和“法国”比“巴黎”和
 理解GraphRAG(一):RAG的挑战Apr 30, 2024 pm 07:10 PM
理解GraphRAG(一):RAG的挑战Apr 30, 2024 pm 07:10 PMRAG(RiskAssessmentGrid)是一种通过外部知识源增强现有大型语言模型(LLM)的方法,以提供和上下文更相关的答案。在RAG中,检索组件获取额外的信息,响应基于特定来源,然后将这些信息输入到LLM提示中,以使LLM的响应基于这些信息(增强阶段)。与其他技术(例如微调)相比,RAG更经济。它还有减少幻觉的优势,通过基于这些信息(增强阶段)提供额外的上下文——你RAG成为今天LLM任务的(如推荐、文本提取、情感分析等)的流程方法。如果我们进一步分解这个想法,根据用户意图,我们通常会查
 构建多模态RAG系统的方法:使用CLIP和LLMJan 13, 2024 pm 10:24 PM
构建多模态RAG系统的方法:使用CLIP和LLMJan 13, 2024 pm 10:24 PM我们将讨论使用开源的大型语言多模态模型(LargeLanguageMulti-Modal)构建检索增强生成(RAG)系统的方法。我们的重点是在不依赖LangChain或LLlamaindex的情况下实现这一目标,以避免增加更多的框架依赖。什么是RAG在人工智能领域,检索增强生成(retrieve-augmentedgeneration,RAG)技术的出现为大型语言模型(LargeLanguageModels)带来了变革性的改进。RAG的本质是通过允许模型从外部源动态检索实时信息,从而增强人工智能
 深入研究RAG和向量数据库:实现低成本快速定制大模型的关键Nov 13, 2023 pm 03:29 PM
深入研究RAG和向量数据库:实现低成本快速定制大模型的关键Nov 13, 2023 pm 03:29 PM如今,在人工智能领域中,备受关注的是大规模模型。然而,高昂的培训费用和漫长的培训时间等因素已成为制约大多数企业参与大规模模型领域的关键障碍这种背景下,向量数据库凭借其独特的优势,成为解决低成本快速定制大模型问题的关键所在。向量数据库是一种专门用于存储和处理高维向量数据的技术。它采用高效的索引和查询算法,实现了海量数据的快速检索和分析。如此优秀的性能之外,向量数据库还可以为特定领域和任务提供定制化的解决方案。腾讯、阿里等科技巨头纷纷投入研发向量数据库,希望在大模型领域取得突破。许多中小型公司也利用
 除了RAG,还有这五种方法消除大模型幻觉Jun 10, 2024 pm 08:25 PM
除了RAG,还有这五种方法消除大模型幻觉Jun 10, 2024 pm 08:25 PM出品|51CTO技术栈(微信号:blog51cto)众所周知,LLM会产生幻觉——即生成不正确、误导性或无意义的信息。有意思的是,一些人,如OpenAI的CEOSamAltman,将AI的想象视为创造力,而另一些人则认为想象可能有助于做出新的科学发现。然而,在大多数情况下,提供正确回答至关重要,幻觉并不是一项特性,而是一种缺陷。那么,如何减少LLM的幻觉呢?长上下文?RAG?微调?其实,长上下文LLMs并非万无一失,向量搜索RAG也不尽如人意,而微调则伴随着其自身的挑战和限制。下面是一些可以用来
 大学生用GPT-3写论文遭重罚,拒不承认!大学论文已「死」,ChatGPT或引发学术圈大地震Apr 11, 2023 pm 10:01 PM
大学生用GPT-3写论文遭重罚,拒不承认!大学论文已「死」,ChatGPT或引发学术圈大地震Apr 11, 2023 pm 10:01 PMChatGPT诞生之后,用自己强悍的文本创作能力,不断刷新着我们的认知。AI即将给大学校园带来怎样的爆炸性改变?似乎还没人做好准备。Nature已经发文,担心ChatGPT会成为学生写论文的工具。文章链接:https://www.nature.com/articles/d41586-022-04397-7无独有偶,一位加拿大作家Stephen Marche痛心疾首地呼吁:大学的论文已死!用AI写论文,太容易了假设你是一位教育学教授,你为学术布置了一篇关于学习风格的论文。一位学生提交了一篇文章,开


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

WebStorm Mac version
Useful JavaScript development tools

Atom editor mac version download
The most popular open source editor

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

