
 Technology peripheralsAIMicrosoft launches small AI model, secretly carries out 'Plan B', has nothing to do with OpenAI
Technology peripheralsAIMicrosoft launches small AI model, secretly carries out 'Plan B', has nothing to do with OpenAI
AI large models will become a keyword in 2023 and are also a hot area for competition among major technology companies. However, the cost of this large model of AI that symbolizes the future is too high, causing even wealthy companies like Microsoft to start considering alternatives. Recent revelations show that some of the 1,500-person research team within Microsoft led by Peter Lee have turned to developing a new LLM, which is smaller and has lower operating costs

Regarding Microsoft’s small-size AI model, clues began to emerge three months ago. In June this year, Microsoft released a paper titled "Textbooks Are All You Need", using "textbook-level" data of only 7 billion tokens to train a 1.3 billion parameter model phi-1, proving that even on a small scale High-quality data can also enable the model to have good performance. In addition, Microsoft Research also released a new pre-trained language model called phi-1.5 based on phi-1, which is suitable for scenarios such as QA Q&A, chat format and code
According to Microsoft, phi-1.5 outperforms a considerable number of large models under benchmarks testing common sense, language understanding, and logical reasoning. In the GPT4AL running score suite with LM-Eval Harness, phi-1.5 is comparable to Meta's open source large model llama-2 with 7 billion parameters, and even surpasses llama-2 in AGIEval score.

Why is Microsoft suddenly developing small-size AI models? It is generally believed that this may be related to issues between OpenAI. Microsoft is a major investor in OpenAI, so it can permanently use OpenAI's existing intellectual property, but it cannot control OpenAI's decision-making. Therefore, it is essential for a giant like Microsoft to develop high-quality, small-sized AI models, whether for its own strategic security considerations or to maintain a favorable position in cooperation with OpenAI
Of course, the current energy consumption of large AI models is a key factor. At the Design Automation Conference earlier this year, AMD Chief Technology Officer Mark Papermaster showed a slide comparing the energy consumption of machine learning systems to global power generation. According to estimates from the International Energy Agency, data centers training large models are increasingly energy-intensive, accounting for 1.5% to 2% of global electricity consumption, equivalent to the electricity consumption of the entire United Kingdom. It is expected that by 2030, this proportion will rise to 4%

According to a relevant report released by Digital Information World, the energy consumption generated by data centers for training AI models will be three times that of conventional cloud services. By 2028, data center power consumption will be close to 4,250 megawatts, an increase of 212% from 2023. times. The power consumption of OpenAI training GPT-3 is 1.287 gigawatt hours, which is approximately equivalent to the power consumption of 120 American households for one year. But this is only the initial power consumption of training the AI model, which only accounts for 40% of the power consumed when the model is actually used.
According to the 2023 environmental report released by Google, training large AI models will not only consume a lot of energy, but also consume a lot of water resources. According to the report, Google consumed 5.6 billion gallons (approximately 21.2 billion liters) of water in 2022, equivalent to the water consumption of 37 golf courses. Of these, 5.2 billion gallons are used in Google’s data centers, an increase of 20% from 2021
High energy consumption of large AI models is normal. In the words of ARM Senior Technical Director Ian Bratt, "AI computing needs cannot be met. The larger the network scale, the better the results, the more problems that can be solved, and the power usage is proportional to the network scale."

Some artificial intelligence practitioners said that before the epidemic, the energy consumption required to train a Transformer model was in the range of 27 kilowatt hours. However, now the number of parameters of the Transformer model has increased from 50 million to 200 million, and the energy consumption has exceeded 500,000 kilowatt hours. In other words, the number of parameters increased four times, but the energy consumption increased by more than 18,000 times. In a sense, the various innovative functions brought by large-scale artificial intelligence models actually come at the expense of high processing performance and energy consumption
More electricity drives more GPUs for AI training, and a large amount of water is consumed to cool the GPUs. This is the problem. So much so that it was revealed that Microsoft is developing a roadmap to operate data centers using electricity generated by small nuclear reactors. What's more, even if ESG ("environmental, social and governance") is not mentioned, it is valuable to study small-size models purely from a cost perspective.

As we all know, NVIDIA, which has built the CUDA ecosystem, is the biggest beneficiary of this round of AI boom, and has already occupied 70% of the AI chip market. Nowadays, computing cards such as H100 and A100 are hard to find. But the current situation is that purchasing computing power from NVIDIA has become an important factor driving up the costs of AI manufacturers. Therefore, a small size model means that it requires less computing resources, and you only need to purchase fewer GPUs to solve the problem.
Although the more powerful large-scale models are indeed excellent, the commercialization of large-scale models is still in its infancy, and the only person making a lot of money is NVIDIA's role of "selling shovels." Therefore, in this case, Microsoft naturally intends to change the status quo
The above is the detailed content of Microsoft launches small AI model, secretly carries out 'Plan B', has nothing to do with OpenAI. For more information, please follow other related articles on the PHP Chinese website!

 AI大模型浪潮下算力需求爆增,商汤“大模型+大算力”赋能多产业发展Jun 09, 2023 pm 07:35 PM
AI大模型浪潮下算力需求爆增,商汤“大模型+大算力”赋能多产业发展Jun 09, 2023 pm 07:35 PM近日,以“AI引领时代,算力驱动未来”为主题的“临港新片区智算大会”举行。会上,新片区智算产业联盟正式成立,商汤科技作为算力提供企业成为联盟一员,同时商汤科技被授予“新片区智算产业链链主”企业。作为临港算力生态的积极参与者,商汤目前已建设了亚洲目前最大的智能计算平台之一——商汤AIDC,可以输出5000Petaflops的总算力,可支持20个千亿参数量的超大模型同时训练。以AIDC为底座、前瞻打造的商汤大装置SenseCore,致力于打造高效率、低成本、规模化的下一代AI基础设施与服务,赋能人工
 研究者:AI模型推理环节耗电更多,2027年行业用电将堪比荷兰Oct 14, 2023 am 08:25 AM
研究者:AI模型推理环节耗电更多,2027年行业用电将堪比荷兰Oct 14, 2023 am 08:25 AMIT之家10月13日消息,《Cell》的姐妹期刊《Joule》本周出版了一篇名为《持续成长的人工智慧能源足迹(Thegrowingenergyfootprintofartificialintelligence)》论文。通过查询,我们了解到这篇论文是由科研机构Digiconomist的创始人AlexDeVries发表的。他声称未来人工智能的推理性能可能会消耗大量的电力,预计到2027年,人工智能的用电量可能会相当于荷兰一年的电力消耗量AlexDeVries表示,外界一向认为训练一个AI模型“AI最
 一言不合就跑分,国内AI大模型为何沉迷于“刷榜”Dec 02, 2023 am 08:53 AM
一言不合就跑分,国内AI大模型为何沉迷于“刷榜”Dec 02, 2023 am 08:53 AM“不服跑个分”这句话,我相信关注手机圈的朋友一定不会感到陌生。例如,安兔兔、GeekBench等理论性能测试软件因为能够在一定程度上反映手机的性能,因此备受玩家的关注。同样地,在PC处理器、显卡上也有相应的跑分软件来衡量它们的性能既然"万物皆可跑分",目前最火爆的AI大模型也开始参与跑分比拼,尤其是在"百模大战"开始后,几乎每天都有突破,各家都自称为"跑分第一"国产AI大模型在性能评分方面几乎从未落后,但在用户体验方面却始终无法超越GP
 中科院物理所联合院网络中心发布AI模型MatChatNov 03, 2023 pm 08:13 PM
中科院物理所联合院网络中心发布AI模型MatChatNov 03, 2023 pm 08:13 PMIT之家11月3日消息,中科院物理所官网发文,近期,中国科学院物理研究所/北京凝聚态物理国家研究中心SF10组和中国科学院计算机网络信息中心共同合作,将AI大模型应用于材料科学领域,将数万个化学合成路径数据投喂给大语言模型LLAMA2-7b,从而获得了MatChat模型,可用来预测无机材料的合成路径。IT之家注意到,该模型可根据所询问的结构进行逻辑推理,并输出相应的制备工艺和配方。目前已部署上线,并向所有材料科研人员开放使用,为材料研究和创新带来了新启发和新思路。该工作为大语言模型在细分科学领域
 中国联通发布图文AI大模型,可实现以文生图、视频剪辑Jun 29, 2023 am 09:26 AM
中国联通发布图文AI大模型,可实现以文生图、视频剪辑Jun 29, 2023 am 09:26 AM驱动中国2023年6月28日消息,今日在上海世界移动通信大会期间,中国联通发布图文大模型“鸿湖图文大模型1.0”。中国联通称,鸿湖图文大模型是首个面向运营商增值业务的大模型。第一财经记者了解到,鸿湖图文大模型目前拥有8亿训练参数和20亿训练参数两个版本,可以实现以文生图、视频剪辑、以图生图等功能。此外,中国联通董事长刘烈宏在今天的主题演讲中也表示,生成式AI正在迎来发展的奇点,未来2年内50%的工作将受到人工智能深刻影响。
 四倍提速,字节跳动开源高性能训练推理引擎LightSeq技术揭秘May 02, 2023 pm 05:52 PM
四倍提速,字节跳动开源高性能训练推理引擎LightSeq技术揭秘May 02, 2023 pm 05:52 PMTransformer模型出自于Google团队2017年发表的论文《Attentionisallyouneed》,该论文中首次提出了使用Attention替换Seq2Seq模型循环结构的概念,给NLP领域带来了极大冲击。且随着近年来研究的不断推进,Transformer相关技术逐渐由自然语言处理流向其他领域。截止目前,Transformer系列模型已经成为了NLP、CV、ASR等领域的主流模型。因此,如何更快地训练和推理Transformer模型已成为业界的一个重要研究方向。低精度量化技术能够
 你必须了解的关于谷歌最新AI模型Gemini的全部信息Dec 14, 2023 pm 08:57 PM
你必须了解的关于谷歌最新AI模型Gemini的全部信息Dec 14, 2023 pm 08:57 PM什么是GoogleGemini?Gemini是谷歌推出的一种最新的、功能强大的AI模型,它不仅可以理解文本,还可以理解图像、视频和音频。作为一种多模式模型,Gemini被描述为能够完成数学、物理和其他领域的复杂任务,以及理解和生成各种编程语言的高质量代码目前,它可以与GoogleBard和GooglePixel8进行整合,并且将逐渐整合到其他Google服务中谷歌DeepMind的CEO兼联合创始人丹尼斯·哈萨比斯说:“Gemini是谷歌整个团队的大规模合作成果,包括我们在谷歌研究中心的同事。它
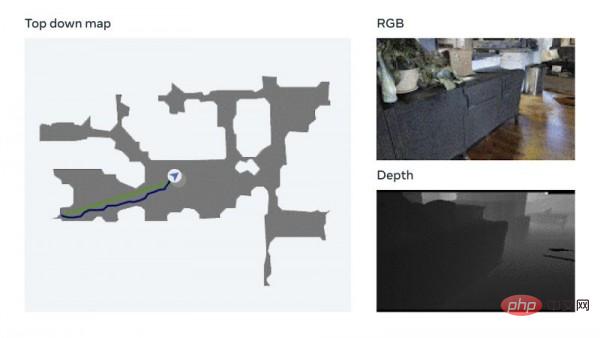 Meta研究人员做出AI新尝试:教机器人无需地图或训练实现物理导航Apr 09, 2023 pm 08:31 PM
Meta研究人员做出AI新尝试:教机器人无需地图或训练实现物理导航Apr 09, 2023 pm 08:31 PMMeta Platforms公司人工智能部门日前表示,他们正在教AI模型如何在少量训练数据支持下学会在物理世界中行走,目前已经取得了快速进展。这项研究能够显著缩短AI模型获得视觉导航能力的时间。以前,实现这类目标要需要利用大量数据集配合重复“强化学习”才能实现。Meta AI研究人员表示,这项关于AI视觉导航的探索将给虚拟世界带来重大影响。而项目的基本思路并不复杂:帮助AI像人类那样,单纯通过观察和探索实现在物理空间导航。Meta AI部门解释道,“比如,如果要让AR眼镜指引我们找到钥匙,就必须


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Atom editor mac version download
The most popular open source editor

