

 Technology peripheralsAIProfessor Ma Yi's new work: White-box ViT successfully achieves 'partitioned emergence', is the era of empirical deep learning coming to an end?
Technology peripheralsAIProfessor Ma Yi's new work: White-box ViT successfully achieves 'partitioned emergence', is the era of empirical deep learning coming to an end?Professor Ma Yi's new work: White-box ViT successfully achieves 'partitioned emergence', is the era of empirical deep learning coming to an end?

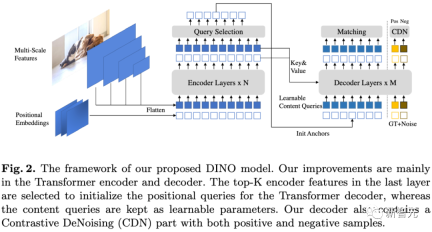
The basic visual model based on Transformer has shown very powerful performance in various downstream tasks, such as segmentation and detection, and models such as DINO have emerged with semantic segmentation attributes after self-supervised training.
It is strange that the visual Transformer model does not have similar emergent capabilities after being trained for supervised classification
Recently, Professor Ma Yi's team studied models based on the Transformer architecture to explore whether the emergent segmentation ability is simply the result of a complex self-supervised learning mechanism, or whether the same performance can be achieved under more general conditions by appropriately designing the model architecture. Emergence

Code link: https://github.com/Ma-Lab-Berkeley/CRATE
Please click the following link to view the paper: https://arxiv.org/abs/2308.16271
After a large number of experiments, the researchers proved that when using the white-box Transformer model CRATE, its design Explicitly model and pursue low-dimensional structure in data distributions to emerge whole- and part-level segmentation properties with minimally supervised training recipes
Through hierarchical fine-grained analysis, we get An important conclusion is drawn: emergent properties strongly confirm the design mathematical function of white-box networks. Based on this result, we proposed a method to design a white-box basic model that is not only high-performance but also fully mathematically interpretable
Professor Ma Yi also said, Research on deep learning will gradually shift from empirical design to theoretical guidance.

The emergent properties of white-box CRATE
DINO’s segmentation-emergent ability refers to the DINO model’s ability to process language tasks At this time, the input sentence can be divided into smaller fragments and each fragment can be processed independently. This ability enables the DINO model to better understand complex sentence structures and semantic information, thereby improving its performance in the field of natural language processing
Representation learning in intelligent systems It aims to convert the world's high-dimensional, multi-modal sensory data (images, language, speech) into a more compact form while retaining its basic low-dimensional structure to achieve efficient recognition (such as classification) and grouping (such as segmentation) and tracking.
The training of deep learning models usually adopts a data-driven approach, by inputting large-scale data and learning in a self-supervised manner
Among the basic vision models, the DINO model shows surprising emergence capabilities. ViTs can recognize explicit semantic segmentation information even without supervised segmentation training. The DINO model with self-supervised Transformer architecture performs well in this regard
Follow-up work has studied how to utilize this segmentation information in the DINO model and perform it in downstream tasks such as segmentation and detection. etc. have achieved state-of-the-art performance, and some work has also proven that the penultimate layer features in ViTs trained with DINO are strongly related to the salience information in the visual input, such as distinguishing foreground, background and object boundaries, thereby improving image segmentation and other task performance.
In order to highlight the segmentation attributes, DINO needs to skillfully combine self-supervised learning, knowledge distillation and weight averaging methods during the training process
It is unclear whether each component introduced in DINO is essential for the emergence of segmentation masks. Although DINO also adopts the ViT architecture as its backbone, in the ordinary supervised ViT model trained on the classification task, and No segmentation emergent behavior was observed.
The emergence of CRATE
Based on the successful case of DINO, researchers want to explore complex self-supervised learning Is the pipeline necessary to obtain emergent properties in Transformer-like visual models?
The researchers believe that a promising way to promote segmentation properties in Transformer models is to design the Transformer model architecture taking into account the input data structure, which also represents representation learning. A combination of classic methods and modern data-driven deep learning frameworks.

Compared with the current mainstream Transformer model, this design method can also be called a white-box Transformer model.
Based on the previous work of Professor Ma Yi’s group, researchers conducted extensive experiments on the CRATE model with a white-box architecture, proving that CRATE’s white-box design is the reason for the emergence of segmentation attributes in self-attention graphs.
What needs to be rephrased is: Qualitative assessment
The researcher uses the [CLS] token-based attention Strive to explain and visualize the model using the graph method and find that the query-key-value matrices in CRATE are all the same
The CRATE model can be observed The self-attention map can correspond to the semantics of the input image. The internal network of the model performs clear semantic segmentation on each image, achieving an effect similar to the DINO model.
Ordinary ViT does not show similar segmentation properties when trained on supervised classification tasks

Based on previous research on visual image learning of block-by-block deep features, researchers conducted principal component analysis (PCA) research on deep token representations of CRATE and ViT models

It can be found that CRATE can still capture the boundaries of objects in the image without segmentation supervision training.
Moreover, the principal components also indicate the feature alignment of similar parts between the token and the object, such as the red channel corresponding to the horse’s leg
The degree of PCA visualization structure of the supervised ViT model is quite low.
Quantitative Evaluation
The researchers used existing segmentations to evaluate the CRATE emergent segmentation properties. and object detection technology
As can be seen from the self-attention map, CRATE explicitly captures object-level semantics with clear boundaries. In order to quantitatively measure the quality of segmentation, the researchers used self-attention to The attention map generates a segmentation mask and compares the standard mIoU (mean intersection-over-union ratio) with the real mask.

It can be seen from the experimental results that CRATE is significantly better than ViT in terms of visual and mIOU scores, which shows that the internal representation of CRATE is useful for generating segmentation masks. Mask tasks more efficiently
Object detection and fine-grained segmentation
To further validate and evaluate the rich semantics captured by CRATE Information, the researchers adopted MaskCut, an efficient object detection and segmentation method, to obtain an automated evaluation model without manual annotation, and can extract more fine-grained segmentation from images based on the token representation learned by CRATE.


As you can see in the segmentation results on COCO val2017, there is an internal representation of CRATE in the detection and The segmentation index is better than that of supervised ViT. MaskCut with supervised ViT features cannot even produce segmentation masks at all in some cases.
White box analysis of CRATE’s segmentation capabilities
The role of depth in CRATE
The design of each layer of CRATE follows the same conceptual purpose: to optimize sparse rate reduction and transform token distribution into a compact and structured form. After rewriting: The design of each level of CRATE follows the same philosophy: optimize the reduction of sparse rate, and transform the distribution of tokens into a compact and structured form
Assume CRATE The emergence of semantic segmentation capabilities is similar to "representing clusters of tokens belonging to similar semantic categories in Z". It is expected that CRATE's segmentation performance can improve with increasing depth.
To test this, the researchers used the MaskCut pipeline to quantitatively evaluate segmentation performance across internal representations across different layers; and also applied PCA visualization to understand how segmentation emerges with depth. .
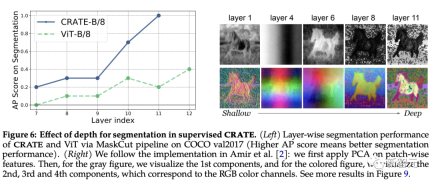
It can be observed from the experimental results that the segmentation score improves when using representations from deeper layers, which is very consistent with CRATE’s incremental optimization design.
In contrast, even though the performance of ViT-B/8 improves slightly in later layers, its segmentation scores are significantly lower than CRATE. The PCA results show that deep extraction from CRATE The representation will gradually pay more attention to foreground objects and be able to capture texture-level details.
melting experiment in CRATE
Attention block (MSSA) in CRATE and The MLP block (ISTA) is different from the attention block in ViT
To study the impact of each component on the emergent segmentation properties of CRATE, the researchers selected three CRATE variants: CRATE, CRATE-MHSA, CRATE-MLP. These variants represent the attention block (MHSA) and the MLP block in ViT respectively
The researchers applied the same pre-training settings on the ImageNet-21k dataset and then applied coarse segmentation evaluation and mask segmentation evaluation to quantitatively compare the performance of different models.
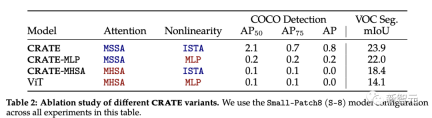
According to experimental results, CRATE significantly outperforms other model architectures in all tasks. It is worth noting that although the architectural difference between MHSA and MSSA is small, simply replacing MHSA in ViT with MSSA in CRATE can significantly improve ViT's coarse segmentation performance (i.e. VOC Seg). Performance. This further proves the effectiveness of white-box design
The content that needs to be rewritten is: pay attention to the identification of the semantic attributes of the header
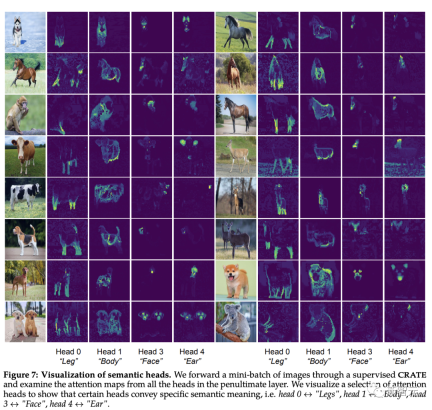
[CLS] The self-attention map between the token and the image block token can see a clear segmentation mask. According to intuition, each attention head should be able to capture some features of the data.
The researchers first input the image into the CRATE model, and then had a human inspect and select four attention heads that seemed to have semantic meaning; then they used these attention heads on other input images. Self-attention map visualization on the head.
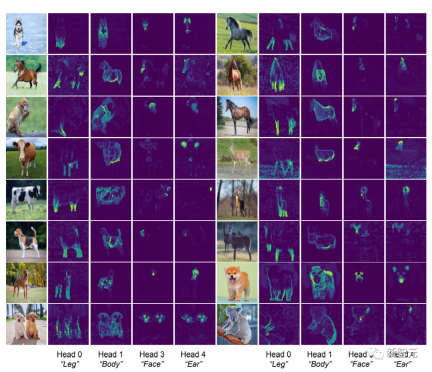
Observation can be found that each attention head can capture different parts of the object, and even different semantics. For example, the attention head in the first column can capture the legs of different animals, while the attention head in the last column can capture the ears and head
Since it is deformable This ability to parse visual input into part-whole hierarchies has been a goal of recognition architecture since the release of deformable part models and capsule networks, and the CRATE model of white-box design also has this ability.
The above is the detailed content of Professor Ma Yi's new work: White-box ViT successfully achieves 'partitioned emergence', is the era of empirical deep learning coming to an end?. For more information, please follow other related articles on the PHP Chinese website!

 From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AM
From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AMThe legal tech revolution is gaining momentum, pushing legal professionals to actively embrace AI solutions. Passive resistance is no longer a viable option for those aiming to stay competitive. Why is Technology Adoption Crucial? Legal professional
 This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AM
This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AMMany assume interactions with AI are anonymous, a stark contrast to human communication. However, AI actively profiles users during every chat. Every prompt, every word, is analyzed and categorized. Let's explore this critical aspect of the AI revo
 7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AM
7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AMA successful artificial intelligence strategy cannot be separated from strong corporate culture support. As Peter Drucker said, business operations depend on people, and so does the success of artificial intelligence. For organizations that actively embrace artificial intelligence, building a corporate culture that adapts to AI is crucial, and it even determines the success or failure of AI strategies. West Monroe recently released a practical guide to building a thriving AI-friendly corporate culture, and here are some key points: 1. Clarify the success model of AI: First of all, we must have a clear vision of how AI can empower business. An ideal AI operation culture can achieve a natural integration of work processes between humans and AI systems. AI is good at certain tasks, while humans are good at creativity and judgment
 Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AM
Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AMMeta upgrades AI assistant application, and the era of wearable AI is coming! The app, designed to compete with ChatGPT, offers standard AI features such as text, voice interaction, image generation and web search, but has now added geolocation capabilities for the first time. This means that Meta AI knows where you are and what you are viewing when answering your question. It uses your interests, location, profile and activity information to provide the latest situational information that was not possible before. The app also supports real-time translation, which completely changed the AI experience on Ray-Ban glasses and greatly improved its usefulness. The imposition of tariffs on foreign films is a naked exercise of power over the media and culture. If implemented, this will accelerate toward AI and virtual production
 Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AM
Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AMArtificial intelligence is revolutionizing the field of cybercrime, which forces us to learn new defensive skills. Cyber criminals are increasingly using powerful artificial intelligence technologies such as deep forgery and intelligent cyberattacks to fraud and destruction at an unprecedented scale. It is reported that 87% of global businesses have been targeted for AI cybercrime over the past year. So, how can we avoid becoming victims of this wave of smart crimes? Let’s explore how to identify risks and take protective measures at the individual and organizational level. How cybercriminals use artificial intelligence As technology advances, criminals are constantly looking for new ways to attack individuals, businesses and governments. The widespread use of artificial intelligence may be the latest aspect, but its potential harm is unprecedented. In particular, artificial intelligence
 A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AM
A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AMThe intricate relationship between artificial intelligence (AI) and human intelligence (NI) is best understood as a feedback loop. Humans create AI, training it on data generated by human activity to enhance or replicate human capabilities. This AI
 AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AM
AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AMAnthropic's recent statement, highlighting the lack of understanding surrounding cutting-edge AI models, has sparked a heated debate among experts. Is this opacity a genuine technological crisis, or simply a temporary hurdle on the path to more soph
 Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AM
Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AMIndia is a diverse country with a rich tapestry of languages, making seamless communication across regions a persistent challenge. However, Sarvam’s Bulbul-V2 is helping to bridge this gap with its advanced text-to-speech (TTS) t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver Mac version
Visual web development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SublimeText3 Mac version
God-level code editing software (SublimeText3)

