

 Technology peripheralsAIBreak the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrier
Technology peripheralsAIBreak the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrierBreak the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrier

For many years, we have been unable to understand how artificial intelligence makes decisions and produces output
Model developers can only decide on algorithms, data, and finally get the model Output results, and the middle part - how the model outputs results based on these algorithms and data, becomes an invisible "black box".

So there is a joke like "model training is like alchemy".
But now, the model black box is finally interpretable!
The research team from Anthropic extracted the interpretable features of the most basic unit neurons in the model’s neural network.

This will be a landmark step for mankind to uncover the black box of AI.
Anthropic expressed excitedly:
"If we can understand how the neural network in the model works, then we can diagnose the faults of the model. Patterns, design fixes, and safe adoption by businesses and society will become a within-reaching reality!"
at Anthropic In the latest research report "Towards Monosemanticity: Using Dictionary Learning to Decompose Language Models", researchers used dictionary learning methods to successfully decompose a layer containing 512 neurons into more than 4,000 interpretable features

Research report address: https://transformer-circuits.pub/2023/monosemantic-features/index.html
These features represent DNA sequences, legal language, HTTP requests, Hebrew text, and nutrition instructions, etc.
When we look at the activation of a single neuron in isolation, we It is impossible to see most of these model properties
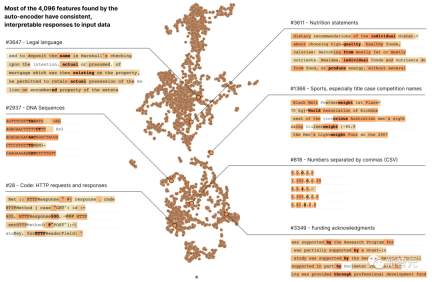
Most neurons are "polysemantic", meaning that a single neuron is There is no consistent correspondence between network behaviors
For example, in a small language model, a single neuron is active in many unrelated contexts, including: academic citations, English Conversations, HTTP requests, and Korean text.
In the classic vision model, a single neuron responds to the face of a cat and the front of a car.
In different contexts, many studies have demonstrated that the activation of a neuron can have different meanings

One potential reason is that the polysemantic nature of neurons is due to the additive effect. This is a hypothetical phenomenon whereby neural networks represent independent features of data by assigning each feature its own linear combination of neurons, and the number of such features exceeds the number of neurons
If each feature is regarded as a vector on a neuron, then the feature set forms an overcomplete linear basis for the activation of network neurons.
In Anthropic’s previous Toy Models of Superposition paper, it was proved that sparsity can eliminate ambiguity in neural network training and help the model better understand features. relationship between them, thereby reducing the uncertainty of the source features of the activation vector and making the model’s predictions and decisions more reliable.
This concept is similar to the idea in compressed sensing, where the sparsity of the signal allows the complete signal to be restored from limited observations.

But among the three strategies proposed in Toy Models of Superposition:
# (1) Create a model without superposition, Perhaps activation sparsity can be encouraged;
(2) In models that exhibit superposition states, dictionary learning is used to find overcomplete features
(3) relies on a hybrid approach that combines the two.
What needs to be rewritten is: method (1) cannot solve the problem of ambiguity, while method (2) is prone to serious overfitting
So this time Anthropic researchers used a weak dictionary learning algorithm called a sparse autoencoder to generate learned features from the trained model that provide better performance than model neurons itself a more unitary unit of semantic analysis.
Specifically, the researchers adopted an MLP single-layer transformer with 512 neurons, and finally trained a sparse autoencoder on MLP activations from 8 billion data points. Decomposing MLP activations into relatively interpretable features, expansion factors range from 1× (512 features) to 256× (131,072 features).
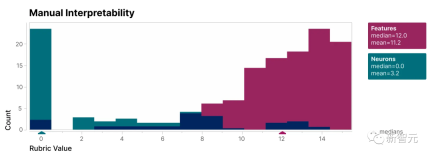
To verify that the features found in this study are more interpretable than the model's neurons, we conducted a blind review and asked a human evaluator to evaluate their interpretability. Rating
As you can see, the feature (red) has a much higher score than the neuron (cyan).
It has been shown that the features discovered by the researchers are easier to understand relative to the neurons inside the model
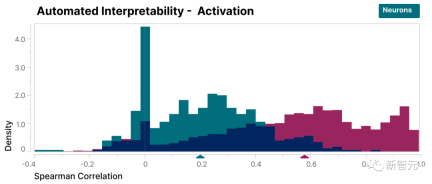
Additionally, the researchers adopted an "automated interpretability" approach by using a large language model to generate a short description of a small model's features and having another model score that description based on its ability to predict feature activation. .
Likewise, features score higher than neurons, demonstrating a consistent interpretation of the activation of features and their downstream effects on model behavior.
Moreover, these extracted features also provide a targeted method to guide the model.
As shown in the figure below, artificially activating features can cause model behavior to change in predictable ways.
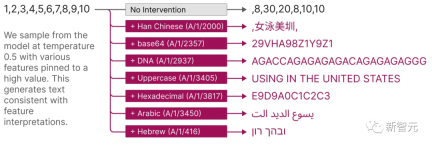
The following is a visualization of the extracted interpretability features:
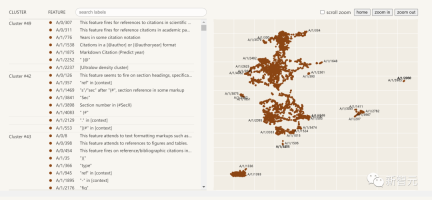
Click on the feature list on the left to interactively explore the feature space in the neural network
Research Report Summary
This research report from Anthropic, Towards Monosemanticity: Decomposing Language Models With Dictionary Learning, can be divided into four parts.
Problem setting, the researchers introduced the research motivation and elaborated on the trained transfomer and sparse autoencoder.
Detailed investigation of individual features proves that several features found in the study are functionally specific causal units.
Through global analysis, we conclude that the typical features are interpretable and they are able to explain important components of the MLP layer
Phenomenon analysis describes several properties of features, including feature segmentation, universality, and how they form systems similar to "finite state automata" to achieve complex behaviors.
The conclusions include the following 7:
Sparse autoencoder has the ability to extract relatively single semantic features
Sparse autoencoders are able to generate interpretable features that are actually invisible in the basis of neurons
3. Sparse Autoencoders Features can be used to intervene and guide the generation of transformers.
4. Sparse autoencoders can generate relatively general features.
As the size of the autoencoder increases, features tend to "split". After rewriting: As the size of the autoencoder increases, features show a trend of "splitting"
#6. Only 512 neurons can represent thousands of features
7. These features are connected together, similar to a "finite state automaton" system, to achieve complex behaviors, as shown in the figure below
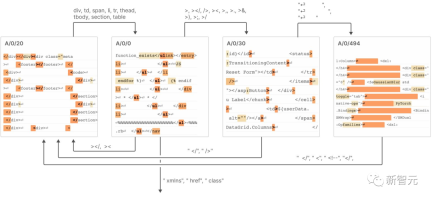
Specific details can be found in the report.
Anthropic believes that to replicate the success of the small model in this research report to a larger model, the challenge we face in the future will no longer be a scientific problem, but an engineering problem
Achieving interpretability on large models requires more effort and resources in engineering to overcome the challenges posed by model complexity and size
Includes developing new tools, techniques and methods to cope with the challenges of model complexity and data scale; it also includes building scalable interpretive frameworks and tools to adapt to the needs of large-scale models.
This will become the latest trend in interpretive artificial intelligence and large-scale deep learning research
The above is the detailed content of Break the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrier. For more information, please follow other related articles on the PHP Chinese website!

![Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AM
Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AMChatGPT is not accessible? This article provides a variety of practical solutions! Many users may encounter problems such as inaccessibility or slow response when using ChatGPT on a daily basis. This article will guide you to solve these problems step by step based on different situations. Causes of ChatGPT's inaccessibility and preliminary troubleshooting First, we need to determine whether the problem lies in the OpenAI server side, or the user's own network or device problems. Please follow the steps below to troubleshoot: Step 1: Check the official status of OpenAI Visit the OpenAI Status page (status.openai.com) to see if the ChatGPT service is running normally. If a red or yellow alarm is displayed, it means Open
 Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AM
Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AMOn 10 May 2025, MIT physicist Max Tegmark told The Guardian that AI labs should emulate Oppenheimer’s Trinity-test calculus before releasing Artificial Super-Intelligence. “My assessment is that the 'Compton constant', the probability that a race to
 An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AM
An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AMAI music creation technology is changing with each passing day. This article will use AI models such as ChatGPT as an example to explain in detail how to use AI to assist music creation, and explain it with actual cases. We will introduce how to create music through SunoAI, AI jukebox on Hugging Face, and Python's Music21 library. Through these technologies, everyone can easily create original music. However, it should be noted that the copyright issue of AI-generated content cannot be ignored, and you must be cautious when using it. Let’s explore the infinite possibilities of AI in the music field together! OpenAI's latest AI agent "OpenAI Deep Research" introduces: [ChatGPT]Ope
 What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AM
What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AMThe emergence of ChatGPT-4 has greatly expanded the possibility of AI applications. Compared with GPT-3.5, ChatGPT-4 has significantly improved. It has powerful context comprehension capabilities and can also recognize and generate images. It is a universal AI assistant. It has shown great potential in many fields such as improving business efficiency and assisting creation. However, at the same time, we must also pay attention to the precautions in its use. This article will explain the characteristics of ChatGPT-4 in detail and introduce effective usage methods for different scenarios. The article contains skills to make full use of the latest AI technologies, please refer to it. OpenAI's latest AI agent, please click the link below for details of "OpenAI Deep Research"
 Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AM
Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AMChatGPT App: Unleash your creativity with the AI assistant! Beginner's Guide The ChatGPT app is an innovative AI assistant that handles a wide range of tasks, including writing, translation, and question answering. It is a tool with endless possibilities that is useful for creative activities and information gathering. In this article, we will explain in an easy-to-understand way for beginners, from how to install the ChatGPT smartphone app, to the features unique to apps such as voice input functions and plugins, as well as the points to keep in mind when using the app. We'll also be taking a closer look at plugin restrictions and device-to-device configuration synchronization
 How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AM
How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AMChatGPT Chinese version: Unlock new experience of Chinese AI dialogue ChatGPT is popular all over the world, did you know it also offers a Chinese version? This powerful AI tool not only supports daily conversations, but also handles professional content and is compatible with Simplified and Traditional Chinese. Whether it is a user in China or a friend who is learning Chinese, you can benefit from it. This article will introduce in detail how to use ChatGPT Chinese version, including account settings, Chinese prompt word input, filter use, and selection of different packages, and analyze potential risks and response strategies. In addition, we will also compare ChatGPT Chinese version with other Chinese AI tools to help you better understand its advantages and application scenarios. OpenAI's latest AI intelligence
 5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AM
5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AMThese can be thought of as the next leap forward in the field of generative AI, which gave us ChatGPT and other large-language-model chatbots. Rather than simply answering questions or generating information, they can take action on our behalf, inter
 An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AM
An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AMEfficient multiple account management techniques using ChatGPT | A thorough explanation of how to use business and private life! ChatGPT is used in a variety of situations, but some people may be worried about managing multiple accounts. This article will explain in detail how to create multiple accounts for ChatGPT, what to do when using it, and how to operate it safely and efficiently. We also cover important points such as the difference in business and private use, and complying with OpenAI's terms of use, and provide a guide to help you safely utilize multiple accounts. OpenAI


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Notepad++7.3.1
Easy-to-use and free code editor

