
Home >Technology peripherals >AI >New title: ADAPT: A preliminary exploration of end-to-end autonomous driving explainability
New title: ADAPT: A preliminary exploration of end-to-end autonomous driving explainability

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-10-11 12:57:041336browse
This article is reprinted with the authorization of the Autonomous Driving Heart public account. Please contact the source for reprinting.
The author’s personal thoughts
End-to-end is a very popular direction this year. This year’s CVPR best paper was also awarded to UniAD. However, there are also many problems in end-to-end, such as low interpretability, difficulty in training convergence, etc. Some scholars in the field have begun to gradually turn their attention to end-to-end interpretability. Today I will share with you the end-to-end interpretability. The latest explanatory work is ADAPT. This method is based on the Transformer architecture and outputs vehicle action descriptions and reasoning for each decision end-to-end through multi-task joint training. Some of the author’s thoughts on ADAPT are as follows:
- Here is the prediction using the 2D feature of the video. It is possible that the effect will be better after converting the 2D feature into a bev feature.
- The effect may be better when combined with LLM. For example, the Text Generation part is replaced by LLM.
- The current work is to use historical videos as input, and the predicted actions and their descriptions are also historical. If It may be more meaningful to predict future actions and the causes corresponding to the actions.
- The image tokenized token is a bit too much, and there may be a lot of useless information. Maybe you can try Token-Learner.
What is the starting point?
End-to-end autonomous driving has huge potential in the transportation industry, and research in this area is currently hot. For example, UniAD, the best paper of CVPR2023, does end-to-end automatic driving. However, the lack of transparency and explainability of the automated decision-making process will hinder its development. After all, safety is the first priority for real vehicles on the road. There have been some early attempts to use attention maps or cost volumes to improve model interpretability, but these methods are difficult to understand. So the starting point of this work is to find an easy-to-understand way to explain decision-making. The picture below is a comparison of several methods. Obviously it is easier to understand in words.
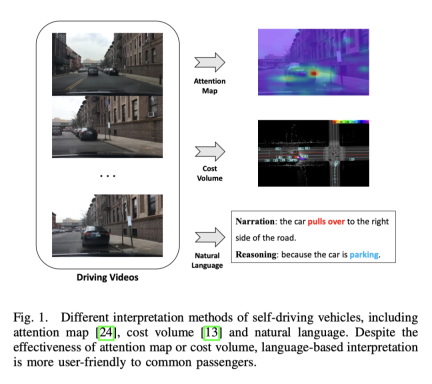
What are the advantages of ADAPT?
- It can output the vehicle action description and the reasoning of each decision end-to-end;
- This method is based on the transformer network structure and is combined through multi-task. Training;
- Achieved SOTA effect on BDD-X (Berkeley DeepDrive eXplanation) data set;
- In order to verify the effectiveness of the system in real scenarios, a set of deployable This system can input the original video and output the description and reasoning of the action in real time;
Effect display

Current progress in the field
Video Captioning
The main goal of video description is to describe a given video in natural language Objects and their relationships. Early research works generated sentences with specific syntactic structures by filling identified elements in fixed templates, which were inflexible and lacked richness. In order to generate natural sentences with flexible syntactic structures, some methods use sequence learning techniques. Specifically, these methods use video encoders to extract features and language decoders to learn visual text alignment. To make descriptions richer, these methods also utilize object-level representations to obtain detailed object-aware interaction features in videosAlthough the existing architecture has achieved certain results in the general video captioning direction, it cannot Directly applied to action representation, because simply transferring video description to self-driving action representation will lose some key information, such as vehicle speed, etc., which are crucial for self-driving tasks. How to effectively utilize this multi-modal information to generate sentences is still being explored. PaLM-E does a good job in multi-modal sentences.End-to-end autonomous driving
Learning-based autonomous driving is an active research field. The recent CVPR2023 best-paper UniAD, including the subsequent FusionAD, and Wayve's World model-based work MILE are all work in this direction. The output format includes trajectory points, like UniAD, and vehicle action directly, like MILE. Additionally, some methods model the future behavior of traffic participants such as vehicles, cyclists, or pedestrians to predict the vehicle’s waypoints, while other methods predict the vehicle’s control directly from sensor inputs. signal, similar to the control signal prediction subtask in this workInterpretability of Autonomous Driving
In the field of autonomous driving, most interpretability methods are based on vision, and some are based on LiDAR work. Some methods utilize attention maps to filter out insignificant image regions, making the behavior of autonomous vehicles look reasonable and explainable. However, the attention map may contain some less important regions. There are also methods that use lidar and high-precision maps as input, predict the bounding boxes of other traffic participants, and utilize ontology to explain the decision-making reasoning process. Additionally, there is a way to build online maps through segmentation to reduce reliance on HD maps. Although vision- or lidar-based methods can provide good results, the lack of verbal explanation makes the entire system appear complex and difficult to understand. A study explores the possibility of text interpretation for autonomous vehicles for the first time, by extracting video features offline to predict control signals and perform the task of video description
Multi-task learning in autonomous driving
This end-to-end framework uses multi-task learning to jointly train the model with the two tasks of text generation and predictive control signals. Multi-task learning is widely used in autonomous driving. Due to better data utilization and shared features, joint training of different tasks improves the performance of each task. Therefore, in this work, joint training of the two tasks of control signal prediction and text generation is used.
ADAPT method
The following is the network structure diagram:
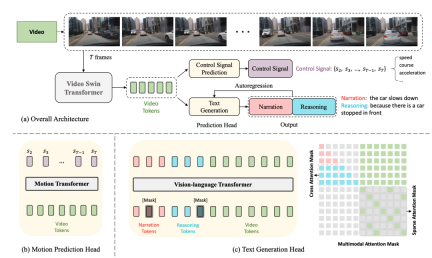
The entire structure is divided into two tasks:
- Driving Caption Generation (DCG): Input videos and output two sentences. The first sentence describes the action of the car, and the second sentence describes the reasoning for taking this action, such as "The car is accelerating, because the traffic lights turn green."
- Control Signal Prediction(CSP): Input the same videos and output a series of control signals, such as speed, direction, acceleration.
Among them, The two tasks of DCG and CSP share the Video Encoder, but use different prediction heads to produce different final outputs.
For the DCG task, the vision-language transformer encoder is used to generate two natural language sentences.
For CSP tasks, use motion transformation encoder to predict the sequence of control signals
Video Encoder
The Video Swin Transformer is used here to input The video frames are converted into video feature tokens.
Input zhenimage, the shape is , the size of the feature is , where is the dimension of the channel .
Prediction Heads
Text Generation Head
The above feature is obtained after tokenization video tokens with dimensions , and then go through an MLP to adjust the dimensions to align with the embedding of text tokens, and then feed the text tokens and video tokens together to the vision-language transformer encoder to generate actions Description and inference.
Control Signal Prediction Head
corresponds to the input frame video. There is a control signal , the output of the CSP head Yes , where each control signal is not necessarily one-dimensional, but can be multi-dimensional, such as including speed, acceleration, direction, etc. at the same time. The approach here is to tokenize the video features and then generate a series of output signals through the motion transformer. The loss function is MSE,
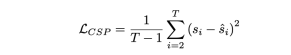
It should be noted that there is no Contains the first frame because the first frame provides too little dynamic information
Joint Training
In this frame, because of the shared video encoder, it is actually It is assumed that the two tasks of CSP and DCG are aligned at the level of video representation. The starting point is that both action descriptions and control signals are different expressions of fine-grained vehicle actions, and action reasoning explanations mainly focus on the driving environment that affects vehicle actions.
Using joint training for training
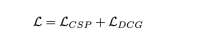
It should be noted that although it is a joint training location, it can be executed independently during inference. CSP The task is easy to understand. Just input the video directly according to the flow chart and output the control signal. For the DCG task, directly input the video and output the description and reasoning. The generation of Text is based on the autoregressive method, word by word, from [CLS ], ends with [SEP] or reaches the length threshold.
Experimental design and comparison
Data set
The data set used is BDD-X. This data set contains 7000 segments. Right video and control signals. Each video lasts about 40 seconds, the image size is , and the frequency is FPS. Each video has 1 to 5 vehicle behaviors, such as accelerating, turning right, and merging. All of these actions are annotated with text, including action narratives (e.g., “The car stopped”) and reasoning (e.g., “Because the traffic light is red”). There are approximately 29,000 behavioral annotation pairs in total.
Specific implementation details
- video swin transformer is pre-trained on Kinetics-600
- vision-language transformer and motion transformer are random The initialized
- does not have fixed video swin parameters, so the whole is end-to-end training.
- The input video frame size is resized and cropped, and the final input to the network is 224x224
- For description and inference, use WordPiece embeddings [75] instead of whole words, (e.g., ”stops” is cut to ”stop” and ”#s”), the maximum length of each sentence is 15
- During training, masked language modeling will randomly mask out 50% of the tokens. Each mask token has an 80% probability of becoming the [MASK] token, a 10% probability of randomly selecting a word, and the remaining The 10% probability remains unchanged.
- The AdamW optimizer is used, and in the first 10% of the training steps, there is a warm-up mechanism
- It takes about 13 hours to train with 4 V100 GPUs
The impact of joint training
Here are three experiments compared to illustrate the effectiveness of joint training.
Single
It refers to removing the CSP task and retaining only the DCG task, which is equivalent to only training the captioning model.
Single
Although the CSP task still does not exist, when entering the DCG module , in addition to the video mark, you also need to input the control signal mark
The effect comparison is as follows
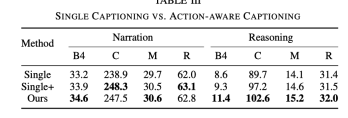
Compared with only the DCG task, the Reasoning effect of ADAPT is significantly better . Although the effect is improved when there is a control signal input, it is still not as good as the effect of adding CSP tasks. After adding the CSP task, the ability to express and understand the video is stronger
In addition, the table below also shows that the effect of joint training on CSP is also improved.

Here can be understood as accuracy. Specifically, the predicted control signal will be truncated. The formula is as follows
Different types of control signals Influence
In the experiment, the basic signals used are speed and heading. However, experiments have found that when only one of the signals is used, the effect is not as good as using both signals at the same time. The specific data is shown in the following table:
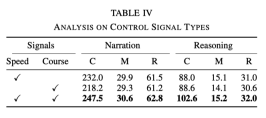
This shows that The two signals of speed and direction can help the network better learn action description and reasoning
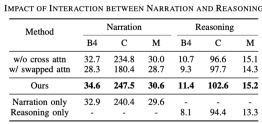
Interaction between action description and reasoning
Compared with general description tasks ,The driving description task generation is two sentences,,namely action description and inference. It can be found from the following table:
- Lines 1 and 3 indicate that the effect of using cross attention is better, which is easy to understand. Inference based on description is conducive to model training;
- Lines 2 and 3 show that the order of exchanging reasoning and description will also be lost, which shows that reasoning depends on description;
- Comparing the next three lines, only outputting description and only outputting reasoning are both The effect is not as good as when both are output;
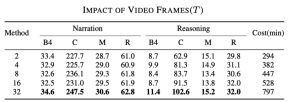
The impact of Sampling Rates
This result can be guessed , the more frames used, the better the result, but the corresponding speed will also be slower, as shown in the following table

Required The rewritten content is: Original link: https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
The above is the detailed content of New title: ADAPT: A preliminary exploration of end-to-end autonomous driving explainability. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Analysis of global positioning technology based on feature points in autonomous driving
- Autonomous driving is difficult to attack by dimensionality reduction
- Discuss the current status and development trends of autonomous driving trajectory prediction technology
- How to develop autonomous driving and Internet of Vehicles in PHP?
- Detailed explanation of obstacle avoidance, path planning and control technology for autonomous vehicles