



How to process text PDF files with Python for NLP?
With the rapid development of artificial intelligence, Natural Language Processing (NLP) has been widely used in various fields. As the basis of NLP processing, how to extract text data from PDF files has become an important issue. This article will introduce how to use some libraries in Python to process text PDF files and provide specific code examples.
First, we need to install some Python libraries in order to process PDF files. We will use the two libraries PyPDF2 and pdfminer.six. If you haven't installed them yet, you can install them with the following command:
pip install PyPDF2 pip install pdfminer.six
After installing the required libraries, we can start processing PDF files. The following is a sample code that uses the PyPDF2 library to extract text:
import PyPDF2
def extract_text_from_pdf(file_path):
text = ''
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfFileReader(file)
for page_num in range(reader.numPages):
page = reader.getPage(page_num)
text += page.extract_text()
return text
# 调用函数来提取文本
pdf_file = 'example.pdf'
text = extract_text_from_pdf(pdf_file)
print(text)The above code first imports the PyPDF2 library, and then defines a function named extract_text_from_pdf. This function loops through all pages of the PDF and extracts the text of each page using the extract_text method. Finally, concatenate all extracted texts and return the result.
Next, we will introduce how to use the pdfminer.six library to process PDF files. The pdfminer.six library is a Python 3-compatible version of PDFMiner that provides better functionality for parsing PDF files. The following is a sample code that uses the pdfminer.six library to extract text:
from pdfminer.high_level import extract_text
def extract_text_from_pdf(file_path):
text = extract_text(file_path)
return text
# 调用函数来提取文本
pdf_file = 'example.pdf'
text = extract_text_from_pdf(pdf_file)
print(text)In the above code, we first imported the extract_text function, which parses the PDF file and extracts the text. Then, we define a function called extract_text_from_pdf, which calls the extract_text function to extract text. Finally, we print out the extracted text by calling this function.
In addition to extracting text, you can also use other libraries to perform more complex processing on PDF files, such as extracting images, extracting tables, etc. For example, you can use the pdf2image library to convert pages in a PDF file into image files:
from pdf2image import convert_from_path
def convert_pdf_to_images(file_path):
images = convert_from_path(file_path)
return images
# 调用函数将PDF转换为图片
pdf_file = 'example.pdf'
images = convert_pdf_to_images(pdf_file)
for i, image in enumerate(images):
image.save(f'page{i}.jpg', 'JPEG')In the above code, we first import the convert_from_path function, which can convert pages in a PDF file into images. Then, we define a function called convert_pdf_to_images, which calls the convert_from_path function to convert PDF files to images. Finally, we loop through the image list and save each image as a JPEG file.
To sum up, this article introduces how to use libraries such as PyPDF2, pdfminer.six and pdf2image in Python to process text PDF files, and provides corresponding code examples. By using these libraries, we can easily extract text, images and other information from PDF files, which facilitates subsequent natural language processing tasks. I hope this article will be helpful to you in NLP processing!
The above is the detailed content of How to process text PDF files with Python for NLP?. For more information, please follow other related articles on the PHP Chinese website!

 如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM
如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM如何利用PythonforNLP将PDF文件中的文本进行翻译?随着全球化的进程日益加深,跨语言翻译的需求也越来越大。而PDF文件作为一种常见的文档形式,其中可能包含了大量的文本信息。如果我们想将PDF文件中的文字内容进行翻译,可以运用Python的自然语言处理(NLP)技术来实现。本文将介绍一种利用PythonforNLP进行PDF文本翻译的方法,并
 如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM
如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM如何利用PythonforNLP处理PDF文件中的表格数据?摘要:自然语言处理(NaturalLanguageProcessing,简称NLP)是一个涉及计算机科学和人工智能领域的重要领域,而处理PDF文件中的表格数据是NLP中一个常见的任务。本文将介绍如何使用Python和一些常用的库来处理PDF文件中的表格数据,包括提取表格数据、数据预处理和转换
 详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM
详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于Seaborn的相关问题,包括了数据可视化处理的散点图、折线图、条形图等等内容,下面一起来看一下,希望对大家有帮助。
 Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PM
Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PMPythonforNLP:如何处理包含多个章节的PDF文件?在自然语言处理(NLP)任务中,我们常常需要处理包含多个章节的PDF文件。这些文件往往是学术论文、小说、技术手册等,每个章节都有其特定的格式和内容。本文将介绍如何使用Python处理这类PDF文件,并提供具体的代码示例。首先,我们需要安装一些Python库来帮助我们处理PDF文件。其中最常用的是
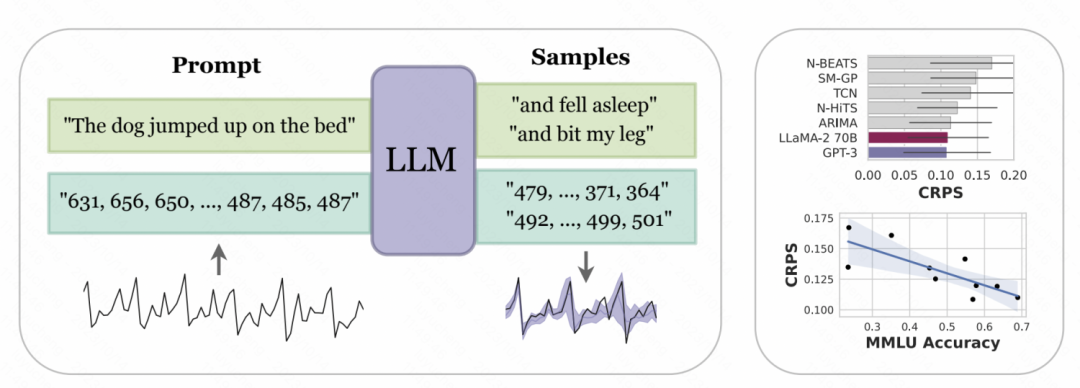 一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM
一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM今天跟大家聊一聊大模型在时间序列预测中的应用。随着大模型在NLP领域的发展,越来越多的工作尝试将大模型应用到时间序列预测领域中。这篇文章介绍了大模型应用到时间序列预测的主要方法,并汇总了近期相关的一些工作,帮助大家理解大模型时代时间序列预测的研究方法。1、大模型时间序列预测方法最近三个月涌现了很多大模型做时间序列预测的工作,基本可以分为2种类型。重写后的内容:一种方法是直接使用NLP的大型模型进行时间序列预测。在这种方法中,使用GPT、Llama等NLP大型模型来进行时间序列预测,关键在于如何将
 分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AM
分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AMVS Code的确是一款非常热门、有强大用户基础的一款开发工具。本文给大家介绍一下10款高效、好用的插件,能够让原本单薄的VS Code如虎添翼,开发效率顿时提升到一个新的阶段。
 Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AM
Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AMPythonforNLP:如何从PDF文件中提取并分析脚注和尾注引言:自然语言处理(NLP)是计算机科学和人工智能领域中的一个重要研究方向。PDF文件作为一种常见的文档格式,在实际应用中经常遇到。本文介绍如何使用Python从PDF文件中提取并分析脚注和尾注,为NLP任务提供更全面的文本信息。文章将结合具体的代码示例进行介绍。一、安装和导入相关库要实现从
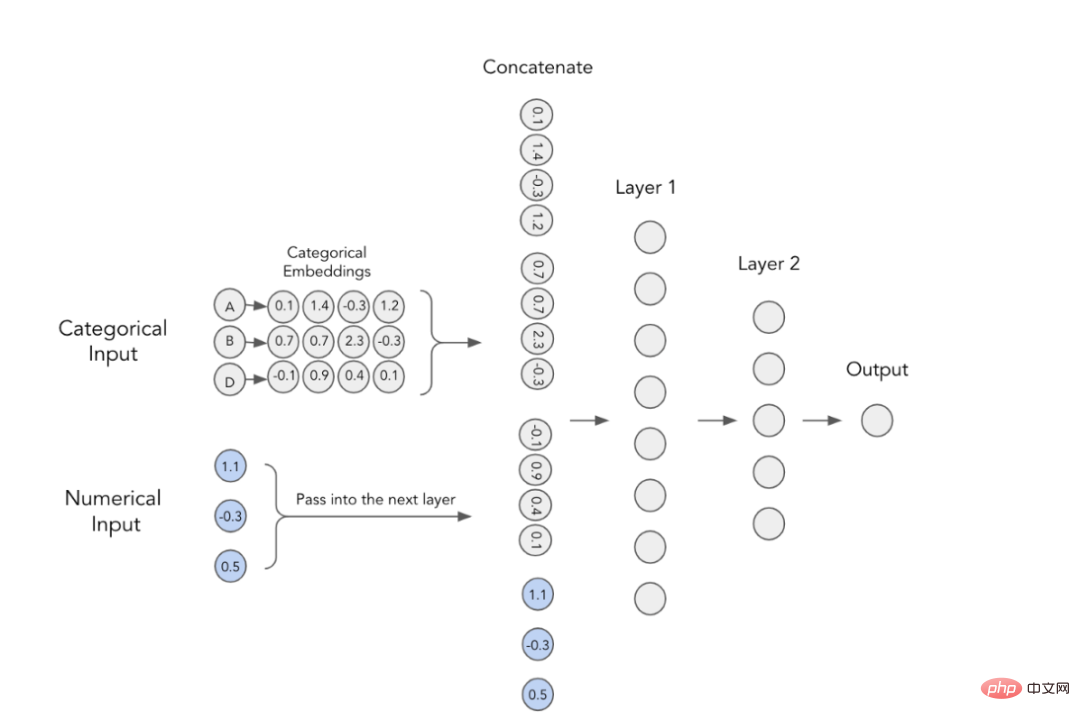 TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM
TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM如今,转换器(Transformers)成为大多数先进的自然语言处理(NLP)和计算机视觉(CV)体系结构中的关键模块。然而,表格式数据领域仍然主要以梯度提升决策树(GBDT)算法为主导。于是,有人试图弥合这一差距。其中,第一篇基于转换器的表格数据建模论文是由Huang等人于2020年发表的论文《TabTransformer:使用上下文嵌入的表格数据建模》。本文旨在提供该论文内容的基本展示,同时将深入探讨TabTransformer模型的实现细节,并向您展示如何针对我们自己的数据来具体使用Ta


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Chinese version
Chinese version, very easy to use

Dreamweaver Mac version
Visual web development tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

