
Home >Technology peripherals >AI >Looking at the attack surface threats and management of AI applications from the STRIDE threat model
Looking at the attack surface threats and management of AI applications from the STRIDE threat model

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-10-13 14:29:091646browse

STRIDE is a popular threat modeling framework that is currently widely used to help organizations proactively discover threats, attacks, vulnerabilities, and countermeasures that may impact their application systems. If each letter in "STRIDE" is separated, it represents counterfeiting, tampering, denial, information disclosure, denial of service and privilege elevation. As a key component, many security practitioners call for the need to identify and protect the security risks of these systems as quickly as possible. The STRIDE framework can help organizations better understand possible attack paths in AI systems and enhance the security and reliability of their AI applications. In this article, security researchers use the STRIDE model framework to comprehensively map the attack surface in AI system applications (see the table below), and conduct research on new attack categories and attack scenarios specific to AI technology. With the continuous development of AI technology, more new models, applications, attacks and operation modes will appear
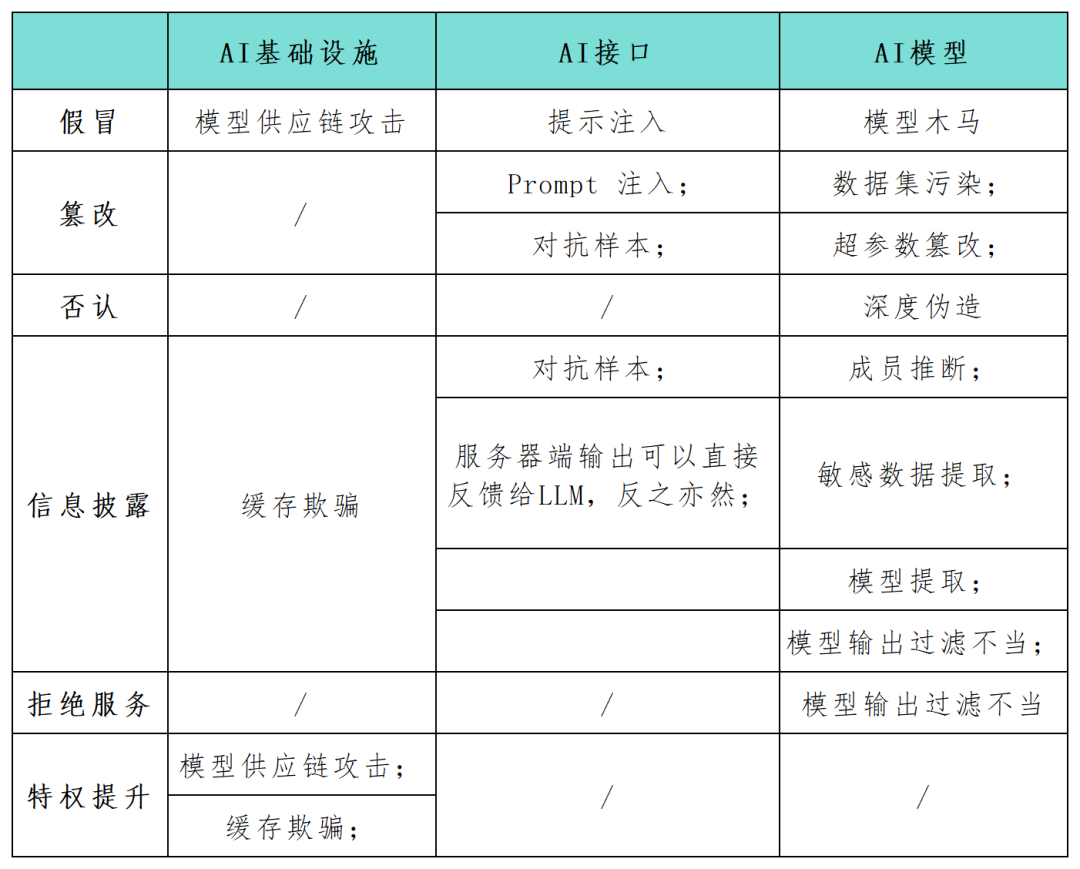 Attacks against AI infrastructure
Attacks against AI infrastructure
AI Researcher Andrej Karpathy pointed out that the arrival of a new generation of deep neural network models marks a paradigm shift in the traditional way of conceptualizing software production. Developers are increasingly embedding AI models into complex systems that are expressed not in the language of loops and conditionals but in continuous vector spaces and numerical weights, creating new possibilities for vulnerability exploitation. pathways and gave rise to new threat categories.
If an attacker is able to tamper with the input and output of the model, or change certain setting parameters of the AI infrastructure, it may lead to harmful and unpredictable malicious results, such as unexpected behavior, interaction with the AI agent, and Impact on linked components
Rewritten content: Impersonation refers to an attacker simulating a trusted source during the model or component delivery process to introduce malicious elements into the AI system. This technique enables attackers to inject malicious elements into AI systems. At the same time, impersonation can also be used as part of a model supply chain attack. For example, if a threat actor infiltrates a third-party model provider like Huggingface, they can control the surrounding infrastructure by infecting the upstream model when the code output by the AI is executed downstream. Information disclosure. Sensitive data exposure is a common problem for any network application, including applications that serve AI systems. In March 2023, a misconfiguration of Redis caused a web server to expose private data. In general, web applications are susceptible to classic OWASP top ten vulnerabilities such as injection attacks, cross-site scripting, and insecure direct object references. The same situation applies to web applications that serve AI systems.
Denial of Service (DoS). DoS attacks also pose a threat to artificial intelligence applications. Attackers make artificial intelligence services unusable by flooding the model provider's infrastructure with large amounts of traffic. Resilience is a basic requirement to achieve security when designing infrastructure and applications for artificial intelligence systems, but it is not enough
Attacks against model training and inference
For trained AI models As well as newer third-party generative AI systems, there are also the following attack surface threats:
Data set pollution and hyperparameter tampering. AI models are susceptible to specific threats during the training and inference phases. Dataset pollution and hyperparameter tampering are attacks under the STRIDE tampering category, which refers to threat actors injecting malicious data into training data sets. For example, an attacker could deliberately feed misleading images into a facial recognition AI, causing it to incorrectly identify individuals.
Adversarial examples have become a common threat of information leakage or tampering in AI applications. An attacker manipulates the input of a model to produce incorrect predictions or classification results. These behaviors may reveal sensitive information in the model's training data or trick the model into behaving in unexpected ways. For example, a team of researchers noted that adding small pieces of tape to stop signs could confuse image recognition models embedded in self-driving cars, potentially leading to serious consequences for model extraction. Model extraction is a newly discovered form of malicious attack that falls under STRIDE’s information disclosure category. The attacker's goal is to replicate proprietary trained machine learning models based on the model's queries and responses. They craft a series of queries and use the model's responses to build a replica of the target AI system. Such attacks may infringe intellectual property rights and may result in significant financial losses. At the same time, once an attacker has a copy of the model, he or she can also perform adversarial attacks or reverse-engineer the training data, creating other threats.
Attacks against large language models (LLM)
The popularity of large language models (LLM) has promoted the emergence of new AI attack methods. LLM development and integration is a very hot topic, so , new attack modes targeting it are emerging one after another. To this end, the OWASP research team has begun drafting the first version of the OWASP Top 10 LLM threat project.
Rewritten content: Input prompt attacks refer to behaviors such as jailbreaking, prompt leakage, and token smuggling. In these attacks, the attacker uses input prompts to trigger unexpected behavior of the LLM. Such manipulation could cause the AI to react inappropriately or leak sensitive information, consistent with the deception and information leakage categories in the STRIDE model. These attacks are particularly dangerous when AI systems are used in conjunction with other systems or within software application chains. Improper model output and filtering. A large number of API applications may be exploited in various non-publicly exposed ways. For example, frameworks like Langchain allow application developers to quickly deploy complex applications on public generative models and other public or private systems (such as databases or Slack integration). An attacker can construct a hint that tricks the model into making API queries that are not otherwise allowed. Likewise, an attacker can inject SQL statements into a generic unsanitized web form to execute malicious code.
Member reasoning and sensitive data extraction are things that need to be rewritten. An attacker can exploit membership inference attacks to binary-wise infer whether a specific data point is in the training set, raising privacy concerns. Data extraction attacks allow an attacker to completely reconstruct sensitive information about the training data from the model's responses. When LLM is trained on private datasets, a common scenario is that the model may have sensitive organizational data, and an attacker can extract confidential information by creating specific prompts
Rewritten content: The Trojan model is a A model that has been shown to be susceptible to training dataset contamination during the fine-tuning phase. Additionally, tampering with familiar public training data has proven feasible in practice. These weaknesses open the door to Trojan models for publicly available language models. On the surface, they function as expected for most tips, but they hide specific keywords introduced during fine-tuning. Once an attacker triggers these keywords, the Trojan model can perform various malicious behaviors, including elevating privileges, making the system unusable (DoS), or leaking private sensitive information.
Reference link:
The content that needs to be rewritten is: https://www.secureworks.com/blog/unravelling-the-attack-surface-of-ai-systems
The above is the detailed content of Looking at the attack surface threats and management of AI applications from the STRIDE threat model. For more information, please follow other related articles on the PHP Chinese website!