
 Technology peripheralsAISeveral papers were selected for Interspeech 2023, and Huoshan Speech effectively solved many types of practical problems
Technology peripheralsAISeveral papers were selected for Interspeech 2023, and Huoshan Speech effectively solved many types of practical problems
Recently, several papers from the Volcano Voice Team were selected for Interspeech 2023, covering short video speech recognition, cross-language timbre and style, and oral fluency assessment, etc. Innovative breakthroughs in application direction. Interspeech is one of the top conferences in the field of speech research organized by the International Speech Communications Association ISCA. It is also known as the world's largest comprehensive speech signal processing event and has received widespread attention from people in the global language field.

Interspeech2023Event site
Data enhancement based on random sentence concatenation to improve short video speech Recognition (Random Utterance Concatenation Based Data Augmentation for Improving Short-video Speech Recognition)
Generally speaking, end-to-end automatic speech recognition (ASR) One of the limitations of the framework is that its performance may suffer if the lengths of training and test statements do not match. In this paper, the Huoshan Speech team proposes a data enhancement method based on instant random sentence concatenation (RUC) as front-end data enhancement to alleviate the problem of training and test sentence length mismatch in short video ASR tasks.
Specifically, the team found that the following observations played a major role in innovative practice: Typically, the training sentences of short video spontaneous speech are much shorter than the human-transcribed sentences (an average of about 3 seconds), while the test sentences generated from the voice activity detection frontend were much longer (about 10 seconds on average). Therefore, this mismatch may lead to poor performance
The Volcano Speech team stated that for the purpose of empirical work, we used multi-class ASR models from 15 languages. Datasets for these languages range from 1,000 to 30,000 hours. During the model fine-tuning phase, we also added data that was sampled and spliced from multiple pieces of data in real time. Compared with the unenhanced data, this method achieves an average relative word error rate reduction of 5.72% across all languages.

WER for long sentences on the test set passes RUC dropped significantly after training (blue vs. red)
According to experimental observations, the RUC method significantly improved the recognition ability of long sentences, while the performance of short sentences did not decrease. Further analysis found that the proposed data augmentation method can reduce the sensitivity of the ASR model to length normalization changes, which may mean that the ASR model is more robust in diverse environments. To sum up, although the RUC data enhancement method is simple to operate, the effect is significant
Fluency scoring based on phonetic and prosody-aware self-supervision methods(Phonetic and Prosody-aware Self- Supervised Learning Approach for Non-native Fluency Scoring)
One of the important dimensions for evaluating second language learners’ language ability is oral fluency. Fluent pronunciation is mainly characterized by the ability to produce speech easily and normally without many abnormal phenomena such as pauses, hesitations or self-corrections when speaking. Most second language learners typically speak slower and pause more frequently than native speakers. In order to evaluate spoken fluency, the Volcano Speech team proposed a self-supervised modeling method based on speech and prosody correlation
Specifically, in the pre-training stage, the model’s input sequence features (acoustic features, acoustic features, Phoneme id, phoneme duration) are masked, and the masked features are sent to the model. The context-related encoder is used to restore the phoneme id and phoneme duration information of the masked part based on the timing information, so that the model has more powerful speech and Prosodic representation ability. This solution masks and reconstructs the three features of original duration, phoneme and acoustic information in the sequence modeling framework, allowing the machine to automatically learn the speech and duration representation of the context, which is better used for fluency scoring.

#This self-supervised learning method based on speech and prosody outperforms other methods in the field, predicting machine results and human experts on in-house test sets The correlation between scores reached 0.833, which is the same as the correlation between experts and experts. 0.831. On the open source data set, the correlation between machine prediction results and human expert scores reached 0.835, and the performance exceeded some self-supervised methods proposed in the past on this task. In terms of application scenarios, this method can be applied to scenarios that require automatic fluency assessment, such as oral exams and various online oral exercises.
Disentangling the Contribution of Non-native Speech in Automated Pronunciation Assessment A basic idea of non-native speaker pronunciation assessment is to quantify the deviation between learner pronunciation and native speaker pronunciation. Therefore, early acoustic models used for pronunciation evaluation usually only use target language data for training, but some recent studies have begun to use non-native language pronunciation data for training. Native language speech data is incorporated into model training. There is a fundamental difference between the purpose of incorporating non-native speech into L2 ASR and non-native assessment or pronunciation error detection: the goal of the former is to adapt the model to non-native data as much as possible to achieve optimal ASR performance; the latter requires balancing the two perspectives. There are seemingly contradictory requirements, that is, higher recognition accuracy of non-native speech and objective assessment of the pronunciation level of non-native pronunciation. The Volcano Speech team aims to study the contribution of non-native speech in pronunciation assessment from two different perspectives, namely alignment accuracy and assessment performance. To this end, they designed different data combinations and text transcription forms when training the acoustic model, as shown in the figure above The above two The two tables respectively show the performance of different combinations of acoustic models in alignment accuracy and evaluation. Experimental results show that using only non-native language data with manually annotated phoneme sequences during acoustic model training enables alignment of non-native speech and the highest accuracy in pronunciation assessment. Specifically, mixing half native language data and half non-native data (human-annotated phoneme sequences) in training may be slightly worse, but comparable to using only non-native data with human-annotated phoneme sequences. Furthermore, the above mixed case performs better when evaluating pronunciation on native language data. With limited resources, adding 10 hours of non-native language data significantly improved alignment accuracy and evaluation performance regardless of the text transcription type used compared to acoustic model training using only native language data. This research has important guiding significance for data applications in the field of speech evaluation Optimizing frame classification through non-spiking CTC The processor solves the timestamp problem (Improving Frame-level Classifier for Word Timings with Non-peaky CTC in End-to-End Automatic Speech Recognition) Automatic Speech Recognition (ASR) End-to-end systems in the domain have demonstrated performance comparable to hybrid systems. As a by-product of ASR, timestamps are crucial in many applications, especially in scenarios such as subtitle generation and computationally assisted pronunciation training. This paper aims to optimize the frame-level classifier in an end-to-end system to obtain timestamps. . In this regard, the team introduced the use of CTC (connectionist temporal classification) loss to train the frame-level classifier, and introduced label prior information to alleviate the spike phenomenon of CTC. It also combined the output of the Mel filter with the ASR encoder. as input features. In internal Chinese experiments, this method achieved 95.68%/94.18% accuracy in word timestamp 200ms, while the traditional hybrid system was only 93.0%/90.22%. In addition, compared to the previous end-to-end approach, the team achieved an absolute performance improvement of 4.80%/8.02% on the 7 internal languages. The accuracy of word timing is also further improved through a frame-by-frame knowledge distillation approach, although this experiment was only conducted for LibriSpeech. The results of this study demonstrate that timestamp performance in end-to-end speech recognition systems can be effectively optimized by introducing label priors and fusing different levels of features. In internal Chinese experiments, this method has achieved significant improvements compared to hybrid systems and previous end-to-end methods; in addition, the method also shows obvious advantages for multiple languages; through the application of knowledge distillation methods, it has further Improved word timing accuracy. These results are not only of great significance for applications such as subtitle generation and pronunciation training, but also provide useful exploration directions for the development of automatic speech recognition technology. Language-specific Acoustic Boundary Learning for Mandarin-English Code-switching Speech Recognition Rewritten content: As we all know, the main goal of Code Switching (CS) is to promote effective communication between different languages or technology areas. CS requires the use of two or more languages alternately in a sentence. However, merging words or phrases from multiple languages may lead to errors and confusion in speech recognition, which makes code-switched speech recognition (CSSR) a more Challenging mission The usual end-to-end ASR model consists of an encoder, a decoder and an alignment mechanism. Most of the existing end-to-end CSASR models only focus on optimizing the encoder and decoder structures, and rarely discuss whether language-related design of the alignment mechanism is needed. Most of the existing work uses a mixture of Mandarin characters and English subwords as modeling units for mixed Chinese and English scenarios. Mandarin characters usually represent single syllables in Mandarin and have clear acoustic boundaries; while English subwords are obtained without reference to any acoustic knowledge, so their acoustic boundaries may be fuzzy. In order to obtain good acoustic boundaries (alignment) between Mandarin and English in the CSASR system, language-related acoustic boundary learning is very necessary. Therefore, we improved on the CIF model and proposed a language-differentiated acoustic boundary learning method for the CSASR task. For detailed information about the model architecture, please see the figure below The model consists of six components, namely the encoder, the language-differentiated weight estimator (LSWE), the CIF module, Autoregressive (AR) decoder, non-autoregressive (NAR) decoder and language change detection (LCD) module. The calculation process of the encoder, autoregressive decoder and CIF is the same as the original CIF-based ASR method. The language-specific weight estimator is responsible for completing the modeling of language-independent acoustic boundaries. The non-autoregressive (NAR) decoder and The Language Change Detection (LCD) module is designed to assist model training and is no longer retained in the decoding stage. The experimental results show that this method is effective in two test sets of the open source Chinese-English mixed data set SEAME USTR: Based on unified representation and plain text ASR Domain adaptation (Text-only Domain Adaptation using Unified Speech-Text Representation in Transducer) As we all know, domain migration has always been a very important task in ASR, but obtaining paired speech data in the target domain is very It is time-consuming and costly, so many of them use text data related to the target domain to improve the recognition effect. Among traditional methods, TTS will increase the training cycle and the storage cost of related data, while methods such as ILME and Shallow fusion will increase the complexity of inference. Based on this task, the team split the Encoder into Audio Encoder and Shared Encoder based on RNN-T, and introduced Text Encoder to learn representations similar to speech signals; speech and text representations are Through Shared Encoder, RNN-T loss is used for training, which is called USTR (Unified Speech-Text Representation). "For the Text Encoder part, we explored different types of representations, including Character sequence, Phone sequence and Sub-word sequence. The final results showed that the Phone sequence has the best effect. As for the training method, this article explores the method based on the given RNN- Multi-step training method of T model and Single-step training method with completely random initialization." Specifically, the team used the LibriSpeech data set as the Source domain and utilized The annotated text of SPGISpeech is used as plain text for domain migration experiments. Experimental results show that the effect of this method in the target field can be basically the same as that of TTS; the Single-step training effect is higher, and the effect is basically the same as Multi-step; it is also found that the USTR method can further improve the performance of plug-in language models such as ILME. Combined, even if LM uses the same text training corpus. Finally, on the target domain test set, without combining external language models, this method achieved a relative decrease of 43.7% compared to the baseline WER of 23.55% -> 13.25%. Efficient Internal Language Model Estimation Method Based on Knowledge Distillation (Knowledge Distillation Approach for Efficient Internal Language Model Estimation) Although Internal Language Model Estimation (ILME) has proven its effectiveness in end-to-end ASR language model fusion, compared with traditional Shallow fusion, ILME additionally introduces the calculation of internal language models, increasing the cost of inference. . In order to estimate the internal language model, an additional forward calculation is required based on the ASR decoder, or an independent language model (DR-LM) is trained using the ASR training set text based on the Density Ratio method as the internal language. Approximation of the model. The ILME method based on the ASR decoder can usually achieve better performance than the density ratio method because it directly uses ASR parameters for estimation, but its calculation amount depends on the amount of parameters of the ASR decoder; the advantage of the density ratio method is that it can be controlled by The size of DR-LM enables efficient internal language model estimation. For this reason, the Volcano Voice team proposed to use the ILME method based on the ASR decoder as a teacher under the framework of the density ratio method to distill and learn DR-LM, thereby significantly reducing the calculation of ILME while maintaining the performance of ILME. cost. Experimental results show that this method can reduce 95% of the internal language model parameters and is comparable in performance to the ASR-based decoder The ILME method is quite similar. When the ILME method with better performance is used as the teacher, the corresponding student model can also achieve better results. Compared with the traditional density ratio method with a similar amount of calculation, this method has slightly better performance in high-resource scenarios. In low-resource cross-domain migration scenarios, the CER gain can reach 8%, and it is more robust to fusion weights GenerTTS:Pronunciation Disentanglement for Timbre and Style Generalization in Cross-language speech synthesis (GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross- Lingual Text-to-Speech) Generalizable speech synthesis (TTS) across language timbres and styles aims to Synthesize speech with a specific reference timbre or style that has not been trained in the target language. It faces challenges such as the difficulty in separating timbre and pronunciation because it is often difficult to obtain multilingual speech data for a specific speaker; style and pronunciation are mixed together because speech style contains both language-independent and language-dependent parts. To address these challenges, the Volcano Voice team proposed GenerTTS. They carefully designed HuBERT-based information bottlenecks to disentangle the connection between timbre and pronunciation/style. At the same time, they also eliminate language-specific information in the style by minimizing the mutual information between style and language Experimental proof, GenerTTS outperforms baseline systems in terms of stylistic similarity and pronunciation accuracy, and achieves generalizability across language timbres and styles. The Huoshan Voice team has always provided high-quality voice AI technology capabilities and full-stack voice product solutions to ByteDance’s internal business lines, and exported them to the outside world through the Volcano engine. Provide services. Since its establishment in 2017, the team has focused on the research and development of industry-leading AI intelligent voice technology, and constantly explores the efficient combination of AI and business scenarios to achieve greater user value. 



 New SOTA effects were obtained on and
New SOTA effects were obtained on and  , with MERs of 16.29% and 22.81% respectively. In order to further verify the effect of this method on larger data volumes, the team conducted experiments on an internal data set of 9,000 hours, and finally achieved a relative MER gain of 7.9%. It is understood that this paper is also the first work on acoustic boundary learning for language differentiation in the CSASR task.
, with MERs of 16.29% and 22.81% respectively. In order to further verify the effect of this method on larger data volumes, the team conducted experiments on an internal data set of 9,000 hours, and finally achieved a relative MER gain of 7.9%. It is understood that this paper is also the first work on acoustic boundary learning for language differentiation in the CSASR task. 






The above is the detailed content of Several papers were selected for Interspeech 2023, and Huoshan Speech effectively solved many types of practical problems. For more information, please follow other related articles on the PHP Chinese website!

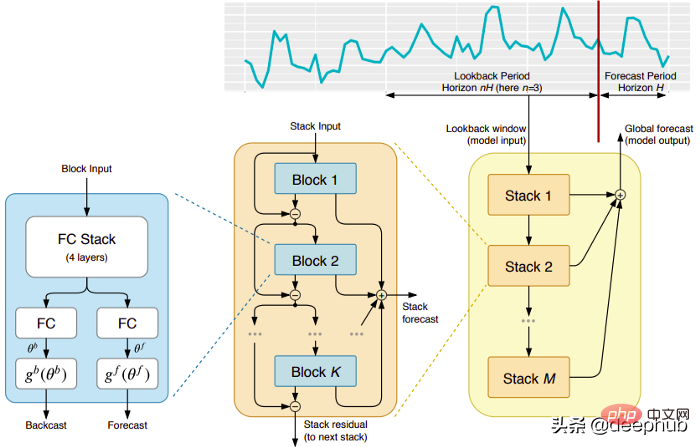 五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PM
五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PMMakridakisM-Competitions系列(分别称为M4和M5)分别在2018年和2020年举办(M6也在今年举办了)。对于那些不了解的人来说,m系列得比赛可以被认为是时间序列生态系统的一种现有状态的总结,为当前得预测的理论和实践提供了经验和客观的证据。2018年M4的结果表明,纯粹的“ML”方法在很大程度上胜过传统的统计方法,这在当时是出乎意料的。在两年后的M5[1]中,最的高分是仅具有“ML”方法。并且所有前50名基本上都是基于ML的(大部分是树型模型)。这场比赛看到了LightG
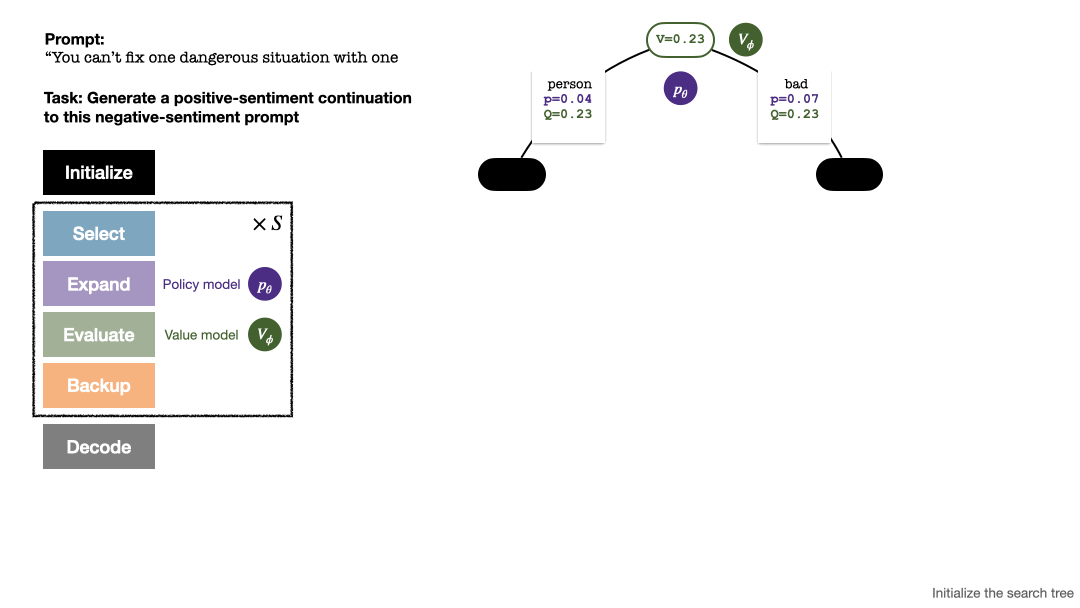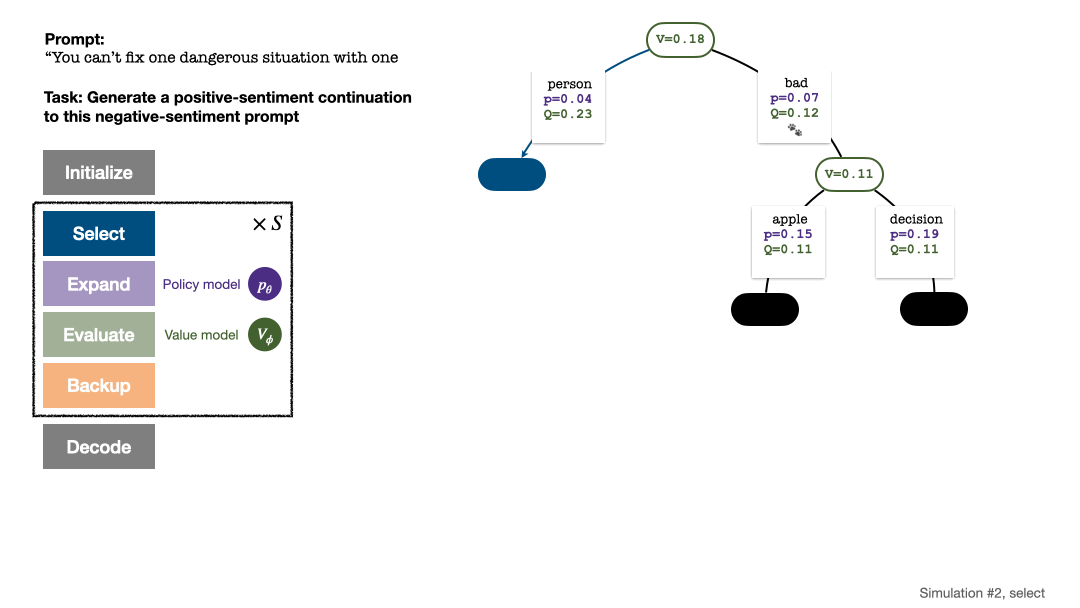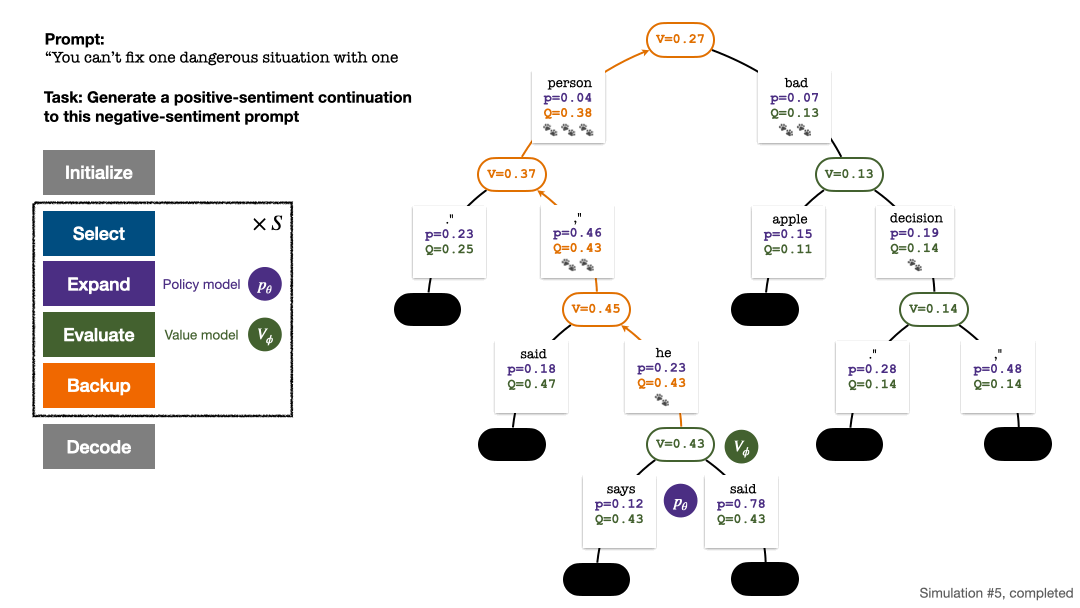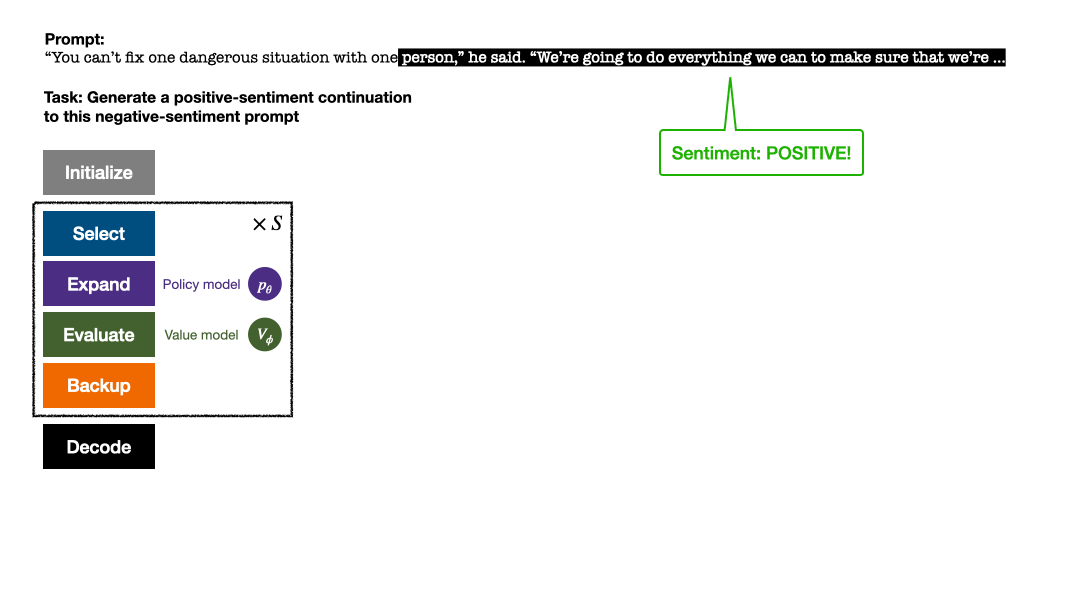 RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM
RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM在一项最新的研究中,来自UW和Meta的研究者提出了一种新的解码算法,将AlphaGo采用的蒙特卡洛树搜索算法(Monte-CarloTreeSearch,MCTS)应用到经过近端策略优化(ProximalPolicyOptimization,PPO)训练的RLHF语言模型上,大幅提高了模型生成文本的质量。PPO-MCTS算法通过探索与评估若干条候选序列,搜索到更优的解码策略。通过PPO-MCTS生成的文本能更好满足任务要求。论文链接:https://arxiv.org/pdf/2309.150
 MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM
MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM编辑|X传统意义上,发现所需特性的分子过程一直是由手动实验、化学家的直觉以及对机制和第一原理的理解推动的。随着化学家越来越多地使用自动化设备和预测合成算法,自主研究设备越来越接近实现。近日,来自MIT的研究人员开发了由集成机器学习工具驱动的闭环自主分子发现平台,以加速具有所需特性的分子的设计。无需手动实验即可探索化学空间并利用已知的化学结构。在两个案例研究中,该平台尝试了3000多个反应,其中1000多个产生了预测的反应产物,提出、合成并表征了303种未报道的染料样分子。该研究以《Autonom
 AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM
AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM作者|陈旭鹏编辑|ScienceAI由于神经系统的缺陷导致的失语会导致严重的生活障碍,它可能会限制人们的职业和社交生活。近年来,深度学习和脑机接口(BCI)技术的飞速发展为开发能够帮助失语者沟通的神经语音假肢提供了可行性。然而,神经信号的语音解码面临挑战。近日,约旦大学VideoLab和FlinkerLab的研究者开发了一个新型的可微分语音合成器,可以利用一个轻型的卷积神经网络将语音编码为一系列可解释的语音参数(例如音高、响度、共振峰频率等),并通过可微分神经网络将这些参数合成为语音。这个合成器
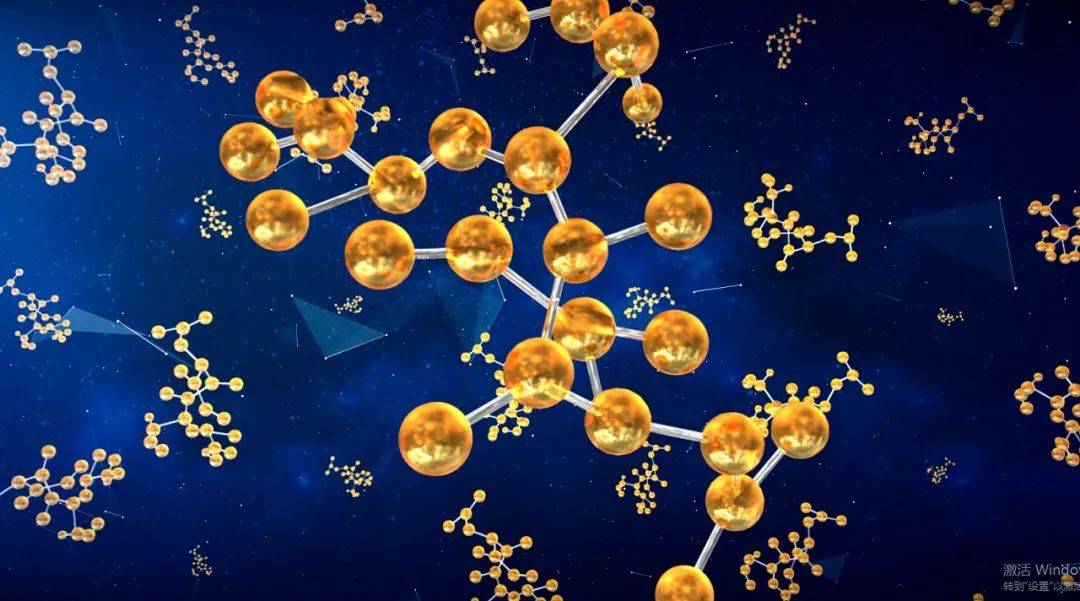
 Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM
Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM昨天,Meta开源专攻代码生成的基础模型CodeLlama,可免费用于研究以及商用目的。CodeLlama系列模型有三个参数版本,参数量分别为7B、13B和34B。并且支持多种编程语言,包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash。Meta提供的CodeLlama版本包括:代码Llama,基础代码模型;代码羊-Python,Python微调版本;代码Llama-Instruct,自然语言指令微调版就其效果来说,CodeLlama的不同版
 手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM
手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM一个普通人用一台手机就能制作电影特效的时代已经来了。最近,一个名叫Simulon的3D技术公司发布了一系列特效视频,视频中的3D机器人与环境无缝融合,而且光影效果非常自然。呈现这些效果的APP也叫Simulon,它能让使用者通过手机摄像头的实时拍摄,直接渲染出CGI(计算机生成图像)特效,就跟打开美颜相机拍摄一样。在具体操作中,你要先上传一个3D模型(比如图中的机器人)。Simulon会将这个模型放置到你拍摄的现实世界中,并使用准确的照明、阴影和反射效果来渲染它们。整个过程不需要相机解算、HDR
 准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM
准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM编辑|紫罗可合成分子的化学空间是非常广阔的。有效地探索这个领域需要依赖计算筛选技术,比如深度学习,以便快速地发现各种有趣的化合物。将分子结构转换为数字表示形式,并开发相应算法生成新的分子结构是进行化学发现的关键。最近,英国格拉斯哥大学的研究团队提出了一种基于电子密度训练的机器学习模型,用于生成主客体binders。这种模型能够以简化分子线性输入规范(SMILES)格式读取数据,准确率高达98%,从而实现对分子在二维空间的全面描述。通过变分自编码器生成主客体系统的电子密度和静电势的三维表示,然后通
 谷歌用大型模型训练机器狗理解模糊指令,激动不已准备去野餐Jan 16, 2024 am 11:24 AM
谷歌用大型模型训练机器狗理解模糊指令,激动不已准备去野餐Jan 16, 2024 am 11:24 AM人类和四足机器人之间简单有效的交互是创造能干的智能助理机器人的途径,其昭示着这样一个未来:技术以超乎我们想象的方式改善我们的生活。对于这样的人类-机器人交互系统,关键是让四足机器人有能力响应自然语言指令。近来大型语言模型(LLM)发展迅速,已经展现出了执行高层规划的潜力。然而,对LLM来说,理解低层指令依然很难,比如关节角度目标或电机扭矩,尤其是对于本身就不稳定、必需高频控制信号的足式机器人。因此,大多数现有工作都会假设已为LLM提供了决定机器人行为的高层API,而这就从根本上限制了系统的表现能


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 Chinese version
Chinese version, very easy to use

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

