



The inference efficiency of machine learning models requires specific code examples
Introduction
With the development and widespread application of machine learning, people are concerned about Model training is attracting more and more attention. However, for many real-time applications, the inference efficiency of the model is also crucial. This article will discuss the inference efficiency of machine learning models and give some specific code examples.
1. The Importance of Inference Efficiency
The inference efficiency of a model refers to the ability of the model to quickly and accurately provide output given the input. In many real-life applications, such as real-time image processing, speech recognition, autonomous driving, etc., the requirements for inference efficiency are very high. This is because these applications need to process large amounts of data in real time and respond promptly.
2. Factors affecting reasoning efficiency
- Model architecture
Model architecture is one of the important factors affecting reasoning efficiency. Some complex models, such as Deep Neural Network (DNN), may take a long time during the inference process. Therefore, when designing models, we should try to choose lightweight models or optimize them for specific tasks.
- Hardware equipment
Hardware equipment also affects inference efficiency. Some emerging hardware accelerators, such as Graphic Processing Unit (GPU) and Tensor Processing Unit (TPU), have significant advantages in accelerating the inference process of models. Choosing the right hardware device can greatly improve inference speed.
- Optimization technology
Optimization technology is an effective means to improve reasoning efficiency. For example, model compression technology can reduce the size of the model, thereby shortening the inference time. At the same time, quantization technology can convert floating-point models into fixed-point models, further improving inference speed.
3. Code Examples
The following are two code examples that demonstrate how to use optimization techniques to improve inference efficiency.
Code Example 1: Model Compression
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.models import save_model
# 加载原始模型
model = MobileNetV2(weights='imagenet')
# 保存原始模型
save_model(model, 'original_model.h5')
# 模型压缩
compressed_model = tf.keras.models.load_model('original_model.h5')
compressed_model.save('compressed_model.h5', include_optimizer=False)In the above code, we use the tensorflow library to load a pre-trained MobileNetV2 model and save it as the original model. Then, use the model for compression, saving the model as compressed_model.h5 file. Through model compression, the size of the model can be reduced, thereby increasing the inference speed.
Code Example 2: Using GPU Acceleration
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
# 设置GPU加速
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
# 加载模型
model = MobileNetV2(weights='imagenet')
# 进行推理
output = model.predict(input)In the above code, we use the tensorflow library to load a pre-trained MobileNetV2 model and set the model's inference process to GPU acceleration. By using GPU acceleration, inference speed can be significantly increased.
Conclusion
This article discusses the inference efficiency of machine learning models and gives some specific code examples. The inference efficiency of machine learning models is very important for many real-time applications. Inference efficiency should be considered when designing models and corresponding optimization measures should be taken. We hope that through the introduction of this article, readers can better understand and apply inference efficiency optimization technology.
The above is the detailed content of Inference efficiency issues of machine learning models. For more information, please follow other related articles on the PHP Chinese website!

 如何利用C++开发高度可定制的编程框架?Aug 25, 2023 pm 01:21 PM
如何利用C++开发高度可定制的编程框架?Aug 25, 2023 pm 01:21 PM如何利用C++开发高度可定制的编程框架?引言:在软件开发领域,我们经常需要构建自己的编程框架来满足特定的需求。C++是一种强大的编程语言,可以用于开发高度可定制的编程框架。本文将介绍如何使用C++来开发一个高度可定制的编程框架,并提供相应的代码示例。一、确定框架的目标和需求在开发框架之前,我们需要明确框架的目标和需求。这些目标和需求将指导我们在设计和实现框架
 如何调整Windows 7桌面显示比例Dec 27, 2023 am 08:13 AM
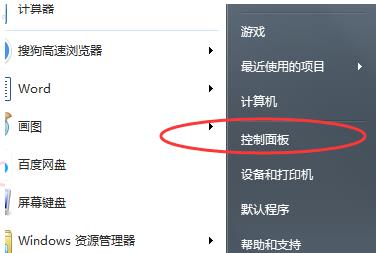
如何调整Windows 7桌面显示比例Dec 27, 2023 am 08:13 AM使用win7的小伙伴非常的多,在电脑上看视频或是资料的时候都会需要进行比例的调整吧,那么该怎么去调整呢?下面就来看看详细的设置方法吧。win7桌面显示比例怎么设置:1、点击左下角电脑打开“控制面板”。2、随后在控制面板中找到“外观”。3、进入外观后点击“显示”。4、随后即可根据需要显示的效果进行桌面的大小显示调节。5、也可以点击左侧的“调整分辨率”。6、通过更改屏幕分辨率来调整电脑桌面的比例。
 解决win11右键无响应问题的步骤Dec 25, 2023 pm 06:56 PM
解决win11右键无响应问题的步骤Dec 25, 2023 pm 06:56 PM一般来说,我们可以通过右键空白处打开右键菜单,或者右键文件打开属性菜单等,但是如果我们在使用win11系统时,出现右键没反应的情况,可以在注册表编辑器中找到对应的项更改设置就解决了,下面一起来操作一下吧。win11右键没反应怎么办1、首先使用键盘“win+r”快捷键打开运行,在其中输入“regedit”回车确定打开注册表。2、在注册表中找到“HKEY_CLASSES_ROOT\lnkfile”路径下的“lnkfile”文件夹。3、然后在右侧右键选择新建一个“字符串值”4、新建完成后双击打开,将它
 在Java中,枚举类型可以实现接口吗?Sep 08, 2023 pm 02:17 PM
在Java中,枚举类型可以实现接口吗?Sep 08, 2023 pm 02:17 PM是的,Enum在Java中实现了一个接口,当我们需要实现一些与给定对象或类的可区分属性紧密耦合的业务逻辑时,它会很有用。枚举是Java1.5版本中添加的一种特殊数据类型。枚举是常量,默认情况下它们是静态的strong>和final,因此枚举类型字段的名称采用大写字母。示例interfaceEnumInterface{ intcalculate(intfirst,intsecond);}enumEnumClassOperatorimplementsEnu
 用户程序的多步处理Aug 31, 2023 pm 04:45 PM
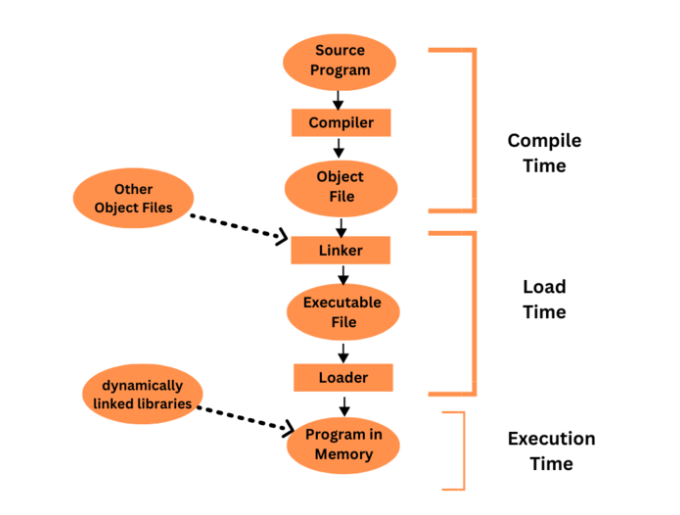
用户程序的多步处理Aug 31, 2023 pm 04:45 PM计算机系统必须将用户的高级编程语言程序转换为机器代码,以便计算机的处理器可以运行它。多步处理是一个术语,用于描述将用户程序转换为可执行代码所涉及的多个过程。用户程序在其多步骤处理过程中通常会经历许多不同的阶段,包括词法分析、句法分析、语义分析、代码创建、优化和链接。为了将用户程序从高级形式转换为可以在计算机系统上运行的机器代码,每个阶段都是必不可少的。用户程序与操作系统或其他系统软件的组件不同,用户程序是由用户编写和运行的计算机程序。大多数时候,用户程序是用高级编程语言创建的,旨在执行特定的活动
 重复的字符,其第一次出现在最左边Aug 31, 2023 pm 06:05 PM
重复的字符,其第一次出现在最左边Aug 31, 2023 pm 06:05 PM简介在本教程中,我们将开发一种方法来查找字符串中首次出现在最左边的重复字符。这意味着该字符首先出现在字符串的开头。为了确定第一个字符是否重复,我们遍历整个字符串并将每个字符与字符串的第一个字符进行匹配。为了解决这个任务,我们使用C++编程语言的find()、length()和end()函数。示例1String=“Tutorialspoint”Output=Therepeatingcharacteris“t”在上面的示例中,输入字符串“tutorialspoint”最左边的字符是“t”,并且该字符
 Win11引导选项在哪Jun 29, 2023 pm 01:13 PM
Win11引导选项在哪Jun 29, 2023 pm 01:13 PMWin11引导选项在哪?Win11引导选项怎么设置?引导选项是开机的时候系统会在前台或者后台运行的程序,用户可以在引导选项中选择电脑系统从哪个磁盘设备启动。下面小编将为大家带来Win11引导选项的设置方法,我们一起来看看吧。 Win11引导选项设置步骤 1、使用Windows11设置菜单 按键并从菜单中Windows打开Windows设置。 选择系统设置,然后单击恢复设置。 在Advancedstartup选项中单击Restartnow。 您的系统现在将重新启动进入引导设置。
 提升PHP技术能力,实现高薪突破Sep 08, 2023 pm 01:06 PM
提升PHP技术能力,实现高薪突破Sep 08, 2023 pm 01:06 PM提升PHP技术能力,实现高薪突破在当前的互联网时代,PHP作为一种常用的开发语言,已经成为了许多企业和个人开发者的首选之一。然而,随着市场竞争的加剧,要想在PHP领域获得高薪突破,就需要不断提升自己的技术能力。本文将分享一些提升PHP技术能力的方法,并通过代码示例进行说明。深入学习PHP基础知识作为一名PHP开发者,首先要掌握的是PHP的基础知识。这包括掌握


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SublimeText3 Chinese version
Chinese version, very easy to use

