
 Backend DevelopmentPython TutorialPython for NLP: How to handle PDF files containing multiple chapters?
Backend DevelopmentPython TutorialPython for NLP: How to handle PDF files containing multiple chapters?

Python for NLP: How to handle PDF files containing multiple chapters?
In natural language processing (NLP) tasks, we often need to process PDF files containing multiple chapters. These documents are often academic papers, novels, technical manuals, etc., and each chapter has its own specific format and content. This article will introduce how to use Python to process such PDF files and provide specific code examples.
First, we need to install some Python libraries to help us process PDF files. The most commonly used ones are PyPDF2 and pdfminer.six. We can use the pip command to install them:
pip install PyPDF2 pip install pdfminer.six
Next, we can use the PyPDF2 library to read the PDF file and get the chapter information in it. Here is a code example that reads a PDF file and prints each chapter title:
import PyPDF2
def extract_chapter_titles(file_path):
pdf_file = open(file_path, 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
content = page.extract_text()
# 根据具体情况提取章节标题
# 例如,可以通过正则表达式来匹配章节标题
chapter_title = extract_title_using_regex(content)
print("章节标题:", chapter_title)
pdf_file.close()
file_path = "path/to/pdf/file.pdf"
extract_chapter_titles(file_path)In this example, we use the PyPDF2 library to open the PDF file and create a PdfFileReader object. By looping through each page and using the extract_text() method to extract the page content, we can get a string containing all the text content. Next, we can use methods such as regular expressions to match and extract chapter titles.
In addition to extracting chapter titles, sometimes we also need to divide PDF files into multiple sub-files according to chapters. This helps us process the content of each chapter more easily. The following is a code example that divides a PDF file according to chapters and saves it as multiple sub-files:
import PyPDF2
def split_pdf_by_chapter(file_path):
pdf_file = open(file_path, 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
content = page.extract_text()
# 根据具体情况提取章节标题
# 例如,可以通过正则表达式来匹配章节标题
chapter_title = extract_title_using_regex(content)
new_pdf = PyPDF2.PdfFileWriter()
new_pdf.addPage(page)
new_file_name = chapter_title + ".pdf"
new_file_path = "path/to/output/folder/" + new_file_name
with open(new_file_path, "wb") as new_file:
new_pdf.write(new_file)
pdf_file.close()
file_path = "path/to/pdf/file.pdf"
split_pdf_by_chapter(file_path)In this example, we first create a PdfFileWriter object and add the pages of each chapter to it. Then, we create a new PDF file based on the chapter title and write the added pages into it.
It should be noted that the above example is just a simple example. In practice, you may need to modify it according to the specific PDF file structure and characteristics. Different PDF files may have different structures and formats, and you may need to do some preprocessing or use more complex methods to extract chapter titles and divide the PDF file.
To summarize, using Python to process PDF files containing multiple chapters is a common NLP task. By using libraries such as PyPDF2, we can easily read PDF files and extract chapter titles and content from them, or divide PDF files into multiple sub-files according to chapters. I hope the code examples provided in this article will be helpful to your work.
The above is the detailed content of Python for NLP: How to handle PDF files containing multiple chapters?. For more information, please follow other related articles on the PHP Chinese website!

 如何利用Python for NLP快速清洗和处理PDF文件中的文本?Sep 30, 2023 pm 12:41 PM
如何利用Python for NLP快速清洗和处理PDF文件中的文本?Sep 30, 2023 pm 12:41 PM如何利用PythonforNLP快速清洗和处理PDF文件中的文本?摘要:近年来,自然语言处理(NLP)在实际应用中发挥重要作用,而PDF文件是常见的文本存储格式之一。本文将介绍如何利用Python编程语言中的工具和库来快速清洗和处理PDF文件中的文本。具体而言,我们将重点介绍使用Textract、PyPDF2和NLTK库来提取PDF文件中的文本、清洗文本
 如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM
如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM如何利用PythonforNLP将PDF文件中的文本进行翻译?随着全球化的进程日益加深,跨语言翻译的需求也越来越大。而PDF文件作为一种常见的文档形式,其中可能包含了大量的文本信息。如果我们想将PDF文件中的文字内容进行翻译,可以运用Python的自然语言处理(NLP)技术来实现。本文将介绍一种利用PythonforNLP进行PDF文本翻译的方法,并
 如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM
如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM如何利用PythonforNLP处理PDF文件中的表格数据?摘要:自然语言处理(NaturalLanguageProcessing,简称NLP)是一个涉及计算机科学和人工智能领域的重要领域,而处理PDF文件中的表格数据是NLP中一个常见的任务。本文将介绍如何使用Python和一些常用的库来处理PDF文件中的表格数据,包括提取表格数据、数据预处理和转换
 Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PM
Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PMPythonforNLP:如何处理包含多个章节的PDF文件?在自然语言处理(NLP)任务中,我们常常需要处理包含多个章节的PDF文件。这些文件往往是学术论文、小说、技术手册等,每个章节都有其特定的格式和内容。本文将介绍如何使用Python处理这类PDF文件,并提供具体的代码示例。首先,我们需要安装一些Python库来帮助我们处理PDF文件。其中最常用的是
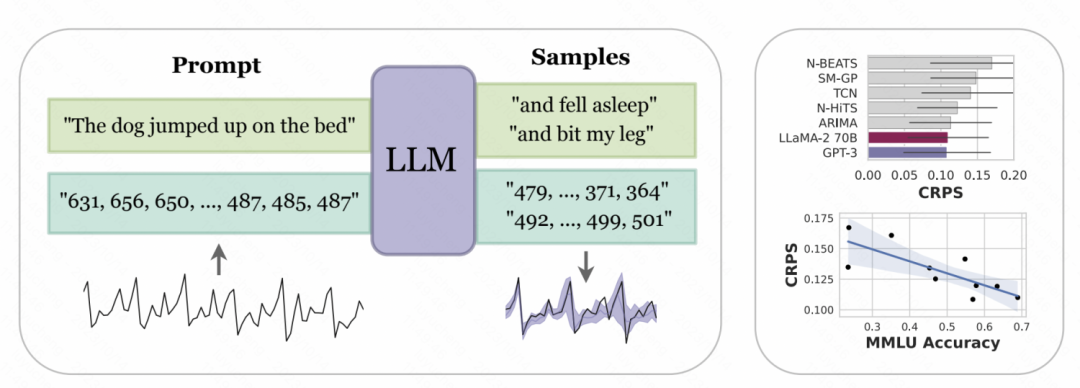 一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM
一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM今天跟大家聊一聊大模型在时间序列预测中的应用。随着大模型在NLP领域的发展,越来越多的工作尝试将大模型应用到时间序列预测领域中。这篇文章介绍了大模型应用到时间序列预测的主要方法,并汇总了近期相关的一些工作,帮助大家理解大模型时代时间序列预测的研究方法。1、大模型时间序列预测方法最近三个月涌现了很多大模型做时间序列预测的工作,基本可以分为2种类型。重写后的内容:一种方法是直接使用NLP的大型模型进行时间序列预测。在这种方法中,使用GPT、Llama等NLP大型模型来进行时间序列预测,关键在于如何将
 Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AM
Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AMPythonforNLP:如何从PDF文件中提取并分析脚注和尾注引言:自然语言处理(NLP)是计算机科学和人工智能领域中的一个重要研究方向。PDF文件作为一种常见的文档格式,在实际应用中经常遇到。本文介绍如何使用Python从PDF文件中提取并分析脚注和尾注,为NLP任务提供更全面的文本信息。文章将结合具体的代码示例进行介绍。一、安装和导入相关库要实现从
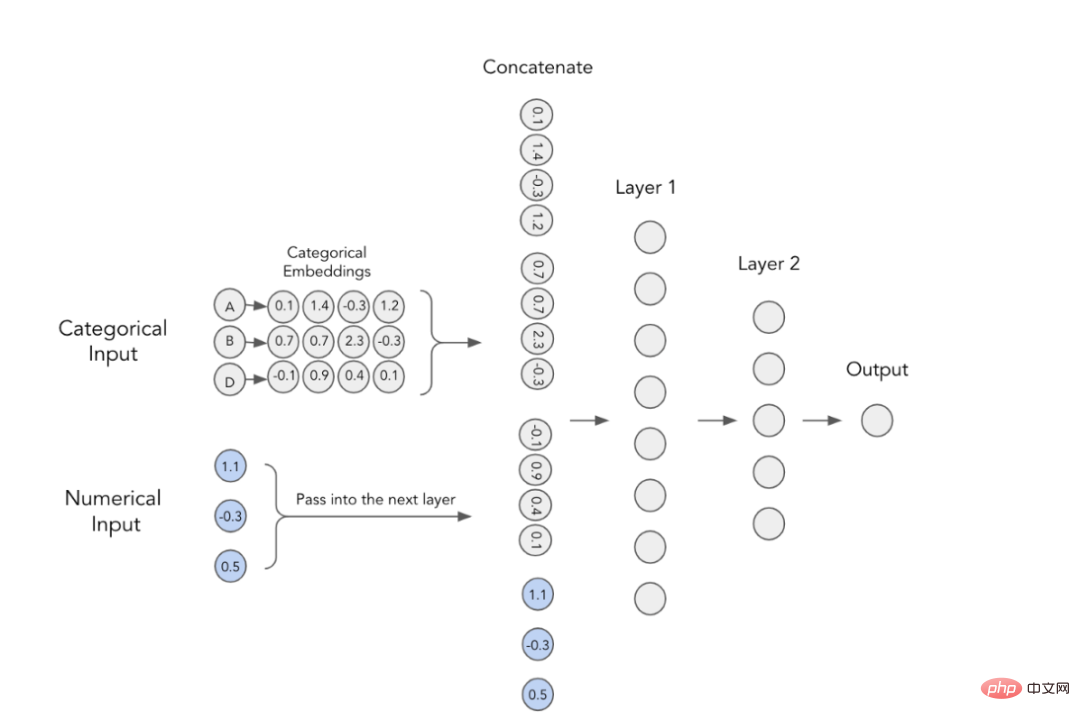 TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM
TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM如今,转换器(Transformers)成为大多数先进的自然语言处理(NLP)和计算机视觉(CV)体系结构中的关键模块。然而,表格式数据领域仍然主要以梯度提升决策树(GBDT)算法为主导。于是,有人试图弥合这一差距。其中,第一篇基于转换器的表格数据建模论文是由Huang等人于2020年发表的论文《TabTransformer:使用上下文嵌入的表格数据建模》。本文旨在提供该论文内容的基本展示,同时将深入探讨TabTransformer模型的实现细节,并向您展示如何针对我们自己的数据来具体使用Ta
 用Python for NLP快速处理文本PDF文件的技巧Sep 28, 2023 am 11:57 AM
用Python for NLP快速处理文本PDF文件的技巧Sep 28, 2023 am 11:57 AM用PythonforNLP快速处理文本PDF文件的技巧随着数字化时代的到来,大量的文本数据以PDF文件的形式存储。对这些PDF文件进行文本处理,以提取信息或进行文本分析是自然语言处理(NLP)中的一个关键任务。本文将介绍如何使用Python来快速处理文本PDF文件,并提供具体的代码示例。首先,我们需要安装一些Python库来处理PDF文件和文本数据。主要


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 Chinese version
Chinese version, very easy to use

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

