

 Technology peripheralsAIHow is AI Agent implemented? 6 photos of 4090 magic modified Llama2: splitting tasks and calling functions with one command
Technology peripheralsAIHow is AI Agent implemented? 6 photos of 4090 magic modified Llama2: splitting tasks and calling functions with one commandHow is AI Agent implemented? 6 photos of 4090 magic modified Llama2: splitting tasks and calling functions with one command

AI Agent is currently a hot field. In a long article [1] written by LilianWeng, OpenAI application research director, she proposed the concept of Agent = LLM memory planning skills tool
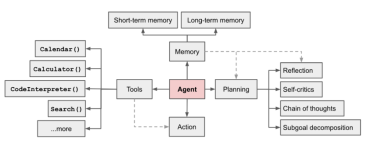
Figure 1 Overview of a LLM-powered autonomous agent system
Agent The function is to use LLM's powerful language understanding and logical reasoning capabilities to call tools to help humans complete tasks. However, this also brings some challenges. For example, the ability of the basic model determines the efficiency of the Agent calling tools, but the basic model itself has problems such as large model illusion.
This article starts with "Input Take the scenario of "automatic splitting of complex tasks and function calls with an instruction" as an example to build the basic Agent process, and focus on explaining how to successfully build "task" through "Basic Model Selection", "PromptDesign", etc. Split" and "Function Call" modules.
The rewritten content is: Address:
https://sota. jiqizhixin.com/project/smart_agent
GitHub Repo:
Needs to be rewritten The content is: https://github.com/zzlgreat/smart_agent
Task splitting & function calling Agent process
For the implementation of "input A section of instructions automatically implements complex task splitting and function calling." The Agent process of project construction is as follows:
- planner: According to User-entered instructions split tasks. Determine the tool list toolkit you have, and tell the planner, a large model that splits tasks, which tools you have and what tasks you need to complete. The planner splits the tasks into plans 1, 2, 3...
- distributor: is responsible for selecting the appropriate tool to toolkit the execution plan. The function calling model requires selecting corresponding tools according to different plans.
- worker: Responsible for calling tasks in the toolbox and returning the results of task calls.
- solver: The compiled distribution plan and corresponding results are combined into a long story, which is then summarized by the solver.
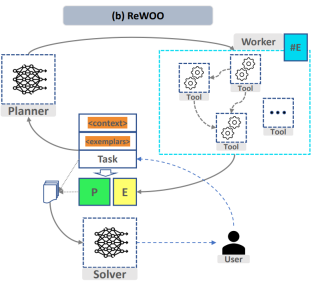
##Figure 1 "ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models"
In order to realize the above process, in the "Task Splitting" and "Function Calling" modules, the project designed two fine-tuning models respectively to achieve the function of splitting complex tasks and calling custom functions on demand. The summarized model solver can be the same as the split task model
Fine-tuned task split & function call model
2.1 Summary of fine-tuning experience
In the "Task Splitting" module, large models need to have the ability to decompose complex tasks into simple tasks. The success of "task splitting" mainly depends on two factors:
- Basic model selection: In order to split complex tasks, Choosing the basic model for fine-tuning requires good understanding and generalization capabilities, that is, splitting tasks not seen in the training set according to prompt instructions. Currently, it is easier to do this by choosing a large model with high parameters.
- Prompt design: Can the prompt successfully call the model’s thinking chain and split the task into sub- Task.
At the same time, we hope that the output format of the task splitting model under a given prompt template can be as relatively fixed as possible, but it will not overfit and lose the original characteristics of the model. For reasoning and generalization capabilities, lora fine-tuning qv layer is used here to make as few structural changes to the original model as possible.
In the "Function Call" module, large models need to have the ability to stably call tools to adapt to the requirements of processing tasks:
- Loss function adjustment: In addition to the generalization ability and Prompt design of the selected basic model itself, in order to achieve the output of the model to be as fixed as possible and to call it stably according to the output For the required functions, use the "prompt loss-mask" method [2] for qlora training (see below for details), and use the trick of inserting eos tokens in qlora fine-tuning to stabilize the model by magically changing the attention mask. Output.
In addition, in terms of computing power usage, fine-tuning and inference of large language models under low computing power conditions are achieved through lora/qlora fine-tuning, and quantitative deployment is adopted way to further lower the threshold of reasoning.
2.2 Basic model selection
For selecting the "task splitting" model, we hope that the model has strong generalization ability and certain thinking chain ability. In this regard, we can refer to the Open LLM rankings on HuggingFace to select models. We are more concerned about the test MMLU and comprehensive score Average
# that measures the multi-task accuracy of the text model. 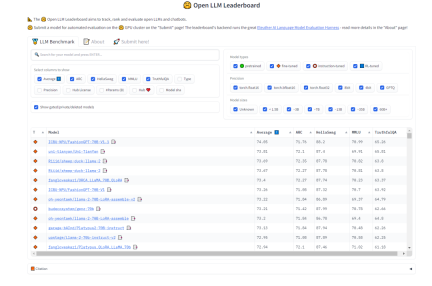
##The content that needs to be rewritten is: Figure 2 HuggingFace open LLM ranking (0921)
The task splitting model model selected for this project is:
- ##AIDC-ai-business/Marcoroni-70B: This model Based on Llama2 70B fine-tuning, responsible for splitting tasks. According to the Open LLM Leaderboard on HuggingFace, the MMLU and average of this model are relatively high, and a large amount of Orca-style data is added to the training process of this model, which is suitable for multiple rounds of dialogue. In plan-distribute-work-plan-work ...the performance will be better in the summary process.
The function call model model selected for this project is:
- codellama 34b/7b: The model responsible for function calls. This model is trained using a large amount of code data. The code data must contain a large number of natural language descriptions of functions. For given The description of definite functions has good zero-shot capability.
Instruction data set preparation
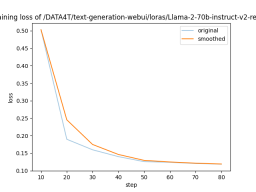
在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4 需要进行针对 Marcoroni-70B 的 lora 微调 全部选择完成后,新建一个训练的 bash 脚本,内容如下: 这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。 需要重新写的内容是:图4 6 卡 4090 训练带宽速度 共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。 需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线 以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。 2)针对 codellama 的 qlora 微调 根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛 在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括: 现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载 需要重新编写的内容是:1)测试方法 Given a complex task description that is not in the training set, add functions and corresponding descriptions that are not included in the training set to the toolkit. If the planner can complete the task splitting, the distributor can call the function, and the solver can summarize the results based on the entire process. The content that needs to be rewritten is: 2) Test results Task splitting: first use text-generation -webui quickly tests the effect of the task splitting model, as shown in the following figure: ##Figure 6 Task splitting test results You can write a simple restful_api interface here to facilitate calling in the agent test environment (see project code fllama_api.py). Function call: A simple planner-distributor-worker-solver logic has been written in the project. Next let's test this task. Enter a command: what movies did the director of 'Killers of the Flower Moon' direct? List one of them and search it in bilibili. The function "Search bilibili" is not included in the project's function call training set. At the same time, this movie is also a new movie that has not been released yet. It is not sure whether the training data of the model itself is included. You can see that the model splits the input instructions nicely: Multiple function calls at the same time The following results were obtained: The click result is Goodfellas, which matches the director of the movie. This project takes the scenario of "entering a command to automatically realize complex task splitting and function calling" as an example to design a set of Basic agent process: toolkit-plan-distribute-worker-solver to implement an agent that can perform elementary complex tasks that cannot be completed in one step. Through the selection of basic models and fine-tuning of lora, fine-tuning and inference of large models can be completed under low computing power conditions. And adopt a quantitative deployment method to further lower the threshold of reasoning. Finally, an example of searching for other works of a movie director was implemented through this pipeline, and basic complex tasks were completed. Limitations: This article only designs function calls and task splitting based on the toolkit for search and basic operations. The toolset used is very simple and doesn't have much design. There is not much consideration for the fault tolerance mechanism. Through this project, everyone can continue to explore applications in the RPA field, further improve the agent process, and achieve a higher degree of intelligent automation to improve the manageability of the process.
Set reductinotallow='none' to ensure that a loss value is returned for each position in the sequence, rather than a sum or average.
2.3 Hardware requirements:
##2.4 Prompt format design
In terms of task splitting, this project uses the Prompt format designed by the planner in the large language model efficient reasoning framework ReWOO (Reasoning WithOut Observation). Just replace functions such as 'Wikipedia[input]' with the corresponding functions and descriptions. The following is the sample prompt: For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
3.1 Data source
Disassemble the task model: Marcoroni-70B uses alpaca's prompt template. The model is fine-tuned with instructions on Llama2 70B. In order to align with the template of the original model, a data set in alpaca format is required. The planner data set format of rewoo is used here, but in the original data set there are only options to call the wiki and its own, so you can apply this template and use the gpt4 interface to create a data set of this style.
3.2 Data set format
Task split model data format: alpaca
### Instruction:<prompt> (without the )### Response:如:### Instruction:For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:get_current_time[input]: Get the current time for now. search_bing[input]: Search the web for content on Bing, and return the top 10 results. Remember, the results may not as good as Wikipedia. If you think the result will not exist in wikipedia, use it. search_wiki[input]: Search the web for content on Wikipedia, and return the top 3 results. If you think the result can exist in wikipedia, use it. search_bilibili[input]: Search for videos on Bilibili, which is a website full of ACG. It can return top 10 search results. save_file[input]: save a file in the target dir which contains the data. query_mysql[input]: Execute the sql in the local mysql database. And return the result. What movies did the director of 'Oppenheim' direct? List the top 10 best.### Response:Step 1: Identify the director of "Oppenheimer" movie.#E1 = search_wiki("Director of Oppenheimer")Step 2: Retrieve information about the director's other works.If the retrieved name exists in Wikipedia, proceed with searching their filmography using search_wiki. Otherwise, try searching through Bing or another source like IMDb.For example, if Christopher Nolan is found as the director of "Oppenheimer":#E2 = search_bing("Filmography of Christopher Nolan")Step 3: Extract the list of films directed by this person from the retrieved information.From the returned results, extract the titles of the top 10 best movies according to critics/audience ratings or personal preference.</prompt>
Function call model data format:
Adopts the format of the trelis data set. The data set is small, with only 55 rows. Its structure is actually similar to the alpaca format. Divided into systemPrompt, userPrompt and assistantResponse, corresponding to alpaca's Instruction, prompt and Response respectively. The following is an example: 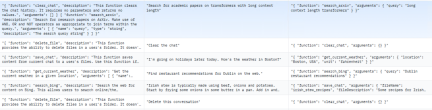
微调过程说明
4.1 微调环境
4.2 微调步骤
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
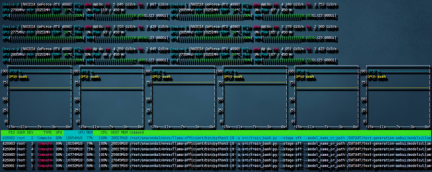
4.3微调完成后的测试效果

Summary
The above is the detailed content of How is AI Agent implemented? 6 photos of 4090 magic modified Llama2: splitting tasks and calling functions with one command. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

