
Home >Technology peripherals >AI >The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document

- 王林forward
- 2023-09-25 16:49:061067browse
Multi-modal large modelThe most complete review is here!
Written by 7 Chinese researchers from Microsoft, is 119 pages long——

It starts fromStarting from the research directions of two types of multi-modal large models, and , which have been improved so far, are still at the forefront, five specific research themes are comprehensively summarized:
- Visual understanding
- Visual generation
- Unified visual model
- LLM-supported multi-modal large model
- Multi-modal agent

The multi-modal basic model has moved from special toPs. This is why the author directly drew an image ofuniversal.
Doraemon at the beginning of the paper.
Who is suitable to read this review(report)?
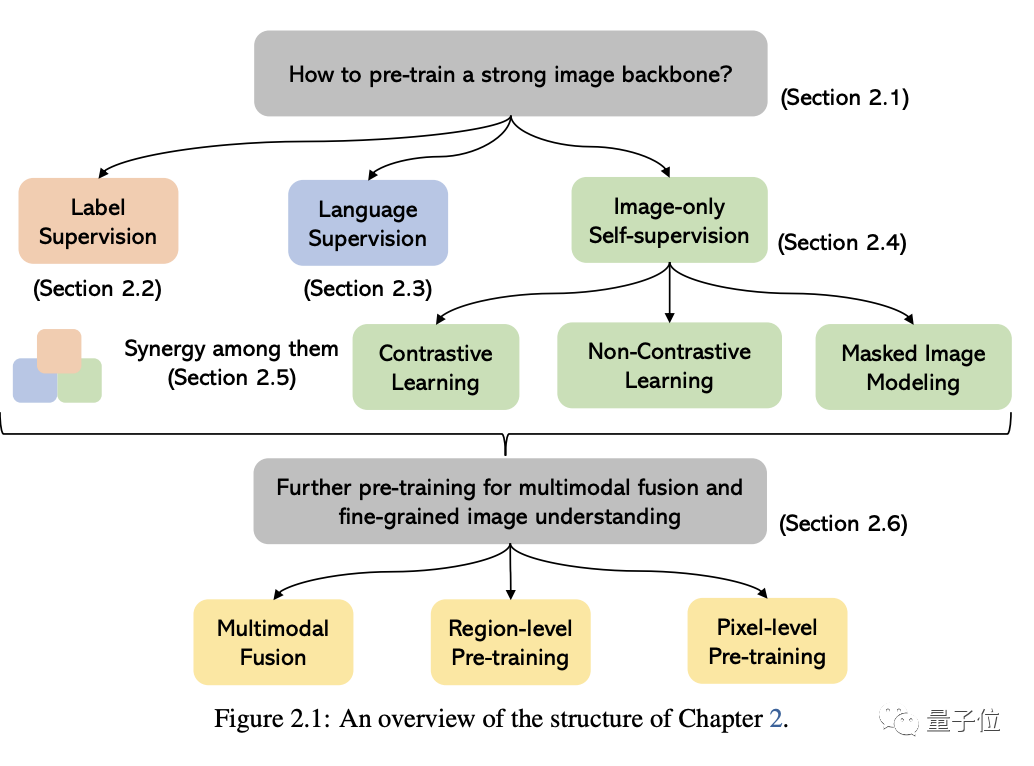
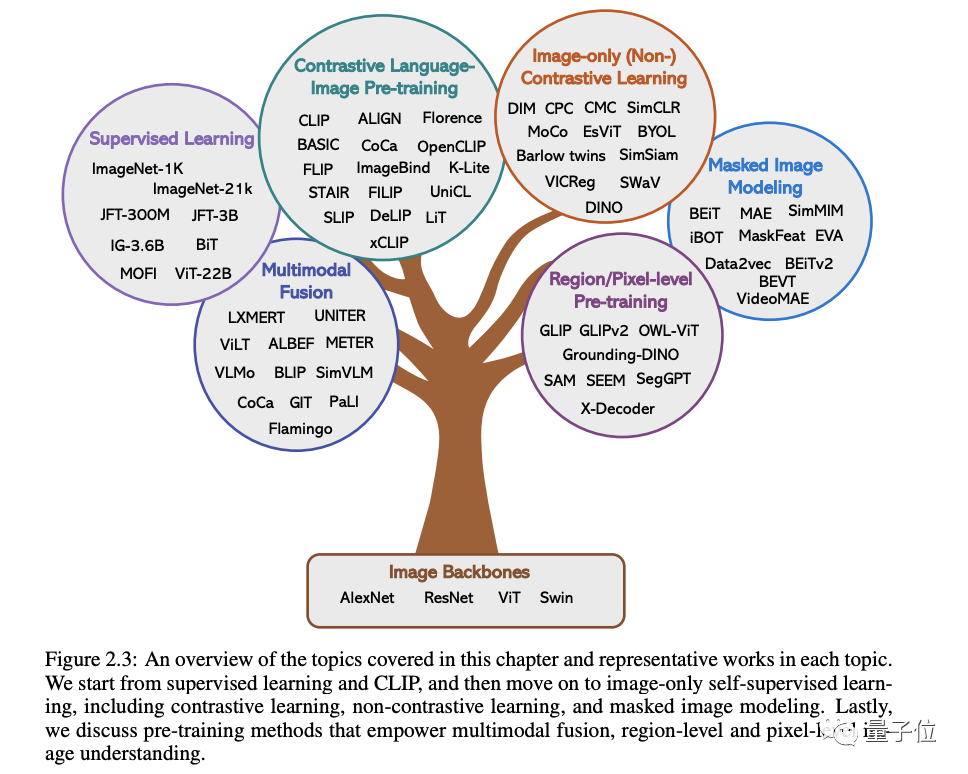
In the original words of Microsoft: As long as you are interested in learning the basic knowledge and latest progress of multi-modal basic models, whether you are a professional researcher or a school student, this content is for you Very suitable for youLet’s take a look~One article to find out the current situation of multi-modal large modelsThe first two of these five specific topics are currently mature. fields, and the last three belong to the cutting-edge fields1. Visual understandingThe core issue in this part is how to pre-train a powerful image understanding backbone. As shown in the figure below, according to the different supervision signals used to train the model, we can divide the methods into three categories:Label supervision, language supervision
(represented by CLIP) and image-only self-supervision.
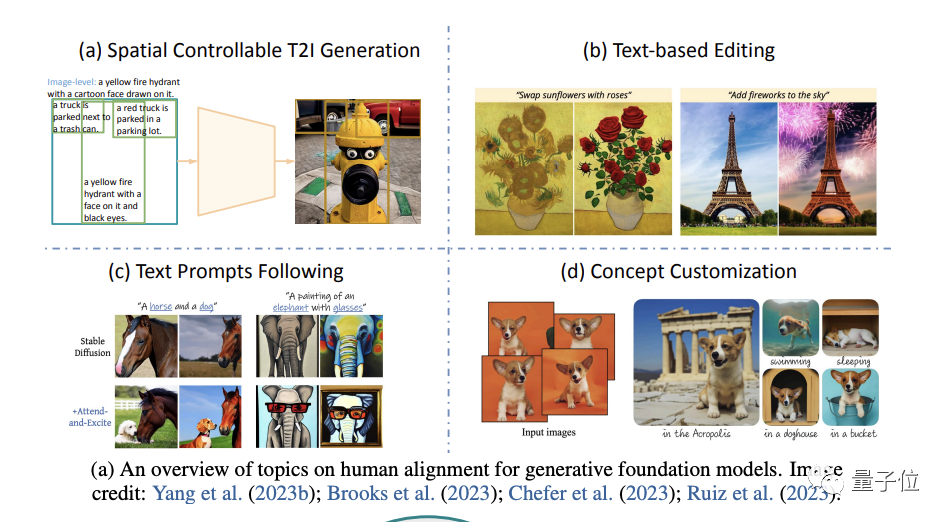
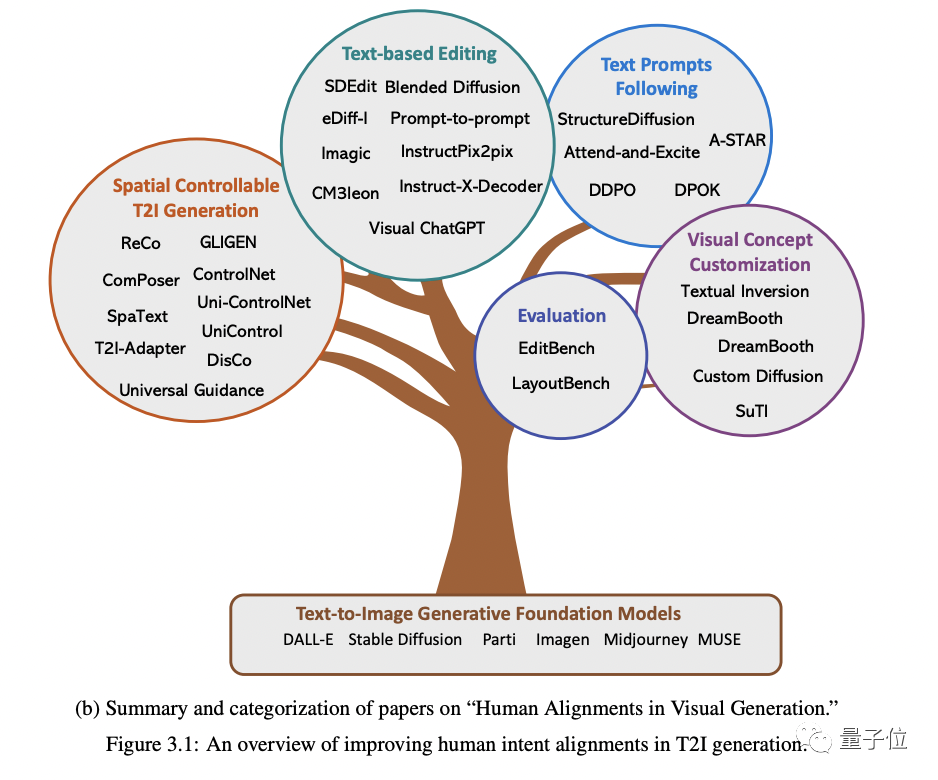
(focusing on image generation).
Specifically, it starts from four aspects: spatial controllable generation, text-based re-editing, better following text prompts and generation concept customization(concept customization) .
For example, the cost of different types of label annotations varies greatly, and the collection cost is much higher than that of text data, which results in the scale of visual data being usually much smaller than that of text corpora.
However, despite the many challenges, the author points out:
The CV field is increasingly interested in developing universal and unified vision systems, and three trends have emerged:
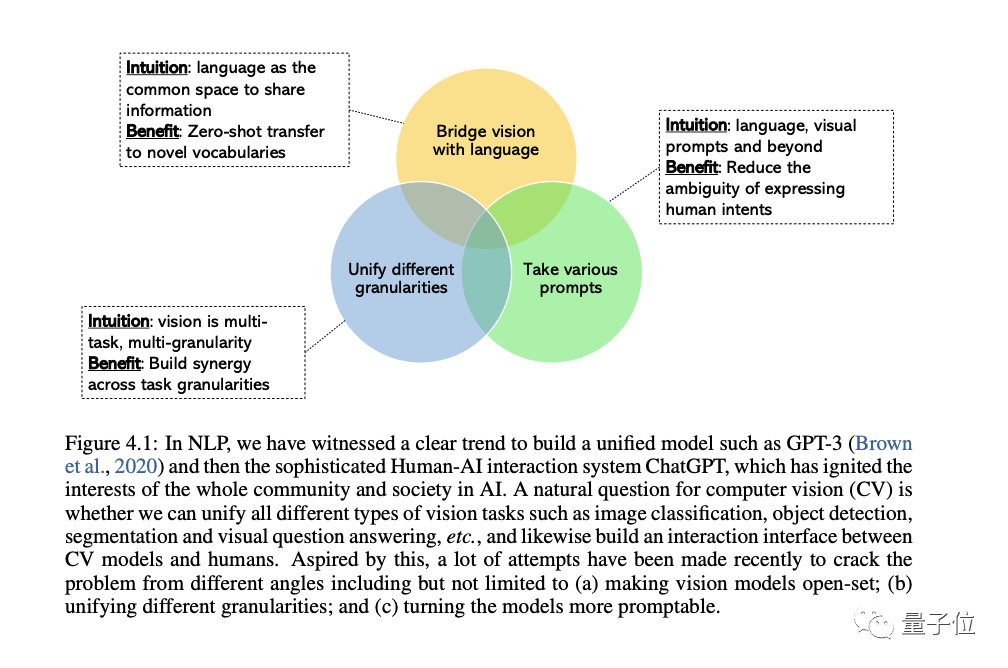
The first is from the closed set (closed-set) to the open set (open-set) , which can better combine text and Visually match.
The most important reason for the transition from specific tasks to general capabilities is that the cost of developing a new model for each new task is too high
The third is from a static model to a promptable model, LLM can Take different languages and contextual cues as input and produce the output the user wants without fine-tuning. The general vision model we want to build should have the same contextual learning capabilities.
4. Multimodal large models supported by LLM
This section comprehensively discusses multimodal large models.
First, we will conduct an in-depth study of the background and representative examples, discuss OpenAI’s multi-modal research progress, and identify existing research gaps in this field.
Next, the author examines in detail the importance of instruction fine-tuning in large language models.
Then, the author discusses the fine-tuning of instructions in multi-modal large models, including principles, significance and applications.
Finally, we will also cover some advanced topics in the field of multimodal models for a deeper understanding, including:
More modalities beyond vision and language, multimodality State-of-the-art context learning, efficient parameter training, and Benchmark.
5. Multimodal agent
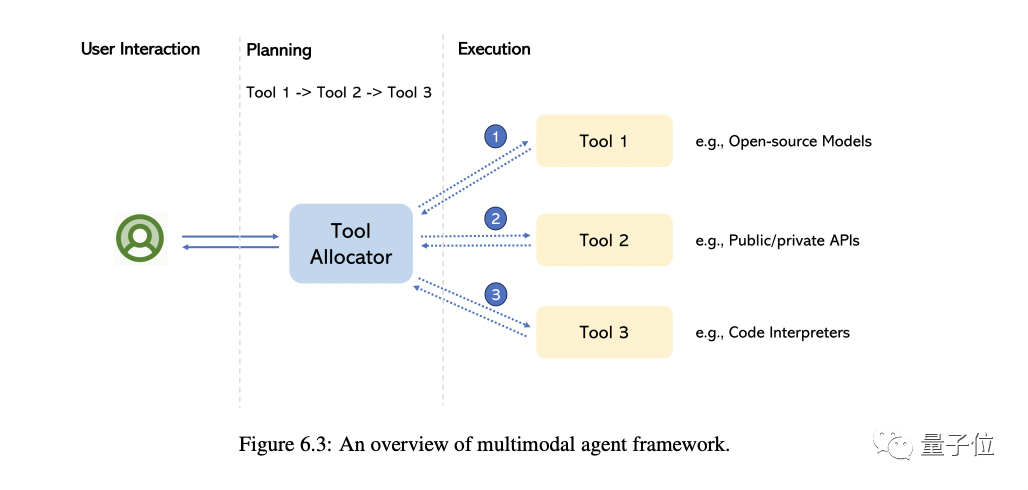
The so-called multimodal agent is a method that connects different multimodal experts with LLM to solve complex multimodal understanding problems.
In this part, the author mainly takes you to review the transformation of this model and summarizes the fundamental differences between this method and the traditional method.
Taking MM-REACT as an example, we will introduce in detail how this method works
We further summarize a comprehensive approach on how to build a multimodal agent, and its role in multimodal Emerging abilities in understanding. At the same time, we also cover how to easily extend this capability, including the latest and greatest LLM and potentially millions of tools
And of course, there are also some advanced topics discussed at the end, including how to improve/ Evaluate multi-modal agents, various applications built with them, etc.
Introduction to the author
There are 7 authors in this report
The initiator and overall person in charge is Chunyuan Li .
He is a principal researcher at Microsoft Redmond and holds a Ph.D. from Duke University. His recent research interests include large-scale pre-training in CV and NLP.
He was responsible for the opening introduction, closing summary, and the writing of the chapter "Multimodal large models trained using LLM". Rewritten content: He was responsible for writing the beginning and end of the article, as well as the chapter on "Multimodal large models trained using LLM"

There are 4 core authors:
- Zhe Gan
Currently, he has joined Apple AI/ML and is responsible for major Scale vision and multimodal base model research. Previously, he was the principal researcher of Microsoft Azure AI. He holds a bachelor's and master's degree from Peking University and a Ph.D. from Duke University.
- Zhengyuan Yang
He is a senior researcher at Microsoft. He graduated from the University of Rochester and received the ACM SIGMM Outstanding Doctoral Award and other honors. He studied as an undergraduate at the University of Science and Technology of China
- Jianwei Yang
Chief researcher of the deep learning group at Microsoft Research Redmond. PhD from Georgia Institute of Technology.
- Linjie Li(female)
Researcher in the Microsoft Cloud & AI Computer Vision Group, graduated with a master's degree from Purdue University.
They were respectively responsible for writing the remaining four thematic chapters.
Summary address: https://arxiv.org/abs/2309.10020
The above is the detailed content of The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document. For more information, please follow other related articles on the PHP Chinese website!