

 Technology peripheralsAIThe key step for 'getting on the car' for large models: the world's first language + autonomous driving open source data set is here
Technology peripheralsAIThe key step for 'getting on the car' for large models: the world's first language + autonomous driving open source data set is hereThe key step for 'getting on the car' for large models: the world's first language + autonomous driving open source data set is here

DriveLM is a language-based driver project that contains a data set and a model. With DriveLM, we introduce the inference capabilities of large language models in autonomous driving (AD) to make decisions and ensure explainable planning.
In DriveLM’s dataset, we use human-written reasoning logic as connections to facilitate perception, prediction, and planning (P3). In our model, we propose an AD visual language model with mind mapping capabilities to produce better planning results. Currently, we have released a demo version of the dataset, and the complete dataset and model will be released in the future
Project link: https://github.com/OpenDriveLab/DriveLM The content that needs to be rewritten is: Project link: https://github.com/OpenDriveLab/DriveLM


What is Graph-of -Thoughts in AD?
The most exciting aspect of the dataset is that the question answering (QA) in P3 is connected in a graph-style structure, with QA pairs as each node and the relationships of the objects as edges.
Compared to pure language thinking trees or thinking maps, we prefer multi-modality. In the AD domain, we do this because each stage defines the AD task, from raw sensor input to final control action
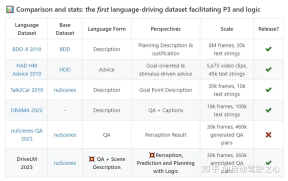
What is included in the DriveLM dataset?
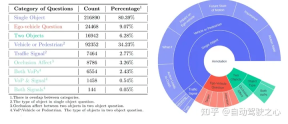
Build our dataset based on the mainstream nuScenes dataset. The core element of DriveLM is frame-based P3 QA. Perception problems require models to recognize objects in a scene. The prediction problem requires the model to predict the future state of important objects in the scene. Planning problems prompt the model to give reasonable planning actions and avoid dangerous actions.
How is the calibration process?
- Keyframe selection. Given all the frames in a clip, the annotator will select the keyframes that need to be annotated. The standard is that these frameworks should involve changes in the self-vehicle's motion state (lane changes, sudden stops, starting after stopping, etc.).
- Key object selection. Given a keyframe, the annotator needs to pick up key objects in six surrounding images. The standard is that these objects should be able to affect the own vehicle (traffic lights, pedestrians crossing the street, other vehicles)
- Q&A Comments. Given these key objects, we automatically generate single or multiple object questions about perception, prediction, and planning. More details can be found in our demo data.
The above is the detailed content of The key step for 'getting on the car' for large models: the world's first language + autonomous driving open source data set is here. For more information, please follow other related articles on the PHP Chinese website!

 undress free porn AI tool websiteMay 13, 2025 am 11:26 AM
undress free porn AI tool websiteMay 13, 2025 am 11:26 AMhttps://undressaitool.ai/ is Powerful mobile app with advanced AI features for adult content. Create AI-generated pornographic images or videos now!
 How to create pornographic images/videos using undressAIMay 13, 2025 am 11:26 AM
How to create pornographic images/videos using undressAIMay 13, 2025 am 11:26 AMTutorial on using undressAI to create pornographic pictures/videos: 1. Open the corresponding tool web link; 2. Click the tool button; 3. Upload the required content for production according to the page prompts; 4. Save and enjoy the results.
 undress AI official website entrance website addressMay 13, 2025 am 11:26 AM
undress AI official website entrance website addressMay 13, 2025 am 11:26 AMThe official address of undress AI is:https://undressaitool.ai/;undressAI is Powerful mobile app with advanced AI features for adult content. Create AI-generated pornographic images or videos now!
 How does undressAI generate pornographic images/videos?May 13, 2025 am 11:26 AM
How does undressAI generate pornographic images/videos?May 13, 2025 am 11:26 AMTutorial on using undressAI to create pornographic pictures/videos: 1. Open the corresponding tool web link; 2. Click the tool button; 3. Upload the required content for production according to the page prompts; 4. Save and enjoy the results.
 undressAI porn AI official website addressMay 13, 2025 am 11:26 AM
undressAI porn AI official website addressMay 13, 2025 am 11:26 AMThe official address of undress AI is:https://undressaitool.ai/;undressAI is Powerful mobile app with advanced AI features for adult content. Create AI-generated pornographic images or videos now!
 UndressAI usage tutorial guide articleMay 13, 2025 am 10:43 AM
UndressAI usage tutorial guide articleMay 13, 2025 am 10:43 AMTutorial on using undressAI to create pornographic pictures/videos: 1. Open the corresponding tool web link; 2. Click the tool button; 3. Upload the required content for production according to the page prompts; 4. Save and enjoy the results.
![[Ghibli-style images with AI] Introducing how to create free images with ChatGPT and copyright](https://img.php.cn/upload/article/001/242/473/174707263295098.jpg?x-oss-process=image/resize,p_40) [Ghibli-style images with AI] Introducing how to create free images with ChatGPT and copyrightMay 13, 2025 am 01:57 AM
[Ghibli-style images with AI] Introducing how to create free images with ChatGPT and copyrightMay 13, 2025 am 01:57 AMThe latest model GPT-4o released by OpenAI not only can generate text, but also has image generation functions, which has attracted widespread attention. The most eye-catching feature is the generation of "Ghibli-style illustrations". Simply upload the photo to ChatGPT and give simple instructions to generate a dreamy image like a work in Studio Ghibli. This article will explain in detail the actual operation process, the effect experience, as well as the errors and copyright issues that need to be paid attention to. For details of the latest model "o3" released by OpenAI, please click here⬇️ Detailed explanation of OpenAI o3 (ChatGPT o3): Features, pricing system and o4-mini introduction Please click here for the English version of Ghibli-style article⬇️ Create Ji with ChatGPT
 Explaining examples of use and implementation of ChatGPT in local governments! Also introduces banned local governmentsMay 13, 2025 am 01:53 AM
Explaining examples of use and implementation of ChatGPT in local governments! Also introduces banned local governmentsMay 13, 2025 am 01:53 AMAs a new communication method, the use and introduction of ChatGPT in local governments is attracting attention. While this trend is progressing in a wide range of areas, some local governments have declined to use ChatGPT. In this article, we will introduce examples of ChatGPT implementation in local governments. We will explore how we are achieving quality and efficiency improvements in local government services through a variety of reform examples, including supporting document creation and dialogue with citizens. Not only local government officials who aim to reduce staff workload and improve convenience for citizens, but also all interested in advanced use cases.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Notepad++7.3.1
Easy-to-use and free code editor

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 Chinese version
Chinese version, very easy to use

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

