
Home >Technology peripherals >AI >Ali giant model is open source again! It has complete image understanding and object recognition functions. It is trained based on the general problem set 7B and is feasible for commercial applications.
Ali giant model is open source again! It has complete image understanding and object recognition functions. It is trained based on the general problem set 7B and is feasible for commercial applications.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-09-03 13:01:08782browse
Alibaba has open sourced a new large model, which is very exciting~
After Tongyi Qianwen-7B (Qwen-7B), Alibaba Cloud has launched Large-scale visual language model Qwen-VL, and it will be open sourced as soon as it goes online.

Qwen-VL is a large multi-modal model based on Tongyi Qianwen-7B. Specifically, it supports a variety of images, text, and detection frames. Input, and can not only output text, but also output detection frames
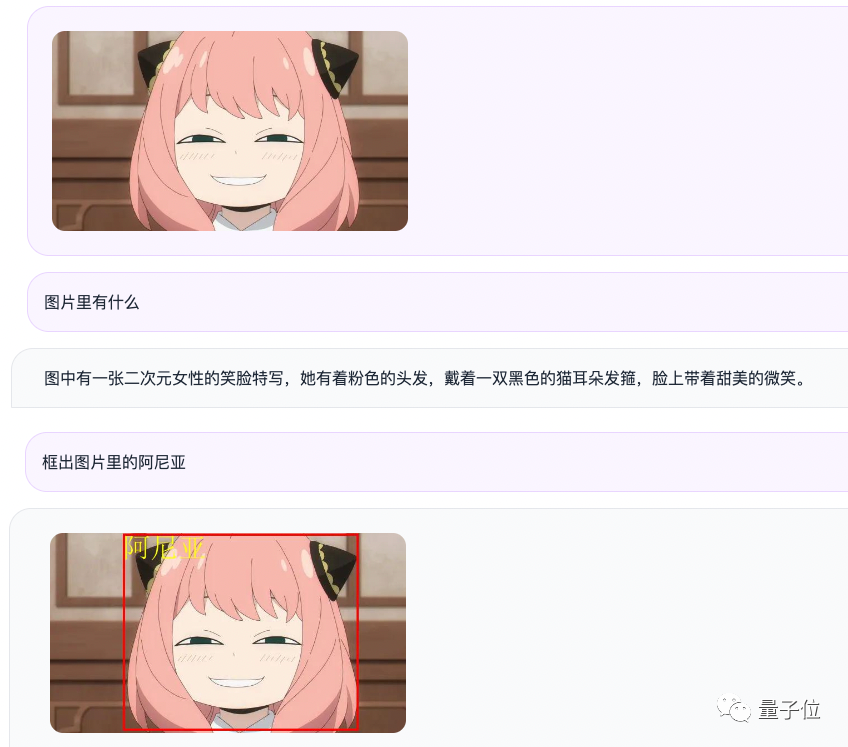
For example, we input a picture of Aniya. Through the form of question and answer, Qwen-VL-Chat can summarize the content of the picture, and Able to accurately locate Aniya in the picture
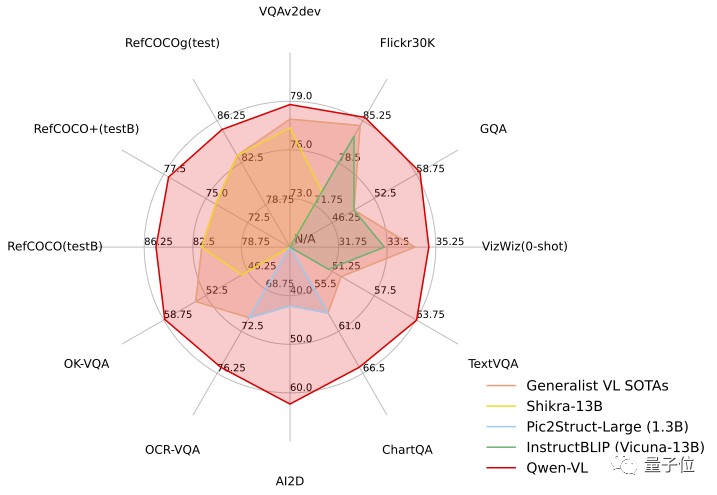
In the test task, Qwen-VL demonstrated the strength of the "Hexagonal Warrior", in four major categories In the standard English evaluation of multi-modal tasks (Zero-shot Caption/VQA/DocVQA/Grounding), the most advanced results have been achieved
Once the open source news came out , immediately attracted widespread attention

Let’s take a look at the specific performance!
The first general model to support Chinese open domain positioning
First of all, let us take an overall look at the characteristics of the Qwen-VL series model:
- Multi-language dialogue : Support multi-language dialogue, end-to-end support for long text recognition in Chinese and English in pictures;
- Multi-picture interleaved dialogue: Support multi-picture input and comparison, designated picture question and answer, multi-picture literary creation, etc.;
- The first general model to support Chinese open domain positioning: detection frame annotation through Chinese open domain language expression, that is, the target object can be accurately found in the picture;
- Fine-grained recognition and understanding: Compared with the 224 resolution currently used by other open source LVLM (Large Scale Visual Language Model), Qwen-VL is the first open source 448 resolution LVLM model. Higher resolution can improve fine-grained text recognition, document question answering and detection box annotation.
Without changing the original meaning, the content that needs to be rewritten is: Qwen-VL can be used in scenarios such as knowledge question and answer, image question and answer, document question and answer, fine-grained visual positioning, etc.
For example, if a foreign friend who does not understand Chinese goes to the hospital to see a doctor and is confused by the navigation map and does not know how to go to the corresponding department, he can directly give the map and questions to Qwen-VL and let it act as a translator based on the picture information.

Conduct the test of multi-image input and comparison again
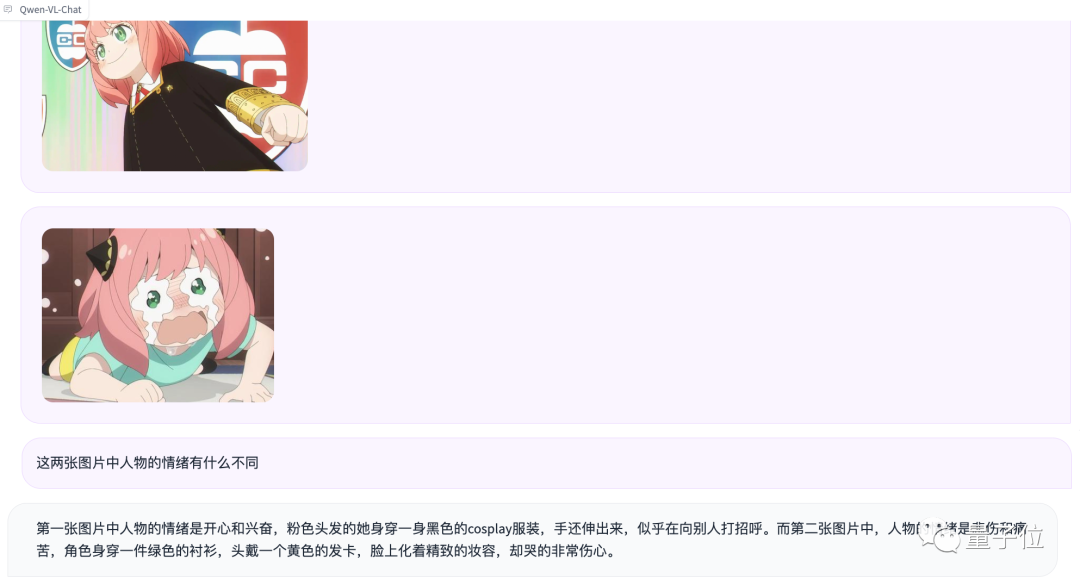
Although Aniya was not recognized, the emotional judgment was It is indeed quite accurate (manual dog head)
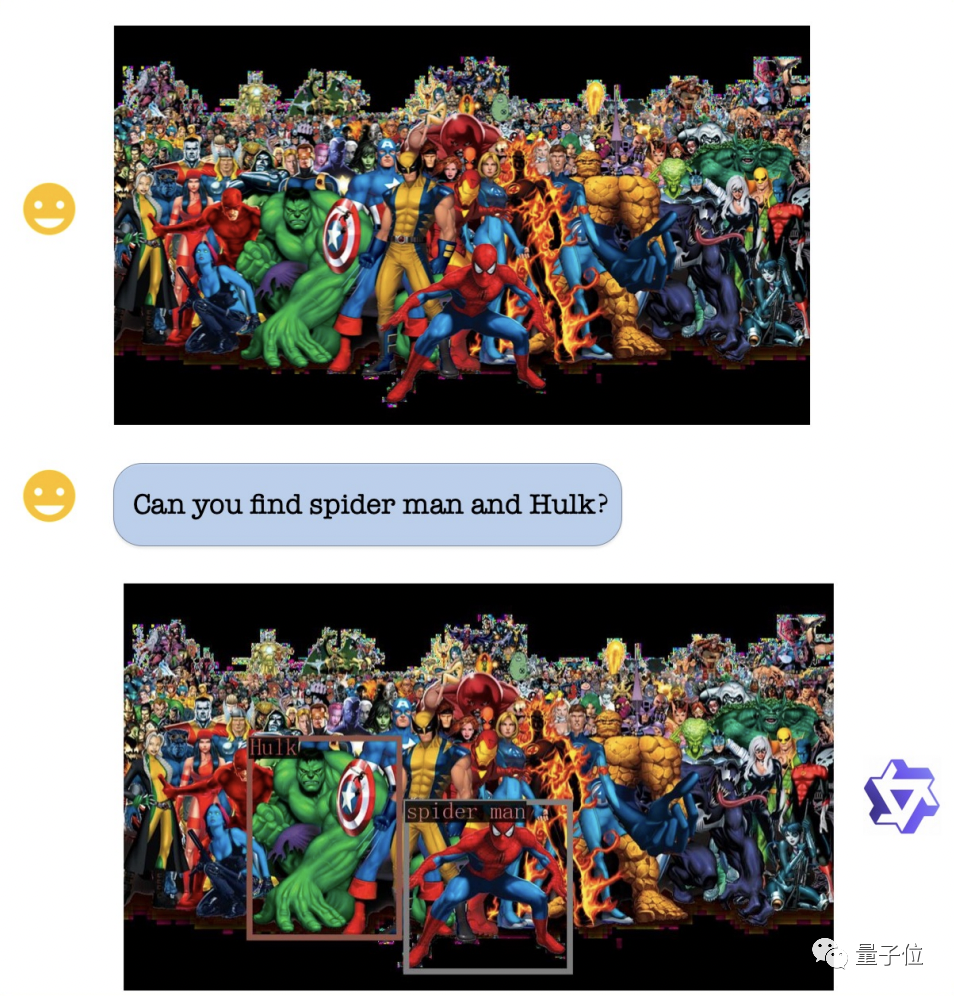
In terms of visual positioning capabilities, even if the picture is very complex and there are many characters, Qwen-VL can still accurately locate the Hulk and Spider-Man upon request
Qwen-VL uses Qwen-7B as the base language model in technical details, and introduces the visual encoder ViT and the position-aware visual language adapter to enable the model to support visual signal input
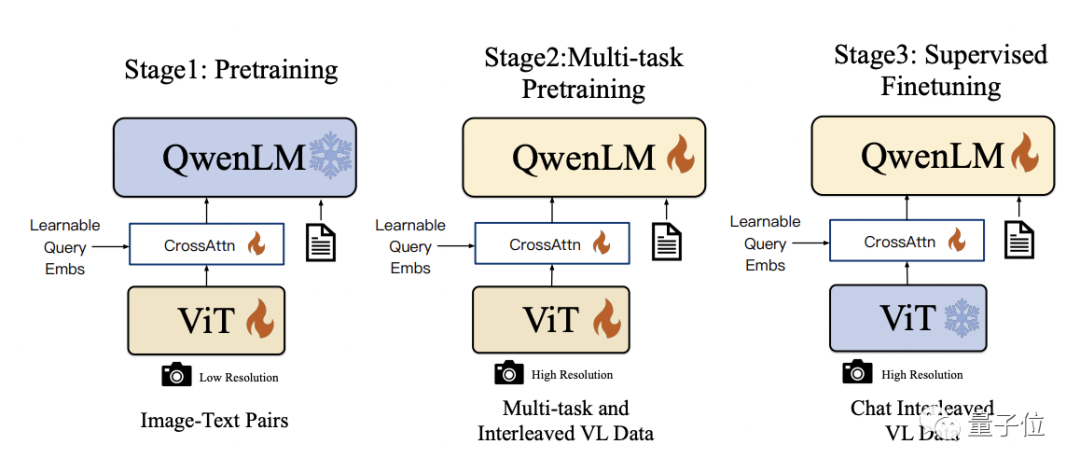
The specific training process is divided into three steps:
- Pre-training: only optimize the visual encoder and visual language adapter, and freeze the language model. Using large-scale image-text paired data, the input image resolution is 224x224.
- Multi-task pre-training: Introduce higher resolution (448x448) multi-task visual language data, such as VQA, text VQA, referential understanding, etc., for multi-task joint pre-training.
- Supervised fine-tuning: Freezing visual encoders, optimizing language models and adapters. Use dialogue interaction data for prompt tuning to obtain the final Qwen-VL-Chat model with interactive capabilities.
In the standard English evaluation of Qwen-VL, researchers tested four major categories of multi-modal tasks (Zero-shot Caption/VQA/DocVQA/Grounding)
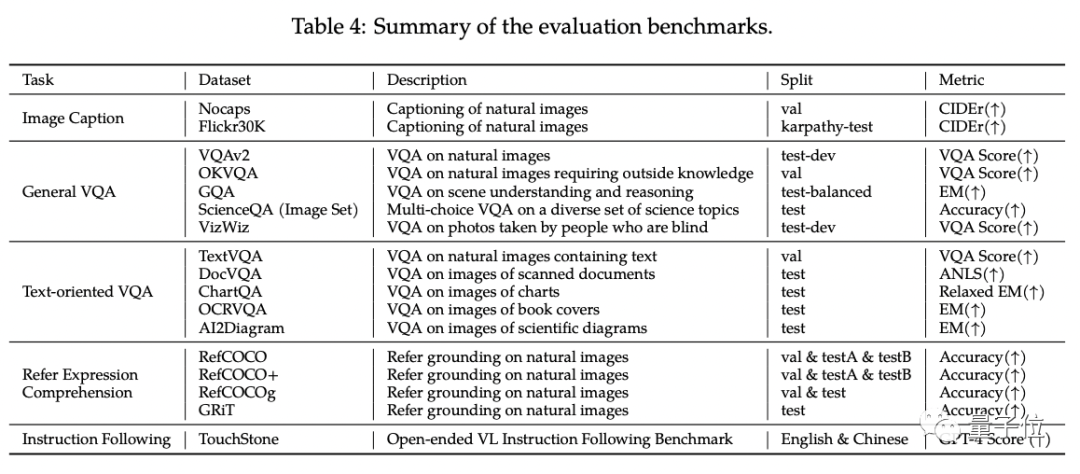
According to the results, Qwen-VL achieved the best results when compared with the open source LVLM of the same size
In addition, the researchers constructed a set of scoring systems based on GPT-4 Mechanism test setTouchStone.


Qwen-VL-Chat achieved state-of-the-art technology (SOTA) in this comparison test
If you are interested in Qwen-VL, you can find the demo on the magic community and huggingface to try it out directly. The link is provided at the end of the article
Qwen-VL supports researchers and developers for secondary development and allows commercial use. However, it should be noted that if you want to use it commercially, you need to fill in the questionnaire application first
Project link: https://modelscope.cn/models/qwen/Qwen-VL /summary
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen -VL
https://huggingface.co/Qwen/Qwen-VL-Chat
https://github.com/QwenLM/Qwen-VL
Please click the following link to view the paper: https://arxiv.org/abs/2308.12966
The above is the detailed content of Ali giant model is open source again! It has complete image understanding and object recognition functions. It is trained based on the general problem set 7B and is feasible for commercial applications.. For more information, please follow other related articles on the PHP Chinese website!