


How to build an AB experiment system in user growth scenarios?


1. Problems faced by experiments in new user scenarios
1. UG panorama
This is a panoramic view of UG.
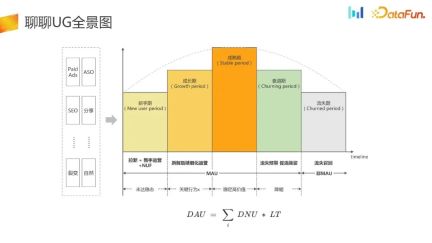
UG Acquire customers and divert traffic to the APP through channels such as Paid Ads, ASO, SEO and other channels. Next, we will do some operations and guidance for novices to activate users and bring them into the maturity stage. Subsequent users may slowly become inactive, enter a decline period, or even enter a churn period. During this period, we will do some early warnings for churn, recall to promote activation, and later some recalls for lost users.
can be summarized as the formula in the above figure, that is, DAU is equal to DNU times LT. All work in the UG scenario can be dismantled based on this formula.
2. Principle of AB experiment

The purpose of AB experiment is to completely randomize the distribution of traffic , using different strategies for the experimental group and different control groups. Finally, scientific decisions are made by combining statistical methods and experimental hypotheses, which constitutes the framework of the entire experiment. There are currently two types of experimental distribution on the market: experimental platform distribution and client local distribution
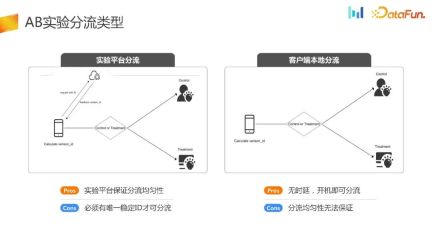
There are prerequisites for experimental platform distribution. It is necessary for the device to obtain a stable ID after completing initialization. Based on this ID, the experimental platform is requested to complete the offloading-related logic, and the offloading ID is returned to the endpoint, and then the endpoint makes corresponding strategies based on the received ID. Its advantage is that it has an experimental platform that can ensure the uniformity and stability of the shunt. Its disadvantage is that the equipment must be initialized before experimental shunting can be carried out.
Another offloading method is client local offloading. This method is relatively niche and is mainly suitable for some UG scenes, advertising screen opening scenes and performance initialization scenes. In this way, all offloading logic is completed when the client is initialized. Its advantages are obvious, that is, there is no delay and the distribution can be carried out immediately after powering on. Logically speaking, its distribution uniformity can also be guaranteed. However, in actual business scenarios, there are often problems with its distribution uniformity. The reasons will be introduced next
3. Problems faced by the new user scenario AB experiment
The first problem actually faced by the UG scenario is to divert traffic as early as possible.
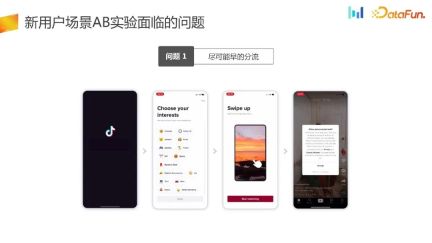
Here is an example, such as the traffic acceptance page here. The product manager feels that the UI can be optimized to improve the core indicators. In such a scenario, we hope that the experiment will be triaged as soon as possible.
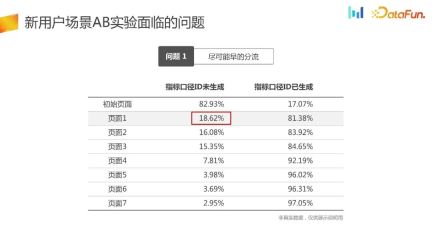
During the offloading process of page 1, the device will be initialized and obtain the ID. 18.62% of users cannot generate IDs. If the traditional experimental platform diversion method is used, 18.62% of users will not be grouped, resulting in an inherent selection bias problem
#In addition, the traffic of new users is very valuable. 18.62% of new users cannot be used in the experiment, which will also cause a great loss in the duration of the experiment and traffic utilization efficiency.

In the future, to solve the problem of offloading experiments as early as possible, we will use the client to offload experiments locally. The advantage is that the offloading is completed when the device is initialized. The principle is that first, when initializing on the terminal, it can generate random numbers by itself, hash the random numbers and then group them in the same way, thereby generating an experimental group and a control group. In principle, it should be possible to ensure that the traffic distribution is even. However, through the set of data in the above figure, we can find that more than 21% of users repeatedly enter different groups.

There is a scenario where users of some very popular products, such as Honor of Kings or Douyin, are easily addicted. New users will uninstall and reinstall multiple times during the experimental cycle. According to the local diversion logic just mentioned, the generation and diversion of random numbers will allow users to enter different groups, so that the diversion ID and statistical ID cannot match one-to-one. This caused the problem of uneven distribution.

In new user scenarios, we also face the problem of experimental evaluation standards.
We have reorganized the time chart of this scenario of new user traffic. On application startup, we chose to offload. Assume that we can achieve uniform distribution timing and produce corresponding strategic effects at the same time. Next, the timing of generating the indicator statistical ID is later than the timing of the strategy effect, and only then can the data be observed. The timing of data observation lags far behind the timing of strategy effects, which will lead to survivor bias
2. New experimental system and its scientific verification
In order to solve the above problems, we proposed a new experimental system and scientifically verified it
1. New user scenario experiment diversion ID selection
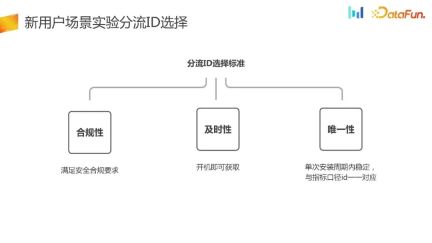
As mentioned before, the requirements for diversion selection for new users will be relatively high, so how to choose the diversion ID for new user experiments? The following are a few principles:
- Compliance, whether it is overseas business or domestic business, safety compliance is first and foremost the lifeline, and safety compliance must be met. Otherwise, the impact will be particularly great once it is removed from the shelves.
- #Timeliness, for new user scenarios, it must be timely, and the offload can be obtained immediately after booting.
- Uniqueness, within a single installation cycle, the shunt ID is stable and can form a one-to-one correspondence with the indicator ID. As can be seen from the data in the figure below, the one-to-one matching ratio between the diversion ID and the indicator calculation caliber ID has reached 99.79%, and the one-to-one ratio between the indicator calculation ID and the diversion ID has also reached 99.59%. Basically, it can be verified that the diversion ID and indicator ID selected according to the standard can achieve a one-to-one match.

2. Scientific verification of diversion capability
After selecting the diversion ID, the diversion capability is often There are two ways, the first is through the experimental platform, and the second is through the end.

After you have the diversion ID, provide the diversion ID to the experimental platform to complete the diversion capability in the experimental platform. As a distribution platform, the most basic thing is to verify its randomness. The first is uniformity. In the same layer of experiments, the traffic is evenly divided into many buckets, and the number of groups in each bucket should be even. It can be simplified here. If there is only one experiment on one layer and it is divided into two groups, a and b, the number of users in the control group and the experimental group should be approximately equal, thereby verifying the uniformity of the diversion capability. Secondly, for multi-layer experiments, the multi-layer experiments should be orthogonal to each other and unaffected. Similarly, it is also necessary to verify the orthogonality between experiments at different layers. Uniformity and orthogonality can be verified through statistical category tests.
After introducing the ID of the diversion selection and the diversion capability, finally we need to verify whether the newly proposed diversion results meet the requirements of the AB experiment from the indicator result level.
3. Scientific verification of diversion results
By using the internal platform, we have conducted multiple AA simulations
Comparison Whether the control group and the experimental group meet the requirements of the experiment on the corresponding indicators. Next, let’s take a look at this set of data.

We sampled some index groups of the t test. It can be understood that for so many experiments, the type one error rate should be at a very small probability. Assume The type one error rate is scheduled to be around 0. 055%, and its confidence interval should actually be around 1000 times, which should be between 0. 0365- 0. 0635. You can see that some of the indicators sampled in the first column are within this execution range, so from the perspective of type one error rate, the existing experimental system is OK.
At the same time, considering that the test is a test of the t statistic, the corresponding t statistic should approximately obey the normal distribution under the distribution of large traffic. You can also test the normal distribution of the t-test statistic. The normal distribution test is used here, and you can see that the test result is also much greater than 0.05, that is, the null hypothesis is established, that is, the t statistic approximately obeys the normal distribution.
For each test, the pvalue of the t statistic test result is approximately uniformly distributed in so many experiments. At the same time, the pvalue can also be uniformly Similar results can also be seen in the distribution test, pvalue_uniform_test, which is also much greater than 0.05. Therefore, the null hypothesis that pvalue approximately obeys a uniform distribution is also OK.
The above has verified the newly proposed experimental diversion system from the one-to-one correspondence between the diversion ID and the indicator calculation caliber, the diversion capability and the diversion result indicator results. scientific nature.
3. Application case analysis
The following will be combined with actual application cases in UG scenarios to explain in detail how to conduct experimental evaluations to solve the previous problems. The third question mentioned
1. New user scenario experimental evaluation

Here is a typical UG traffic acceptance scenario. A lot of optimizations will be done during NUJ new user guidance or new user tasks to improve traffic utilization. The evaluation standard at this time is often retention rate, which is the current common understanding in the industry.
Assuming the process from new user download to installation to first startup, PM feels that such a process is useful for users, especially those who have never experienced it. The threshold for users of this part of the product is too high. Should users be familiar with the product first and experience the hip-hop moment of the product before being guided to log in?
Further, the product manager put forward another hypothesis, that is, for users who have never experienced the product, when a new user logs in or a new user NUJ Reduce resistance in the scene. For users who have already experienced the product and users who have switched devices, the online process is still used

The method of diversion based on the indicator ID first obtains the indicator ID, and then triage. This splitting method is usually uniform, and there is not much difference from the experimental results and retention rate. Judging from such results, it is difficult to make a comprehensive decision. This kind of experiment actually wastes a part of the traffic and has the problem of selection bias. Therefore, we will conduct a local shunt experiment. The following figure shows the results of the local shunt experiment

The number of new devices entering the group will be significant. The difference is believable. At the same time, there is an improvement in retention rate, but it is actually negative in other core indicators, and this negative direction is difficult to understand because it is actually strongly related to retention. Therefore, based on such data, it is difficult to explain or attribute it, and it is also difficult to make comprehensive decisions.
You can observe the situation of users who have been repeatedly added to groups, and you will find that more than 20% of users have been repeatedly assigned to different groups. This destroys the randomness of the AB experiment and makes it difficult to make scientific comparison decisions
Finally, take a look at the results of experiments with the proposed new shunt.

You can divert the traffic when you turn it on. The diverting capacity is guaranteed by the internal platform, which can ensure the uniformity and stability of the diverting to a great extent. . Judging from the experimental data, it is almost close. When doing the square root test, we can also see that it fully meets the needs. At the same time, we can see that the number of effective new devices has increased significantly, by 1%, and the retention rate has also improved. At the same time, if you look at the control group or the experimental group alone, you can see the traffic conversion rate based on the diversion ID to the new device finally generated. The experimental group is 1% higher than the control group. The reason for this result is that the experimental group actually enlarged the user's entry point in NUJ and NUT, making it easier for more users to come in, experience the product, and then stay.

Divide the experimental data into login and non-login parts. It can be found that for users in the experimental group, more users choose non-login. Login mode to experience the product, and the retention rate has also improved. This result is also in line with expectations.
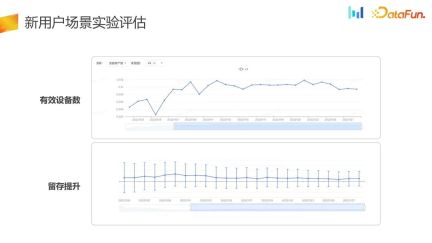
You can see the indicators by daily, and those who entered the group The number of users actually has been written for a long time. Judging by daily, it is increasing steadily, and the retention index has also improved. Compared with the control group, the experimental group has improved in the number of effective devices and retention.

For the scenario of new user traffic acceptance, the evaluation indicators are more evaluated from the retention or short-term LT dimension. Here, the optimization is actually only performed on the one-dimensional space at the LT level
. However, in the new experimental system, the one-dimensional optimization is turned into a two-dimensional optimization. DNU God Shang LT has been improved as a whole, so that the strategy space has changed from one dimension to two dimensions. At the same time, in some scenarios, the loss of part of LT can be accepted.
4. Summary
Finally, let’s summarize the experimental capability building and experimental evaluation standards in new user scenarios.
- UG The existing experimental system in the new user scenario cannot fully solve the problems faced by the evaluation of new user traffic acceptance strategies, and a new experimental system is needed.
- There are several criteria for selecting the offload ID. The first is security compliance, then it can be obtained at the first startup, and the third is within a single installation cycle. is stable and has an injective relationship with the indicator ID.
- Experimental evaluation for new user scenarios is a multi-dimensional optimization. The revenue comes from the effective number of new devices and device retention, unlike the previous evaluation of devices. of retention.
- #Accepting “new” users often brings huge business benefits. The "new" here refers not only to new users, but also to users who have uninstalled and reinstalled.
The above is the detailed content of How to build an AB experiment system in user growth scenarios?. For more information, please follow other related articles on the PHP Chinese website!

 From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AM
From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AMThe legal tech revolution is gaining momentum, pushing legal professionals to actively embrace AI solutions. Passive resistance is no longer a viable option for those aiming to stay competitive. Why is Technology Adoption Crucial? Legal professional
 This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AM
This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AMMany assume interactions with AI are anonymous, a stark contrast to human communication. However, AI actively profiles users during every chat. Every prompt, every word, is analyzed and categorized. Let's explore this critical aspect of the AI revo
 7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AM
7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AMA successful artificial intelligence strategy cannot be separated from strong corporate culture support. As Peter Drucker said, business operations depend on people, and so does the success of artificial intelligence. For organizations that actively embrace artificial intelligence, building a corporate culture that adapts to AI is crucial, and it even determines the success or failure of AI strategies. West Monroe recently released a practical guide to building a thriving AI-friendly corporate culture, and here are some key points: 1. Clarify the success model of AI: First of all, we must have a clear vision of how AI can empower business. An ideal AI operation culture can achieve a natural integration of work processes between humans and AI systems. AI is good at certain tasks, while humans are good at creativity and judgment
 Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AM
Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AMMeta upgrades AI assistant application, and the era of wearable AI is coming! The app, designed to compete with ChatGPT, offers standard AI features such as text, voice interaction, image generation and web search, but has now added geolocation capabilities for the first time. This means that Meta AI knows where you are and what you are viewing when answering your question. It uses your interests, location, profile and activity information to provide the latest situational information that was not possible before. The app also supports real-time translation, which completely changed the AI experience on Ray-Ban glasses and greatly improved its usefulness. The imposition of tariffs on foreign films is a naked exercise of power over the media and culture. If implemented, this will accelerate toward AI and virtual production
 Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AM
Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AMArtificial intelligence is revolutionizing the field of cybercrime, which forces us to learn new defensive skills. Cyber criminals are increasingly using powerful artificial intelligence technologies such as deep forgery and intelligent cyberattacks to fraud and destruction at an unprecedented scale. It is reported that 87% of global businesses have been targeted for AI cybercrime over the past year. So, how can we avoid becoming victims of this wave of smart crimes? Let’s explore how to identify risks and take protective measures at the individual and organizational level. How cybercriminals use artificial intelligence As technology advances, criminals are constantly looking for new ways to attack individuals, businesses and governments. The widespread use of artificial intelligence may be the latest aspect, but its potential harm is unprecedented. In particular, artificial intelligence
 A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AM
A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AMThe intricate relationship between artificial intelligence (AI) and human intelligence (NI) is best understood as a feedback loop. Humans create AI, training it on data generated by human activity to enhance or replicate human capabilities. This AI
 AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AM
AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AMAnthropic's recent statement, highlighting the lack of understanding surrounding cutting-edge AI models, has sparked a heated debate among experts. Is this opacity a genuine technological crisis, or simply a temporary hurdle on the path to more soph
 Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AM
Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AMIndia is a diverse country with a rich tapestry of languages, making seamless communication across regions a persistent challenge. However, Sarvam’s Bulbul-V2 is helping to bridge this gap with its advanced text-to-speech (TTS) t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

