
 Technology peripheralsAIWith 100,000 US dollars + 26 days, a low-cost LLM with 100 billion parameters was born
Technology peripheralsAIWith 100,000 US dollars + 26 days, a low-cost LLM with 100 billion parameters was bornWith 100,000 US dollars + 26 days, a low-cost LLM with 100 billion parameters was born


Paper: https://arxiv.org/pdf/2309.03852.pdf
Needs to be reprinted The written content is: Model link: https://huggingface.co/CofeAI/FLM-101B
Language is symbolic in nature. There have been some studies using symbols rather than category labels to assess the intelligence level of LLMs. Similarly, the team used a symbolic mapping approach to test the LLM's ability to generalize to unseen contexts.
An important ability of human intelligence is to understand given rules and take corresponding actions. This testing method has been widely used in various levels of testing. Therefore, rule understanding becomes the second test here.
Rewritten content: Pattern mining is an important part of intelligence, which involves induction and deduction. In the history of scientific development, this method plays a crucial role. In addition, test questions in various competitions often require this ability to answer. For these reasons, we chose pattern mining as the third evaluation indicator
The last and very important indicator is the anti-interference ability, which is also one of the core capabilities of intelligence. Studies have pointed out that both language and images are easily disturbed by noise. With this in mind, the team used interference immunity as a final evaluation metric.
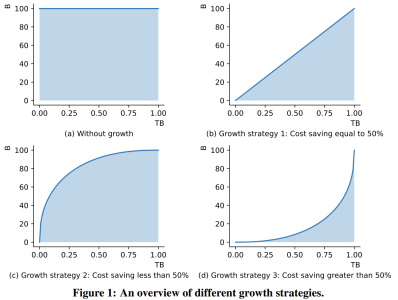
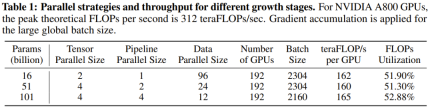
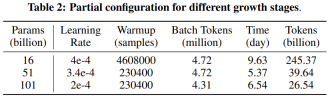
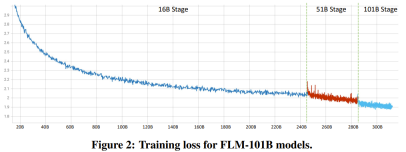
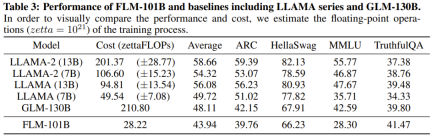
The researchers stated that this is a study using growth strategies to train more than 1,000 people from scratch. LLM research attempt on billion parameters. At the same time, this is also the lowest cost 100 billion parameter model currently, costing only 100,000 US dollars
By improving FreeLM training objectives, potential hyperparameter search methods and function-preserving growth, This study addresses the issue of instability. The researchers believe this method can also help the broader scientific research community.
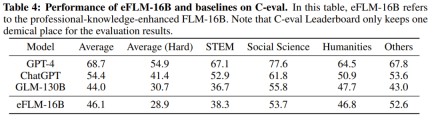
The researchers also conducted experimental comparisons of the new model with previously powerful models, including using knowledge-oriented benchmarks and a newly proposed systematic IQ assessment benchmark. Experimental results show that the FLM-101B model is competitive and robust
The team will release model checkpoints, code, related tools, etc. to promote the research and development of bilingual LLM in Chinese and English with a scale of 100 billion parameters.




The above is the detailed content of With 100,000 US dollars + 26 days, a low-cost LLM with 100 billion parameters was born. For more information, please follow other related articles on the PHP Chinese website!

 Why Sam Altman And Others Are Now Using Vibes As A New Gauge For The Latest Progress In AIMay 06, 2025 am 11:12 AM
Why Sam Altman And Others Are Now Using Vibes As A New Gauge For The Latest Progress In AIMay 06, 2025 am 11:12 AMLet's discuss the rising use of "vibes" as an evaluation metric in the AI field. This analysis is part of my ongoing Forbes column on AI advancements, exploring complex aspects of AI development (see link here). Vibes in AI Assessment Tradi
 Inside The Waymo Factory Building A Robotaxi FutureMay 06, 2025 am 11:11 AM
Inside The Waymo Factory Building A Robotaxi FutureMay 06, 2025 am 11:11 AMWaymo's Arizona Factory: Mass-Producing Self-Driving Jaguars and Beyond Located near Phoenix, Arizona, Waymo operates a state-of-the-art facility producing its fleet of autonomous Jaguar I-PACE electric SUVs. This 239,000-square-foot factory, opened
 Inside S&P Global's Data-Driven Transformation With AI At The CoreMay 06, 2025 am 11:10 AM
Inside S&P Global's Data-Driven Transformation With AI At The CoreMay 06, 2025 am 11:10 AMS&P Global's Chief Digital Solutions Officer, Jigar Kocherlakota, discusses the company's AI journey, strategic acquisitions, and future-focused digital transformation. A Transformative Leadership Role and a Future-Ready Team Kocherlakota's role
 The Rise Of Super-Apps: 4 Steps To Flourish In A Digital EcosystemMay 06, 2025 am 11:09 AM
The Rise Of Super-Apps: 4 Steps To Flourish In A Digital EcosystemMay 06, 2025 am 11:09 AMFrom Apps to Ecosystems: Navigating the Digital Landscape The digital revolution extends far beyond social media and AI. We're witnessing the rise of "everything apps"—comprehensive digital ecosystems integrating all aspects of life. Sam A
 Mastercard And Visa Unleash AI Agents To Shop For YouMay 06, 2025 am 11:08 AM
Mastercard And Visa Unleash AI Agents To Shop For YouMay 06, 2025 am 11:08 AMMastercard's Agent Pay: AI-Powered Payments Revolutionize Commerce While Visa's AI-powered transaction capabilities made headlines, Mastercard has unveiled Agent Pay, a more advanced AI-native payment system built on tokenization, trust, and agentic
 Backing The Bold: Future Ventures' Transformative Innovation PlaybookMay 06, 2025 am 11:07 AM
Backing The Bold: Future Ventures' Transformative Innovation PlaybookMay 06, 2025 am 11:07 AMFuture Ventures Fund IV: A $200M Bet on Novel Technologies Future Ventures recently closed its oversubscribed Fund IV, totaling $200 million. This new fund, managed by Steve Jurvetson, Maryanna Saenko, and Nico Enriquez, represents a significant inv
 As AI Use Soars, Companies Shift From SEO To GEOMay 05, 2025 am 11:09 AM
As AI Use Soars, Companies Shift From SEO To GEOMay 05, 2025 am 11:09 AMWith the explosion of AI applications, enterprises are shifting from traditional search engine optimization (SEO) to generative engine optimization (GEO). Google is leading the shift. Its "AI Overview" feature has served over a billion users, providing full answers before users click on the link. [^2] Other participants are also rapidly rising. ChatGPT, Microsoft Copilot and Perplexity are creating a new “answer engine” category that completely bypasses traditional search results. If your business doesn't show up in these AI-generated answers, potential customers may never find you—even if you rank high in traditional search results. From SEO to GEO – What exactly does this mean? For decades
 Big Bets On Which Of These Pathways Will Push Today's AI To Become Prized AGIMay 05, 2025 am 11:08 AM
Big Bets On Which Of These Pathways Will Push Today's AI To Become Prized AGIMay 05, 2025 am 11:08 AMLet's explore the potential paths to Artificial General Intelligence (AGI). This analysis is part of my ongoing Forbes column on AI advancements, delving into the complexities of achieving AGI and Artificial Superintelligence (ASI). (See related art


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Zend Studio 13.0.1
Powerful PHP integrated development environment

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

