


Refreshed the industry’s best zero-shot performance in multiple benchmark tests.
A unified model that can understand different modal input contents (text, image, video, audio, IMU motion sensor data) and generate text responses. The technology is based on Llama 2 , from Meta.
Yesterday, the research on the multi-modal large model AnyMAL attracted the attention of the AI research community.
Large Language Models (LLMs) are known for their enormous size and complexity, which greatly enhance the ability of machines to understand and express human language. Advances in LLMs have enabled significant advances in the field of visual language, bridging the gap between image encoders and LLMs, combining their inference capabilities. Previous multimodal LLM research has focused on models that combine text with another modality, such as text and image models, or on proprietary language models that are not open source.
If there is a better way to achieve multi-modal functionality and embed various modalities in LLM, will this bring us a different experience?

##Q output Example
This problem, researchers from META recently launched Anymal ( Any-Modality Augmented Language Model). This is a collection of multi-modal encoders trained to transform data from a variety of modalities, including images, video, audio, and IMU motion sensor data, into LLM’s text embedding space

Paper address: https://huggingface.co/papers/2309.16058
According to the description, the main contributions of this research are as follows:
Proposed an efficient and scalable solution for building multi-modal LLM. This article provides projection layers pre-trained on large datasets containing multiple modalities (e.g., 200 million images, 2.2 million audio segments, 500,000 IMU time series, 28 million video segments), all All aligned to the same large model (LLaMA-2-70B-chat), enabling interleaved multi-modal contextual cues.
This study further fine-tuned the model using a multi-modal instruction set across three modalities (image, video and audio), covering various fields beyond simple question answering (QA). unlimited tasks. This dataset contains high-quality manually collected instruction data, so this study uses it as a benchmark for complex multi-modal reasoning tasks
The best model in this paper automatically performs various tasks and modes Compared with the models in the existing literature, the relative accuracy on VQAv2 has been improved by 7.0%, and the CIDEr on zero-error COCO image subtitles has been improved by 8.4%. Improved CIDEr by 14.5% on AudioCaps and created new SOTA
The content of pre-training modal alignment needs to be rewritten
By using paired multi-modal data (including specific modal signals and text narrative), this study pre-trained LLM to achieve multi-modal understanding capabilities, as shown in Figure 2. Specifically, we train a lightweight adapter for each modality that projects the input signal into the text token embedding space of a specific LLM. In this way, the text tag embedding space of LLM becomes a joint tag embedding space, where tags can represent text or other modalities.  Regarding the study of image alignment, we used one of the LAION-2B dataset A clean subset was filtered using the CAT method to blur any detectable faces. For the study of audio alignment, the AudioSet (2.1M), AudioCaps (46K) and CLOTHO (5K) data sets were used. In addition, we also used the Ego4D dataset for IMU and text alignment (528K)For large datasets, scaling up pre-training to a 70B parameter model requires a lot of resources, often requiring the use of FSDP wrappers on multiple Slice the model on multiple GPUs. To effectively scale training, we implement a quantization strategy (4-bit and 8-bit) in a multi-modal setting, where the LLM part of the model is frozen and only the modal tokenizer is trainable. This approach reduces memory requirements by an order of magnitude. Therefore, 70B AnyMAL can complete training on a single 80GB VRAM GPU with a batch size of 4. Compared with FSDP, the quantization method proposed in this article only uses half of the GPU resources, but achieves the same throughput
Regarding the study of image alignment, we used one of the LAION-2B dataset A clean subset was filtered using the CAT method to blur any detectable faces. For the study of audio alignment, the AudioSet (2.1M), AudioCaps (46K) and CLOTHO (5K) data sets were used. In addition, we also used the Ego4D dataset for IMU and text alignment (528K)For large datasets, scaling up pre-training to a 70B parameter model requires a lot of resources, often requiring the use of FSDP wrappers on multiple Slice the model on multiple GPUs. To effectively scale training, we implement a quantization strategy (4-bit and 8-bit) in a multi-modal setting, where the LLM part of the model is frozen and only the modal tokenizer is trainable. This approach reduces memory requirements by an order of magnitude. Therefore, 70B AnyMAL can complete training on a single 80GB VRAM GPU with a batch size of 4. Compared with FSDP, the quantization method proposed in this article only uses half of the GPU resources, but achieves the same throughput
Using multi-modal instruction data sets for fine-tuning means using multi-modal instruction data sets for fine-tuning
In order to further To improve the model's ability to follow instructions for different input modalities, the study used the Multi-Modal Instruction Tuning (MM-IT) data set for additional fine-tuning. Specifically, we concatenate the input as [ ] so that the response target is based on both the textual instruction and the modal input. Research is conducted on the following two situations: (1) training the projection layer without changing the LLM parameters; or (2) using low-level adaptation (Low-Rank Adaptation) to further adjust the LM behavior. The study uses both manually collected instruction-tuned datasets and synthetic data.
] so that the response target is based on both the textual instruction and the modal input. Research is conducted on the following two situations: (1) training the projection layer without changing the LLM parameters; or (2) using low-level adaptation (Low-Rank Adaptation) to further adjust the LM behavior. The study uses both manually collected instruction-tuned datasets and synthetic data.
Experiments and results
Image title generation is an artificial intelligence technology used to automatically generate corresponding titles for images. This technology combines computer vision and natural language processing methods to generate descriptive captions related to the image by analyzing the content and characteristics of the image, as well as understanding the semantics and syntax. Image caption generation has wide applications in many fields, including image search, image annotation, image retrieval, etc. By automatically generating titles, the understandability of images and the accuracy of search engines can be improved, providing users with a better image retrieval and browsing experience. Description" Zero-shot image caption generation performance on a subset of the MM-IT dataset for the task (MM-IT-Cap). As can be seen, the AnyMAL variant performs significantly better than the baseline on both datasets. Notably, there is no significant gap in performance between the AnyMAL-13B and AnyMAL-70B variants. This result demonstrates that the underlying LLM capability for image caption generation is an artificial intelligence technique used to automatically generate corresponding captions for images. This technology combines computer vision and natural language processing methods to generate descriptive captions related to the image by analyzing the content and characteristics of the image, as well as understanding the semantics and syntax. Image caption generation has wide applications in many fields, including image search, image annotation, image retrieval, etc. By automating caption generation, image understandability and search engine accuracy can be improved, providing users with a better image retrieval and browsing experience. The task is less impactful, but depends heavily on data size and registration method. .
 The rewrite required is: Human evaluation on multi-modal inference tasks
The rewrite required is: Human evaluation on multi-modal inference tasks
Figure 3 shows that, compared with the baseline ( Compared with LLaVA: 34.4% winning rate and MiniGPT4: 27.0% winning rate), AnyMAL performs strongly and has a smaller gap with the actual manually labeled samples (41.1% winning rate). Notably, models fine-tuned with the full instruction set showed the highest priority winning rate, showing visual understanding and reasoning capabilities comparable to human-annotated responses. It is also worth noting that BLIP-2 and InstructBLIP perform poorly on these open queries (4.1% and 16.7% priority win rate, respectively), although they perform well on the public VQA benchmark (see Table 4) .
 VQA Benchmark
VQA Benchmark
In Table 4, we show the performance of the Hateful Meme dataset, VQAv2 , TextVQA, ScienceQA, VizWiz and OKVQA, and compared with zero-shot results on the respective benchmarks reported in the literature. Our research focuses on zero-shot evaluation to most accurately estimate model performance on open queries at inference time
 Video QA Benchmark
Video QA Benchmark
As shown in Table 6, the study evaluated the model on three challenging video QA benchmarks.
 Regenerate audio subtitles
Regenerate audio subtitles
Table 5 shows the results of regenerating audio subtitles on the AudioCaps benchmark dataset. AnyMAL significantly outperforms other state-of-the-art audio subtitle models in the literature (e.g., CIDEr 10.9pp, SPICE 5.8pp), indicating that the proposed method is not only applicable to vision but also to various modalities. The text 70B model shows clear advantages compared to the 7B and 13B variants.

Interestingly, based on the method, type, and timing of the AnyMAL paper submission, Meta seems to be planning to collect multi-modal data through its newly launched mixed reality/metaverse headset. These research results may be integrated into Meta’s Metaverse product line, or may soon be used in consumer applications
Please read the original article for more details.
The above is the detailed content of Multi-modal version Llama2 is online, Meta releases AnyMAL. For more information, please follow other related articles on the PHP Chinese website!

 微软深化与 Meta 的 AI 及 PyTorch 合作Apr 09, 2023 pm 05:21 PM
微软深化与 Meta 的 AI 及 PyTorch 合作Apr 09, 2023 pm 05:21 PM微软宣布进一步扩展和 Meta 的 AI 合作伙伴关系,Meta 已选择 Azure 作为战略性云供应商,以帮助加速 AI 研发。在 2017 年,微软和 Meta(彼时还被称为 Facebook)共同发起了 ONNX(即 Open Neural Network Exchange),一个开放的深度学习开发工具生态系统,旨在让开发者能够在不同的 AI 框架之间移动深度学习模型。2018 年,微软宣布开源了 ONNX Runtime —— ONNX 格式模型的推理引擎。作为此次深化合作的一部分,Me
 Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM
Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM2月25日消息,Meta在当地时间周五宣布,它将推出一种针对研究社区的基于人工智能(AI)的新型大型语言模型,与微软、谷歌等一众受到ChatGPT刺激的公司一同加入人工智能竞赛。Meta的LLaMA是“大型语言模型MetaAI”(LargeLanguageModelMetaAI)的缩写,它可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者。该公司将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。Meta表示,该模型对算力的要
 Meta这篇语言互译大模型研究,结果对比都是「套路」Apr 11, 2023 pm 11:46 PM
Meta这篇语言互译大模型研究,结果对比都是「套路」Apr 11, 2023 pm 11:46 PM今年 7 月初,Meta AI 发布了一个新的翻译模型,名为 No Language Left behind (NLLB),我们可以将其直译为「一个语言都不能少」。顾名思义,NLLB 可以支持 200 + 语言之间任意互译,Meta AI 还把它开源了。平时你都没见到的语言如卢干达语、乌尔都语等它都能翻译。论文地址:https://research.facebook.com/publications/no-language-left-behind/开源地址:https://github.com/
 曝光Meta Quest 3头显固件:揭示室内物体自动识别功能Sep 07, 2023 pm 01:17 PM
曝光Meta Quest 3头显固件:揭示室内物体自动识别功能Sep 07, 2023 pm 01:17 PM8月31日消息,近日有关虚拟现实领域的令人振奋消息传出,据可靠渠道透露,meta公司即将在9月27日正式发布其全新虚拟现实头显——metaQuest3。这款头显据称拥有颠覆性的深度测绘技术,将为用户带来更加逼真的混合现实体验。这项名为深度测绘的技术被认为是metaQuest3的一项重大创新。该技术使得虚拟数字物体与真实物体能够在同一空间内进行互动,大大提升了混合现实的沉浸感和真实感。一段在Reddit上流传的视频展示了深度测绘功能的惊人表现,不禁让人惊叹不已。从视频中可以看出,metaQuest
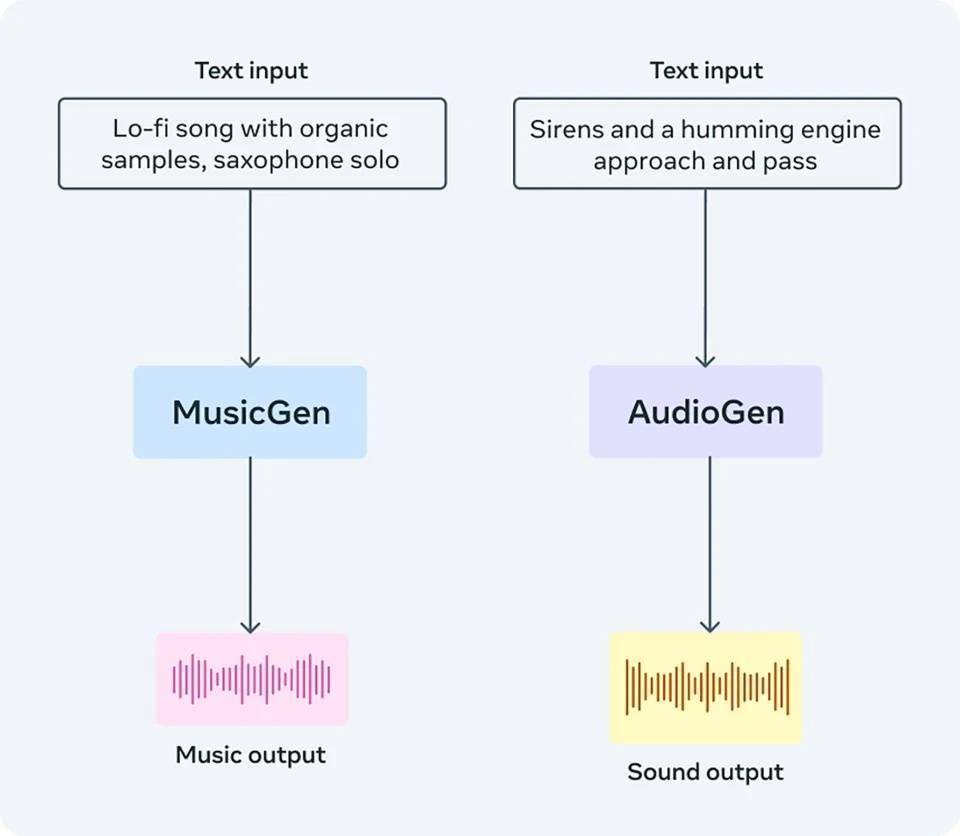 音乐制作元工具AudioCraft发布开源AI工具Aug 04, 2023 am 11:45 AM
音乐制作元工具AudioCraft发布开源AI工具Aug 04, 2023 am 11:45 AM美国东部时间8月2日,Meta发布了一款名为AudioCraft的生成式AI工具,用户可以利用文本提示来创作音乐和音频AudioCraft由三个主要组件构成:MusicGen:使用Meta拥有/特别授权的音乐进行训练,根据文本提示生成音乐。AudioGen:使用公共音效进行训练生成音频或扩展现有音频,后续还可生成环境音效(如狗叫、汽车鸣笛、木地板上的脚步声)。EnCodec(改进版):基于神经网络的音频压缩解码器,可生成更高质量的音乐并减少人工痕迹,或对音频文件进行无损压缩。官方声称,Audio
 抢先发布新一代VR头显,Meta想给苹果一个“下马威”?Jun 03, 2023 am 09:01 AM
抢先发布新一代VR头显,Meta想给苹果一个“下马威”?Jun 03, 2023 am 09:01 AM在游戏、元宇宙等领域的推动下,XR(扩展现实,VR/AR/MR统称)赛道的热度明显获得提升,头显设备也成了“香饽饽”,获得了许多企业的青睐,其中就有Meta(META.US)和苹果(AAPL.US)、字节跳动、索尼等巨头。而这些巨头之间的“故事”还引来了大批“吃瓜群众”。打压竞争对手?Meta赶在苹果之前发布最新版头显众所周知,在全球的大型科技企业中,Meta对元宇宙是最上心的,不惜投入巨资早早进行了布局,而VR头显被视为是元宇宙的入口之一,因此该公司在这一领域也下了大功夫,是VR头显领域的龙头
 Meta推出4年硬件路线图,致力于打造「圣杯」AR眼镜,烧了137亿美元Apr 24, 2023 pm 11:04 PM
Meta推出4年硬件路线图,致力于打造「圣杯」AR眼镜,烧了137亿美元Apr 24, 2023 pm 11:04 PM现在,谁还提元宇宙?2022年,Meta实验室RealityLabs在AR/VR的研发投入已经亏损了137亿美元。比去年(近102亿美元)还要多,简直让人瞠目结舌。也看,生成式AI大爆发,一波ChatGPT狂热潮,让Meta内部重心也有所倾斜。就在前段时间,在公司的季度财报电话会议上,提及「元宇宙」的次数只有7次,而「AI」有23次。做着几乎赔本的买卖,元宇宙就这样凉凉了吗?NoNoNo!Meta近日公布了未来四年VR/AR硬件技术路线图。2025年,发布首款带有显示屏的智能眼镜,以及控制眼镜的
 AI 领域再添一员"猛将",Meta 发布全新大型语言模型LLaMAApr 25, 2023 pm 12:52 PM
AI 领域再添一员"猛将",Meta 发布全新大型语言模型LLaMAApr 25, 2023 pm 12:52 PMChatGTP走红以来,围绕ChatGTP开发出来的AI应用层出不穷;让人们感受到了人工智能的强大!近日,Facebook母公司Meta发布了人工智能大型语言模型(LargeLanguageModelMetaAI)简称LLaMA。扎克伯格在社交媒体上称:”由FAIR团队研发的LLaMA模型是目前世界上水平最高的大型语言模型,目标是帮助研究人员推进他们在人工智能领域的工作!“。与其他大型模型一样,MetaLLaMA的工作原理是将一系列单词作为“输入”并预测下一个单词以递归生成文本。据介


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 English version
Recommended: Win version, supports code prompts!

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

