
Home >Technology peripherals >AI >Implement search enhancement generation based on Langchain, ChromaDB and GPT 3.5
Implement search enhancement generation based on Langchain, ChromaDB and GPT 3.5

- 王林forward
- 2023-09-14 14:21:111817browse
Translator | Zhu Xianzhong
## Chonglou | Reviewer
Abstract:In this blog, we will learn about a tip# called retrieval augmented generation ## engineering technology, and will be based on a combination of Langchain, ChromaDB and GPT 3.5 to implement this technology. Motivation
With converter-basedbig datamodels like GPT-3 With the emergence of natural language processing (NLP), major breakthroughs have been made in the field of natural language processing (NLP). These language models are capable of generating human-like text and havea variety of applications such as chatbots, content generation and translationetc. However, when it comes to enterpriseapplication scenarios of specialized and customer-specific information, traditional language models maynot satisfy Require. On the other hand, fine-tuning these models using new corpora can be expensive and time-consuming. To address this challenge, we can use a technique called Retrieval Augmented Generation (RAG: Retrieval Augmented Generation).
In this blog we will explore 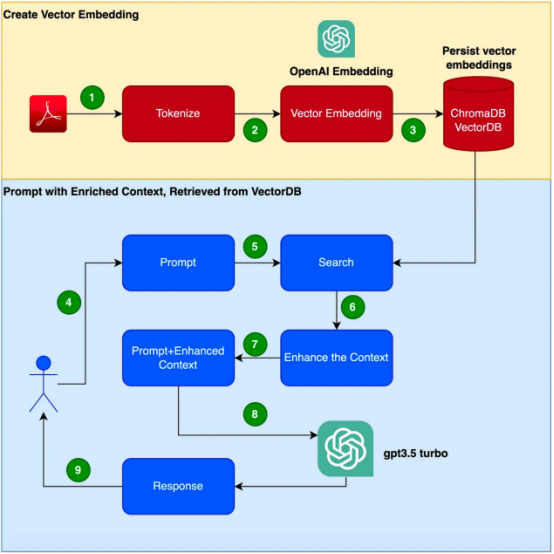
retrieval Enhanced Generation(RAG)How the technology works,and by a Practicalbattlingexamples to provetheeffectiveness of this technology. It should be noted that this example will use GPT-3.5 Turbo as an additional corpus to respond to the product manual. Imagine you are tasked with developing a chatbot that
can respond to questions about a specific product Inquire. The product has its own unique user manual, specifically for enterprise products. Traditional language models, such as GPT-3, are often trained on general data and may not understand this specific product.On the other hand, Using a new corpus to fine-tune the model seems to be a solution; however, this approachwill bring Considerable cost and resource requirements. Introduction to Retrieval Augmented Generation (RAG)Retrieval Augmented Generation (RAG) provides a more efficient way to solve problems in a specific domain Questions that generate appropriate contextual responses. Rather than using a new corpus to fine-tune the entire language model, RAG uses the power of retrieval to access relevant information on demand. By combining retrieval mechanisms with language models, RAG leverages external context to enhance responses. This external context can be provided as a vector embedding
##created
## given below #In this article, requiressteps to be followed when applying.
- Read the Clarett User Manual (PDFFormat) and proceed with a chunk_size of 1000 tokens Tokenization.
- #Create vector embeddings of these tokens. We will use the OpenAIEmbeddings library to create vector embeddings.
- Store the vector embedding locally. We will use simple ChromaDB as our VectorDB. We can use Pinecone or any other higher availability production grade vector database VectorDB. # User posts a prompt with a query/question.
- This will search and retrieve from
- VectorDB for convenience ##Get more contextual data from VectorDB. This contextual data will now be used with the prompt
- content. Context-enhanced prompts
- ,This is often referred to as context enrichment. prompt
- information, along with query/question and the context of this enhancement, is now passed to the Large Language Model LLM. At this point,
- LLM responds based on this context. It should be noted that in this example,
we will use the Focusrite Clarett User Manual as an additional corpus. Focusrite Clarett is a simple USB audio interface for recording and playing audio. You can download and use it from the link https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett 8Pre USB User Guide V2 English - EN.pdf manual. Practical drillSet up a virtual environment
Let us set up a virtual environment to
##Our implementation
cases are encapsulated to avoid any versions/libraries/dependencies# that may appear in the systemSexConflict. Now, we execute the following command to create a new Python virtual environment :pip install virtualenvpython3 -m venv ./venvsource venv/bin/activate
Creating an OpenAI keyNext, we will need an OpenAI key to access GPT. Let's create an OpenAI key. You can create an OpenAIKey for free by registering for OpenAI at
After registering, log in and select the API option as shown in the screenshot (For time reasons, when you open the Screen design
maywithmycurrentshooting screen Screenshot has changed). Then, go to your account settings and select "View API Keys":

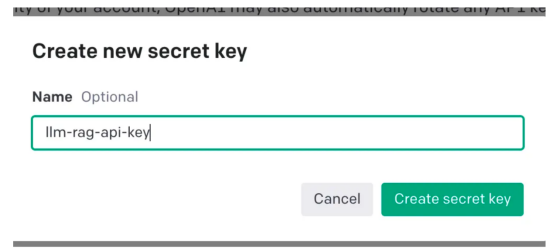
##Then, select "Create new secret key)
", you will see a pop-up window as shown below. You need to
You need to
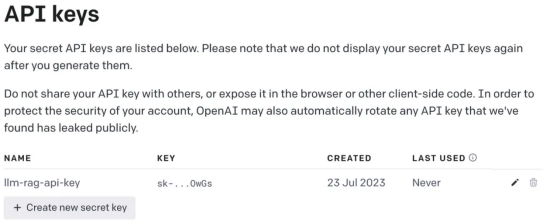
provide a name, which will generate a key. This operation will generate a unique key that you should copy to clipboard Board and store in a safe place.
Next, let us write Python code to implement all the things shown in the flowchart above step. Install dependent libraries
 First,
First,
Let us install the various dependencies we need. We will use the following libraries:
- Lanchain:一个开发LLM应用程序的框架。
- ChromaDB:这是用于持久化向量嵌入的VectorDB。
- unstructured:用于预处理Word/PDF文档。
- Tiktoken:Tokenizer框架
- pypdf:阅读和处理PDF文档的框架
- openai:访问openai的框架
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。
export OPENAI_API_KEY=<openai-key></openai-key>
接下来,让我们开始编程。
从用户手册PDF创建向量嵌入并将其存储在ChromaDB中
在下面的代码中,我们会引入所有需要使用的依赖库和函数
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
在下面的代码中,阅读PDF,将文档标记化并拆分为标记。
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData, embeddings, collection_name=collection_name, persist_directory=persist_directory )vectDB.persist()
执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。
现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm( OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。
chat_history = []qry = ""while qry != 'done': qry = input('Question: ') if qry != exit: response = chatQA({"question": qry, "chat_history": chat_history}) print(response["answer"])
这是输出的屏幕截图。

小结
正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。
译者介绍
朱先忠是51CTO社区的编辑,也是51CTO专家博客和讲师。他还是潍坊一所高校的计算机教师,是自由编程界的老兵
原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar
The above is the detailed content of Implement search enhancement generation based on Langchain, ChromaDB and GPT 3.5. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- What science is natural language processing?
- How to use Go language for natural language processing development?
- Use Python programming to implement Baidu natural language processing interface docking to help you develop intelligent processing programs
- Natural language processing techniques in C++
- How to do human-computer interaction and natural language processing in C++?