
 Backend DevelopmentPython TutorialCommon problems and solutions for crawler programming in Python
Backend DevelopmentPython TutorialCommon problems and solutions for crawler programming in Python

Common problems and solutions for crawler programming in Python
Introduction:
With the development of the Internet, the importance of network data has become increasingly prominent. Crawler programming has become an essential skill in fields such as big data analysis and network security. However, crawler programming not only requires a good programming foundation, but also requires facing various common problems. This article will introduce common problems of crawler programming in Python, and provide corresponding solutions and specific code examples. I hope this article can help readers better master crawler programming skills.
1. Access restrictions on target websites
During the crawler programming process, the target website may have set up a series of anti-crawler mechanisms, such as limiting request frequency, banning illegal robots, etc. To overcome these limitations, the following measures can be taken:
1. Set request header information: To simulate normal browser behavior, you can set request header information such as User-Agent and Referer to make the request look more like it is initiated by the user. .
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': 'http://www.example.com'
}
response = requests.get(url, headers=headers)2. Use proxy IP: By using a proxy server, you can hide your real IP address to avoid being banned by the target website. You can find some available proxy IPs on the Internet and set the proxy using the proxies parameter of the requests library.
import requests
proxies = {
'http': 'http://111.11.111.111:8080',
'https': 'http://111.11.111.111:8080'
}
response = requests.get(url, proxies=proxies)3. Use Cookies: Some websites use Cookies to identify whether they are robots. Cookie information can be passed using the cookies parameter of the requests library.
import requests
cookies = {
'name': 'value'
}
response = requests.get(url, cookies=cookies)2. Dynamic loading and asynchronous loading data acquisition
Many websites now use dynamic loading or asynchronous loading to obtain data. For such websites, we need to simulate the behavior of the browser. retrieve data. The following methods can be used:
1. Use Selenium WebDriver: Selenium is an automated testing tool that can simulate browser behavior, including clicks, inputs and other operations. Selenium WebDriver can achieve dynamic loading and asynchronous loading of data acquisition.
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get(url) # 使用WebDriverWait等待数据加载完毕 from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC locator = (By.XPATH, '//div[@class="data"]') data = WebDriverWait(driver, 10).until(EC.presence_of_element_located(locator)).text
2. Analyze Ajax requests: Open the Chrome browser developer tools, select the Network panel, refresh the page, observe the data format and parameters of the request, and then use the requests library to simulate sending Ajax requests.
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': 'http://www.example.com',
'X-Requested-With': 'XMLHttpRequest'
}
response = requests.get(url, headers=headers)3. Data analysis and extraction
In crawler programming, data analysis and extraction is a very critical step. Common data formats include HTML, JSON, XML, etc. The following will introduce the parsing methods of these common data formats:
1.HTML parsing: You can use the BeautifulSoup library in Python to parse HTML documents and use selectors or XPath Expressions extract the required data.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# 使用选择器提取数据
data = soup.select('.class')2.JSON parsing: Use Python’s built-in json library to parse data in JSON format.
import json data = json.loads(response.text)
3. XML parsing: The xml library, ElementTree library, etc. in Python can be used to parse data in XML format.
import xml.etree.ElementTree as ET
tree = ET.fromstring(xml)
root = tree.getroot()
# 提取数据
data = root.find('tag').textSummary:
Crawler programming is a complex and challenging task, but with adequate preparation and learning, we can overcome the difficulties and problems. This article introduces common problems of crawler programming in Python and gives corresponding solutions and code examples. I hope this content can help readers better master the skills and methods of crawler programming. In practice, different methods can also be flexibly applied to solve problems according to the actual situation.
The above is the detailed content of Common problems and solutions for crawler programming in Python. For more information, please follow other related articles on the PHP Chinese website!

 修复:Sysprep 无法验证 Windows 11 安装May 19, 2023 am 10:15 AM
修复:Sysprep 无法验证 Windows 11 安装May 19, 2023 am 10:15 AMSysprep问题可能出现在Windows11、10和8平台上。出现该问题时,Sysprep命令不会按预期运行和验证安装。如果您需要修复Sysprep问题,请查看下面的Windows11/10解决方案。Sysprep错误是如何在Windows中出现的?Sysprep无法验证您的Windows安装错误自Windows8以来一直存在。该问题通常是由于用户安装的UWP应用程序而出现的。许多用户已确认他们通过卸载从MSStore安装的某些UWP应用程序解决了此问题。如果缺少应该与Windows一起预安装
 重置管理员权限: 如何重新获得管理员权限?Apr 23, 2023 pm 10:10 PM
重置管理员权限: 如何重新获得管理员权限?Apr 23, 2023 pm 10:10 PM您将找到多个用户报告,确认NETHELPMSG2221错误代码。当您的帐户不再是管理员时,就会显示此信息。根据用户的说法,他们的帐户自动被撤销了管理员权限。如果您也遇到此问题,我们建议您应用指南中的解决方案并修复NETHELPMSG2221错误。您可以通过多种方式将管理员权限恢复到您的帐户。让我们直接进入它们。什么是NETHELPMSG2221错误?当您不是PC的管理员时,无法使用提升的程序。因此,例如,你将无法在电脑上运行命令提示符、WindowsPowerShell或任
 如何解决Windows更新错误代码0x8024800c?Apr 21, 2023 am 09:55 AM
如何解决Windows更新错误代码0x8024800c?Apr 21, 2023 am 09:55 AM什么原因导致WindowsUpdate错误0x8024800c?导致WindowsUpdate错误的原因0x8024800c尚不完全清楚。但是,此问题可能与其他更新错误具有类似的原因。以下是一些潜在的0x8024800c错误原因:损坏的系统文件–某些系统文件需要修复。不同步的软件分发缓存–软件分发数据存储不同步,这意味着此错误是超时问题(它有一个WU_E_DS_LOCKTIMEOUTEXPIRED结果字符串)。损坏的WindowsUpdate组件-错误0x8024800c是由错误的Win
 如何解决您的 Office 许可证有问题May 20, 2023 pm 02:08 PM
如何解决您的 Office 许可证有问题May 20, 2023 pm 02:08 PMMSOffice产品是任何Windows系统上用于创建Word、Excel表格等文档的应用程序的绝佳选择。但是您需要从Microsoft购买Office产品的有效许可证,并且必须激活它才能使其有效工作.最近,许多Windows用户报告说,每当他们启动任何Office产品(如Word、Excel等)时,他们都会收到一条警告消息,上面写着“您的Office许可证存在问题,并要求用户获取正版Office许可证”。一些用户不假思索,就去微软购买了Office产品的许可证
 WWAHost.exe 进程高磁盘、CPU 或内存使用修复Apr 14, 2023 pm 04:43 PM
WWAHost.exe 进程高磁盘、CPU 或内存使用修复Apr 14, 2023 pm 04:43 PM许多用户在系统变慢时报告任务管理器中存在WWAHost.exe进程。WWAHost.exe进程会占用大量系统资源,例如内存、CPU或磁盘,进而降低PC的速度。因此,每当您发现您的系统与以前相比变得缓慢时,请打开任务管理器,您会在那里找到这个WWAHost.exe进程。通常,已观察到启动任何应用程序(如Mail应用程序)会启动WWAHost.exe进程,或者它可能会自行开始执行,而无需在您的WindowsPC上进行任何外部输入。此进程是安全有效的Microsoft程序,是Wi
![如何修复iPhone上的闹钟不响[已解决]](https://img.php.cn/upload/article/000/465/014/168385668827544.png) 如何修复iPhone上的闹钟不响[已解决]May 12, 2023 am 09:58 AM
如何修复iPhone上的闹钟不响[已解决]May 12, 2023 am 09:58 AM闹钟是当今大多数智能手机附带的良好功能之一。它不仅有助于让用户从睡眠中醒来,还可以用作在设定时间响铃的提醒。如今,许多iPhone用户抱怨iPhone上的闹钟无法正常响起,这给他们带来了问题。闹钟不响的潜在原因有很多,可能是因为iPhone处于静音模式,对闹钟设置进行了更改,选择低音调作为闹钟铃声,蓝牙设备已连接到iPhone等。在研究了此问题的各种原因后,我们在下面的帖子中编制了一组解决方案。初步解决方案确保iPhone未处于静音模式–当iPhone处于静音模式时,它只会使来自应用程序,通话和
 如何在iPhone上修复iTunes错误1667Apr 17, 2023 pm 09:58 PM
如何在iPhone上修复iTunes错误1667Apr 17, 2023 pm 09:58 PM大多数人作为备份实践将他们的文件从iPhone传输到PC/Mac,以防由于某些明显的原因而丢失。为此,他们必须通过避雷线将iPhone连接到PC/Mac。许多iPhone用户在尝试将iPhone连接到计算机以在它们之间同步文件时遇到错误1667。此错误背后有相当潜在的原因,可能是计算机或iPhone中的内部故障,闪电电缆损坏或损坏,用于同步文件的过时的iTunes应用程序,防病毒软件产生问题,不更新计算机的操作系统等。在这篇文章中,我们将向您解释如何使用以下给定的解决方案轻松有效地解决此错误。初
 Excel中如何根据数据大小自动调整行和列May 20, 2023 pm 07:56 PM
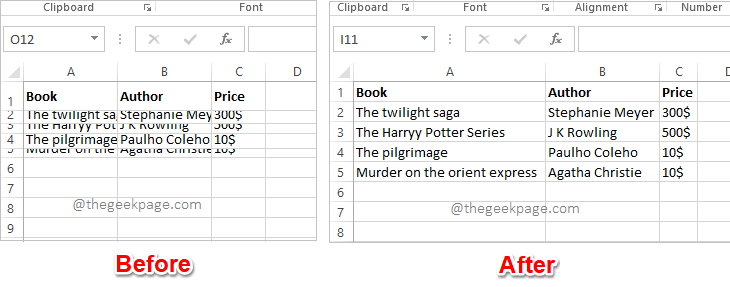
Excel中如何根据数据大小自动调整行和列May 20, 2023 pm 07:56 PM你有一个紧迫的截止日期,你即将提交你的工作,那时你注意到你的Excel工作表不整洁。行和列的高度和宽度不同,大部分数据是重叠的,无法完美查看数据。根据内容手动调整行和列的高度和宽度确实会花费大量时间,当然不建议这样做。顺便说一句,当你可以通过一些简单的点击或按键来自动化整个事情时,你为什么还要考虑手动做呢?在本文中,我们详细解释了如何通过以下3种不同的解决方案轻松地在Excel工作表中自动调整行高或列宽。从现在开始,您可以选择自己喜欢的解决方案并成为Excel任务的高手!解决方案1:通过


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

