
Home >Technology peripherals >AI >Apple core runs large models without reducing calculation accuracy. Speculative sampling is crazy. GPT-4 is also used.
Apple core runs large models without reducing calculation accuracy. Speculative sampling is crazy. GPT-4 is also used.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-09-08 11:25:08903browse
As soon as Code Llama came out, everyone expected someone to continue quantitative slimming. Fortunately, it can be run locally.
It was indeed Georgi Gerganov, the author of llama.cpp, who took action, but this time he did not follow the routine. :
Without quantization, Code LLama’s 34B code can run on Apple computers and infer inference speeds exceeding 20 tokens per second, even with FP16 precision
 Picture
Picture
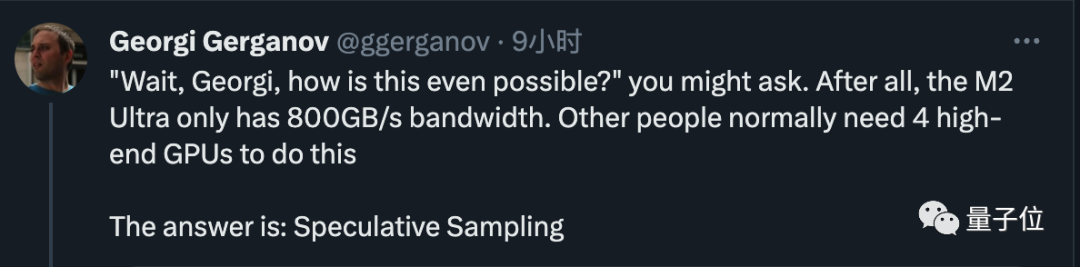
Now just using M2 Ultra with 800GB/s bandwidth, you can complete tasks that originally required 4 high-end GPUs, and write code very quickly
The old man then revealed the secret. The answer is very simple, which is to perform speculative sampling/decoding.
 Picture
Picture
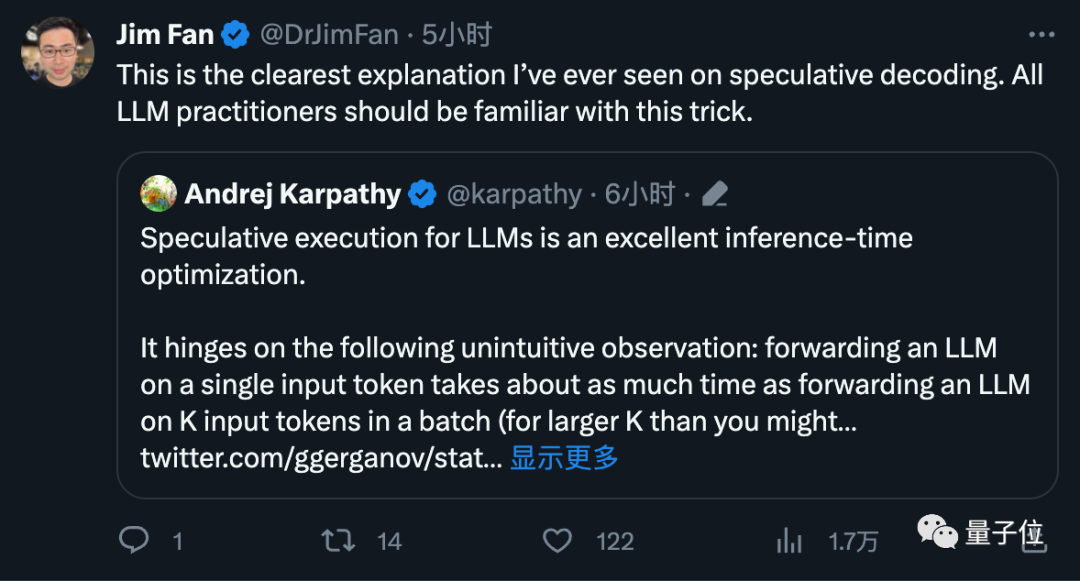
is triggered Attention of many industry giants
Andrej Karpathy, a founding member of OpenAI, commented that this is an excellent inference time optimization and gave more technical explanations.
Fan Linxi, a NVIDIA scientist, also believes that this is a technique that everyone working on large models should be familiar with
 Picture
Picture
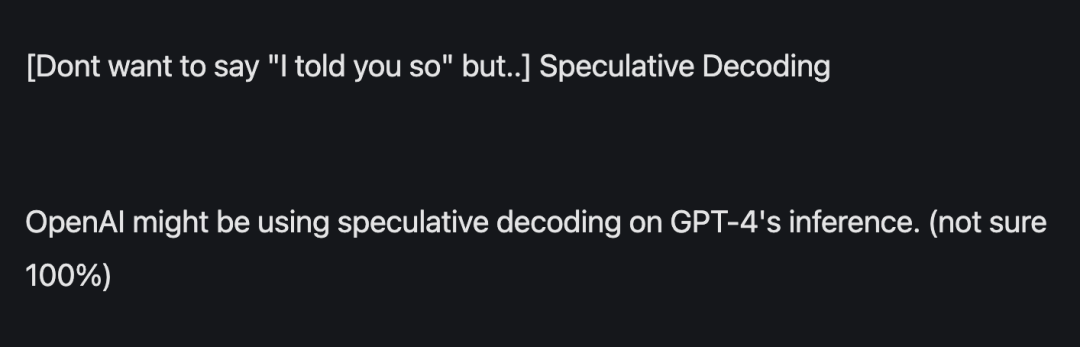
GPT-4 is also using the method
People using speculative sampling are not limited to people running large models locally. Super giants such as Google and OpenAI are also using this technology
According to previous According to the leaked information, GPT-4 used this method to reduce the cost of inference, otherwise it would not be able to afford to burn such money.
 Picture
Picture
The latest news indicates that Gemini, the next generation large model jointly developed by Google DeepMind, is likely to be used as well.
Although the specific method of OpenAI is confidential, the Google team has released a related paper, and the paper was selected for the ICML 2023 oral report
 Picture
Picture
The method is very simple. First train a small model that is similar to the large model and cheaper. Let the small model generate K tokens first, and then let the large model do the judging.
The large model can directly use the accepted parts, and modify the unaccepted parts by the large model
In the original study, the T5-XXL model was used for demonstration, and the generation was maintained While the results remain unchanged, 2-3 times the inference acceleration is obtained
 Picture
Picture
Andjrey Karpathy likens this method to "let the small model first prepare a draft".
He explained that the key to the effectiveness of this method is that when a large model is input into a token and a batch of tokens, the time required to predict the next token is almost the same
Each token Depends on the previous token, so it is impossible to sample multiple tokens at the same time under normal circumstances
Although the small model has poor capabilities, many parts are very simple when actually generating a sentence, and the small model can also It's competent, just let the big model work on the difficult parts.
The original paper points out that existing mature models can be directly accelerated without changing their structure or retraining
This point will not reduce the accuracy, which is also given in the appendix of the paper. Mathematical Argument.
 Picture
Picture
Now that we understand the principle, let’s look at Georgi Gerganov’s specific settings this time.
He uses a 4-bit quantized 7B model as a "draft" model, which can generate approximately 80 tokens per second.
When the FP16 precision 34B model is used alone, it can only generate 10 tokens per second
After using the speculative sampling method, we obtained a 2x acceleration effect, which is the same as in the original paper The data is consistent
 Picture
Picture
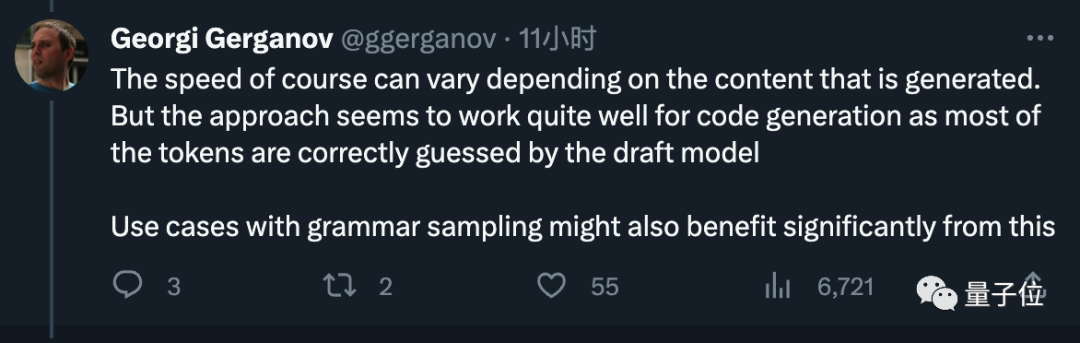
He additionally stated that the speed may vary depending on the content generated, but it is very effective in code generation, The draft model can guess most tokens correctly.
 Picture
Picture
Finally, he also suggested that Meta directly include the small draft model when releasing models in the future, which was well received by everyone.
 Picture
Picture
The author has started a business
Georgi Gerganov is the author. He transplanted the first generation of LlaMA to C in March this year superior. His open source project llama.cpp has received nearly 40,000 stars
 Picture
Picture
He initially only considered this as a hobby, but due to The response was overwhelming, and in June he announced a new company, ggml.ai, dedicated to running AI on edge devices. The company’s main product is the C language machine learning framework behind llama.cpp
Picture In the early days of the business, we successfully obtained the support from the former chief executive of GitHub Executive Nat Friedman and Y Combinator partner Daniel Gross's pre-seed investment
In the early days of the business, we successfully obtained the support from the former chief executive of GitHub Executive Nat Friedman and Y Combinator partner Daniel Gross's pre-seed investment
He was also very active after the release of LlaMA2, and the most ruthless one was to stuff a large model directly into the browser.
Picture Please check Google’s speculative sampling paper: https://arxiv.org/abs/2211.17192
Please check Google’s speculative sampling paper: https://arxiv.org/abs/2211.17192
Reference link: [1]https://x.com/ggerganov/status/1697262700165013689 [2]https://x.com/karpathy/status/1697318534555336961
The above is the detailed content of Apple core runs large models without reducing calculation accuracy. Speculative sampling is crazy. GPT-4 is also used.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- switch error code 2110-2003
- What is the battery capacity of Apple X?
- How many iPhones can be used with one ID?
- ChatGPT suddenly launched the APP! iPhone is available and faster, GPT-4 usage limit is suspected to be lifted
- 'Social Master' GPT-4! Know how to interpret expressions and speculate on psychology