

 Technology peripheralsAIClimbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkour
Technology peripheralsAIClimbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkourClimbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkour

Parkour is an extreme sport. It is a huge challenge for robots, especially four-legged robot dogs, which need to quickly overcome various obstacles in complex environments. Some studies have attempted to use reference animal data or complex rewards, but these approaches generate parkour skills that are either diverse but blind, or vision-based but scene-specific. However, autonomous parkour requires robots to learn vision-based and diverse general skills to perceive various scenarios and respond quickly.
Recently, a video of a robot dog parkour went viral. The robot dog in the video quickly overcame various obstacles in a variety of scenarios. For example, pass through the gap under the iron plate, climb up the wooden box, and then jump to another wooden box. A series of actions are smooth and smooth:


This series of actions shows that the robot dog has mastered the three basic skills of crawling, climbing and jumping



It also has a special skill: it can squeeze through narrow gaps at an angle

If the robot dog fails to overcome the obstacle, it will try a few more times:

This content has been rewritten into Chinese: This robot dog is based on a "parkour" skill learning framework developed for low-cost robots. The framework was jointly proposed by researchers from Shanghai Qizhi Research Institute, Stanford University, ShanghaiTech University, CMU and Tsinghua University, and its research paper has been selected for CoRL 2023 (Oral). This research project has been open source

Paper address: https://arxiv.org/abs/2309.05665
Project address: https://github.com/ZiwenZhuang/parkour
Method introduction
This study launched a new Open source system for learning end-to-end vision-based parkour strategies to learn multiple parkour skills using simple rewards without any reference motion data.
Specifically, this research proposes a reinforcement learning method designed to allow robots to learn to climb high obstacles, jump over large gaps, crawl under low obstacles, and squeeze through Skills such as tight gaps and running, and translate these skills into parkour strategies based on a single vision. At the same time, these skills are transferred to quadruped robots by using an egocentric depth camera
To successfully deploy the parkour strategy proposed in this study on a low-cost robot, only Requires on-board computing (Nvidia Jetson), on-board depth cameras (Intel Realsense), and on-board power, without the need for motion capture, lidar, multiple depth cameras, and lots of computing
In order to train the parkour strategy, this research carried out the following three stages of work:
The first stage: reinforcement learning pre-training, with soft dynamic constraints. This research uses automatic courses to let the robot learn to cross obstacles, and encourages the robot to gradually learn to overcome obstacles
The second stage: reinforcement learning fine-tuning with hard dynamic constraints. The study enforces all dynamic constraints at this stage and uses realistic dynamics to fine-tune the robot's behavior learned in the pre-training stage.
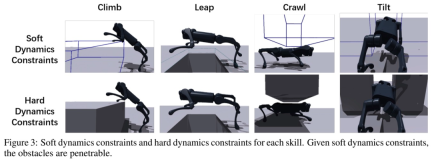
The third stage: distillation. After learning each individual parkour skill, the study uses Dagger to distill them into a vision-based parkour policy (parameterized by an RNN) that can be deployed on a legged robot using only onboard perception and computation. .
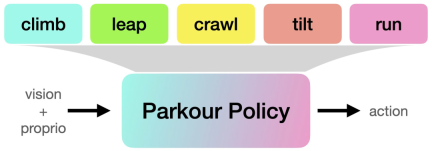
##Experiments and results
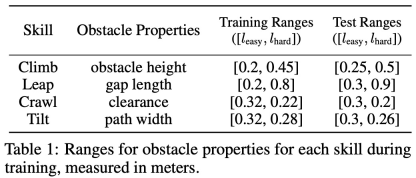
In training, the The study set corresponding obstacle sizes for each skill, as shown in Table 1 below:
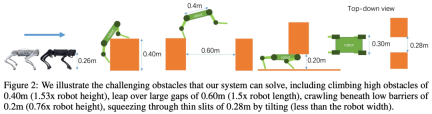
This study conducted a large number of simulations and real-life experiments , the results show that parkour strategies enable low-cost quadruped robots to autonomously select and perform appropriate parkour skills to traverse challenging open-world environments using only onboard computing, onboard visual sensing, and onboard power. , including climbing an obstacle of 0.40m (1.53x robot height), jumping over a large gap of 0.60m (1.5x robot length), crawling under a low obstacle of 0.2m (0.76x robot height), and squeezing through by tilting 0.28m thin gap (less than the width of the robot), and can keep running forward.
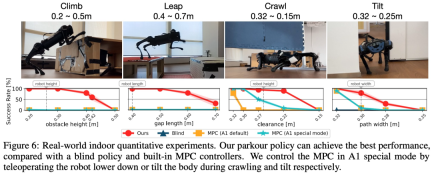
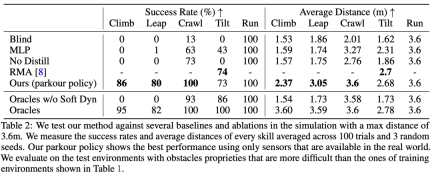
In addition, the study also compared the proposed method with several baseline methods, and Ablation experiments were performed in a simulated environment. The specific results are shown in Table 2:
Interested readers can read the original paper to learn more about the research content
The above is the detailed content of Climbing, jumping, and crossing narrow gaps, open source reinforcement learning strategies allow robot dogs to parkour. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Dreamweaver Mac version
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

