
Home >Technology peripherals >AI >How does DSA overtake NVIDIA GPU in a corner?
How does DSA overtake NVIDIA GPU in a corner?

- 王林forward
- 2023-09-20 18:09:091779browse
You may have heard the following sharp opinions:
1. If you follow NVIDIA’s technical route, you may never be able to catch up with NVIDIA.
2. DSA may have a chance to catch up with NVIDIA, but the current situation is that DSA is on the verge of extinction and there is no hope.
On the other hand, we all know that large models are now at the forefront. , many people in the industry want to make large-model chips, and many people want to invest in large-model chips.
But what is the key to the design of large model chips? Everyone seems to know the importance of large bandwidth and large memory, but how is the chip made different from NVIDIA?
With questions, this article tries to give you some inspiration.
Articles that are purely based on opinions often appear formalistic. We can illustrate this through an architectural example
SambaNova Systems is known as one of the top ten unicorn companies in the United States. In April 2021, the company received US$678 million in Series D investment led by SoftBank, with a valuation reaching US$5 billion, making it a super unicorn company. Previously, SambaNova’s investors included the world’s top venture capital funds such as Google Ventures, Intel Capital, SK and Samsung Catalytic Fund. So, what disruptive things is this super unicorn company that has attracted the favor of the world's top investment institutions doing? By observing their early promotional materials, we can find that SambaNova has chosen a different development path from the AI giant NVIDIA
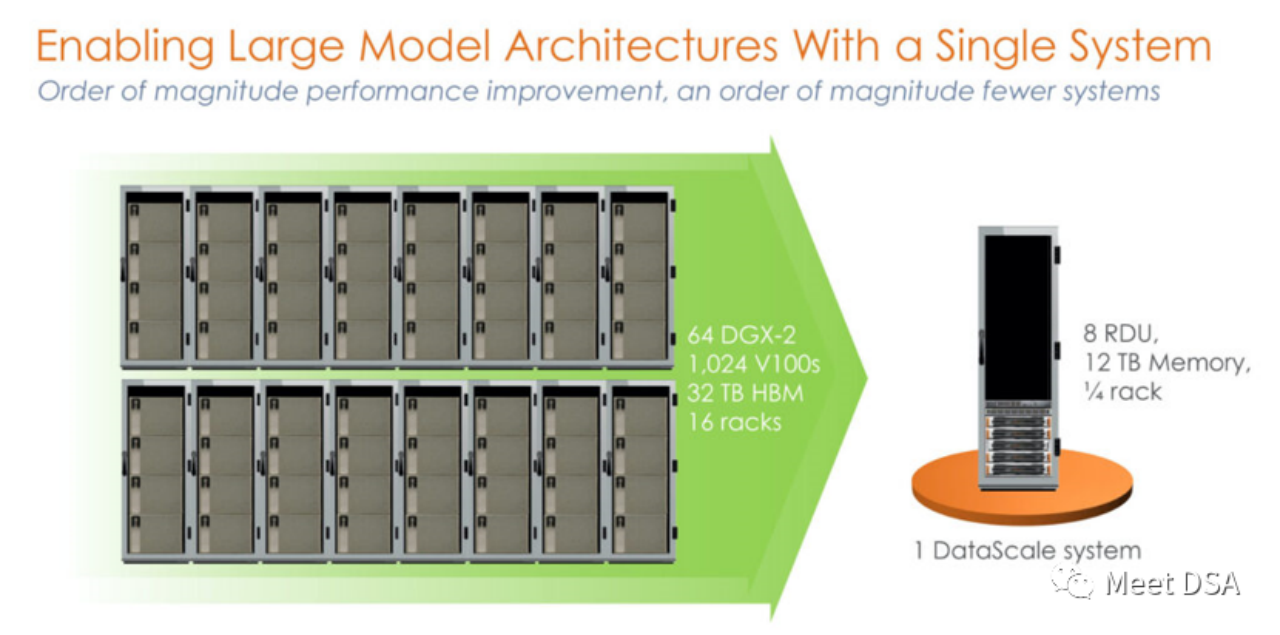
Is it a bit shocking? A 1024 V100 cluster built with unprecedented power on the NVIDIA platform is actually equivalent to a single machine from SambaNova? ! This is the first generation product, a stand-alone 8-card machine based on SN10 RDU.
Some people may say that this comparison is unfair. Doesn’t NVIDIA have DGX A100? Maybe SambaNova itself has realized it, and the second-generation product SN30 has been changed to this:

DGX A100 has a computing power of 5 petaFLOPS, and SambaNova’s second-generation DataScale also has a computing power of 5 petaFLOPS. Memory comparison of 320GB HBM vs 8TB DDR4 (the editor guesses that he may have written the article wrong, it should be 3TB * 8).
The second generation chip is actually the Die-to-Die version of the SN10 RDU. The architectural indicators of SN10 RDU are: 320TFLOPS@BF16, 320M SRAM, 1.5T DDR4. The SN30 RDU is doubled on this basis, as described below:
“This chip had 640 pattern compute units with more than 320 teraflops of compute at BF16 floating point precision and also had 640 pattern memory units with 320 MB of on-chip SRAM and 150 TB/sec of on-chip memory bandwidth. Each SN10 processor was also able to address 1.5 TB of DDR4 auxiliary memory." "With the Cardinal SN30 RDU, the capacity of the RDU is doubled, and the reason it is doubled is that SambaNova designed its architecture to make use of multi-die packaging from the get-go, and in this case SambaNova is doubling up the capacity of its DataScale machines by cramming two new RDU – what we surmise are two tweaked SN10s with microarchitectures changes to better support large foundation models – into a single complex called the SN30. Each socket in a DataScale system now has twice the compute capacity, twice the local memory capacity, and twice the memory bandwidth of the first generations of machines."
Key points extraction:There is only one choice between large bandwidth and large capacity. NVIDIA chose large bandwidth HBM, while SambaNova chose Large capacity DDR4. In terms of performance results, SambaNova wins.
If you switch to DGX H100, even if you switch to low-precision technologies such as FP8, you can only narrow the gap.
“And even if the DGX-H100 offers 3X the performance at 16-bit floating point calculation than the DGX-A100, it will not close the gap with the SambaNova system. However, with lower precision FP8 data, Nvidia might be able to close the performance gap; it is unclear how much precision will be sacrificed by shifting to lower precision data and processing."
If someone can achieve such an effect, wouldn't it be a perfect large-scale Chip solution? And it can also directly face the competition from NVIDIA!
(Maybe you will say that Grace CPU can also be connected to LPDDR, which is helpful for increasing capacity. On the other hand, how does SambaNova view this matter: Grace is just a large memory controller, but it can only Hopper brings 512GB of DRAM, while an SN30 has 3TB of DRAM.
We used to joke that Nvidia's "Grace" Arm CPU was just an overhyped memory controller for a Hopper GPU. In many cases, It's really just a memory controller, and each Hopper GPU in the Grace-Hopper super chip set only has up to 512GB of memory. That's still a lot less than the 3TB of memory the SambaNova offers per socket
History tells us that no matter how prosperous the empire is, it may still have to be careful of that inconspicuous crack!
Xia He, the master of Huawei, recently speculated that a weakness of the NVIDIA empire may lie in the cost per GB from a cost perspective. He suggested crazy stacking of cheap DDR memory for large-scale internal input/output. This may have a revolutionary impact on NVIDIA
(Extension:https://www.php.cn/link/617974172720b96de92525536de581fa)
Mackler, another Zhihu master who studies DSA, gave his opinion. From the perspective of $/GBps (data migration), HBM is more cost-effective, because although LLM has a relatively large demand for memory capacity, it has There is also a huge demand for bandwidth, and training requires a large number of parameters that need to be exchanged in DRAM.
(Extension:https://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc)
From the SambaNova architecture example Look, large-capacity and cheap DDR can solve the problem of LLM, which confirms Xia Core’s judgment! But the huge bandwidth requirement for data migration is also a problem in Mackler's point of view. So how does SambaNova solve it?
You need to further understand the characteristics of the RDU architecture. In fact, it is easy to understand:
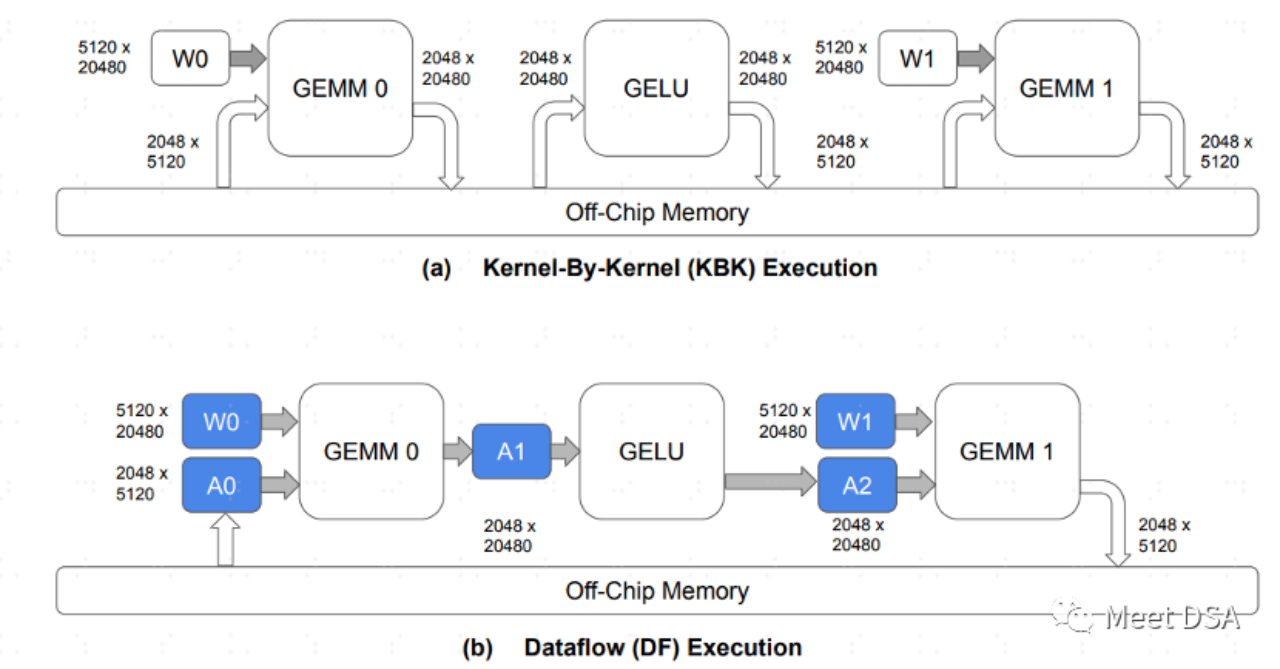
A is the paradigm of data exchange in the traditional GPU architecture. Each operator They all need to exchange data with off-chip DRAM. This back-and-forth exchange occupies a large amount of DDR bandwidth and should be easier to understand. B is what SambaNova's architecture can achieve. During the model calculation process, a large part of the data movement is kept on-chip, and there is no need to go back and forth to DRAM for exchange.
Therefore, If we can achieve the effect like B, if we have to choose between large bandwidth and large capacity, we can safely choose large capacity. This is as the following passage says:
“The question we have is this: What is more important in a hybrid memory architecture supporting foundation models, memory capacity or memory bandwidth? You can't have both based on a single memory technology in any architecture, and even when you have a mix of fast and skinny and slow and fat memories, where Nvidia and SambaNova draw the lines are different."
Facing the powerful NVIDIA , we are not without hope! However, following NVIDIA's GPGPU strategy may not be feasible. It seems that the correct idea for large chips is to use lower-cost DRAM. With the same computing power specifications, the performance can reach more than 6 times that of NVIDIA!
How does SambaNova's RDU/DataFlow architecture achieve the effect of B? Or are there other ways to achieve an effect similar to B? We will share it with you next time. Friends who are interested, please continue to pay attention to our updates
Extended reading materials:
[1]https:/ /sambanova.ai/blog/a-new-state-of-the-art-in-nlp-beyond-gpus/
[2]https://www.nextplatform. com/2022/09/17/sambanova-doubles-up-chips-to-chase-ai-foundation-models/
[3]https://hc33.hotchips.org /assets/program/conference/day2/SambaNova HotChips 2021 Aug 23 v1.pdf
[4]《TRAINING LARGE LANGUAGE MODELS EFFICIENTLY WITH SPARSITY AND DATAFLOW》
[5]https://www.php.cn/link/617974172720b96de92525536de581fa
##The content that needs to be rewritten is: [6]https://www.php .cn/link/a56ee48e5c142c26cf645b2cc23d78fc
The above is the detailed content of How does DSA overtake NVIDIA GPU in a corner?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Xiamen Yuanverse Industry Expo opens to showcase the innovative achievements of Yuanverse
- Taking the 'Exhibition Express', Qingdao Artificial Intelligence Industrial Park explores new ways to attract investment
- Ronglian Cloud was selected into the 2023 Global Generative AI Industry Map
- The demand for AI computing power has increased sharply, and Shanghai Lingang will build a tens-billion-scale computing power industry
- Exploration of the application of Go language in the smart car industry