

 Technology peripheralsAIIs fine-tuning the 'knowledge-based image question and answer' useless? Google releases search system AVIS: few samples surpass supervised PALI, and the accuracy is tripled
Technology peripheralsAIIs fine-tuning the 'knowledge-based image question and answer' useless? Google releases search system AVIS: few samples surpass supervised PALI, and the accuracy is tripled
With the support of large language models (LLM), multi-modal tasks combined with vision, such as image description, visual question answering (VQA) and open-vocabulary object detection, etc. Significant progress has been made
However, the current visual language model (VLM) basically only uses the visual information in the image to complete the task, requiring external knowledge assistance in informseek and OK-VQA. Question and answer data sets often perform poorly.

Recently Google has released a new autonomous visual information search method AVIS, which uses large language models (LLM) to dynamically formulate the use of external tools Strategies, including calling API, analyzing output results, decision-making and other operations, provide key knowledge for image question and answer.

Please click the following link to read the paper: https://arxiv.org/pdf/2306.08129.pdf
AVIS mainly integrates three types of tools:
1. Tools for extracting visual information from images
2. Retrieval A web search tool for open world knowledge and facts
3. An image search tool that can be used to retrieve visually similar images
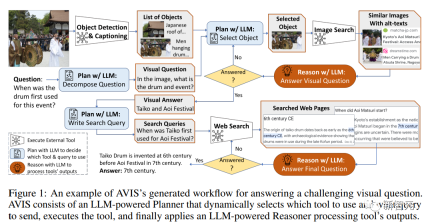
Then use a planner based on a large language model to select a tool and query results at each step to dynamically generate answers to the questions.
Simulating human decision-making
Many visual problems in Infoseek and OK-VQA datasets are quite difficult even for humans, and usually require the assistance of various external tools, So the researchers chose to conduct a user survey first to observe how humans solve complex visual problems.

First, we will provide users with a set of available tools, including PALI, PALM and network search. Next, we show the input image, question, detected object crop, linked knowledge graph entities from the image search results, similar image titles, related product titles, and image descriptions
The researchers then record the user’s actions and output and use two methods to guide the system to answer:
1. Build transformations by analyzing the sequence of decisions made by the user A graph that contains different states, each with a different set of available actions.
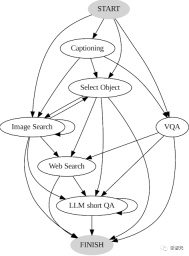
Rewritten content: AVIS conversion diagram The redesigned AVIS conversion diagram is a graphical representation used to illustrate the AVIS conversion process. This diagram clearly illustrates the various stages and steps of AVIS and presents it to the user in an easy-to-understand manner. Through this conversion diagram, users can better understand the working principle and operation process of AVIS. The design of this chart is concise and clear, allowing users to quickly grasp the AVIS conversion process. Both beginners and experienced users can easily understand and apply the conversion process through this AVIS conversion diagram
For example, in the starting state, the system can only perform three operations: PALI description, PALI VQA or target detection.
To improve system performance and effectiveness, examples of human decision-making can be used to guide planners and reasoners to interact with relevant context instances
Overall Framework
The AVIS approach adopts a dynamic decision-making strategy designed to respond to queries for visual information
The system consists of three main component:
The content that needs to be rewritten is: 1. Planner, used to determine subsequent operations, including appropriate API calls and queries that need to be processed
2 . Working memory: Working memory, which retains the result information obtained from API execution.
3. The reasoner is used to process the output of the API call and can determine whether the information obtained is sufficient to generate the final response, or whether additional data retrieval is required
Every time it needs to decide which tool to use and which queries to send to the system, the planner performs a series of actions; depending on the current state, the planner also provides potential follow-up actions
In order to solve the problem that the search space is too large because there may be too many potential action spaces, the planner needs to refer to the transition graph to eliminate irrelevant actions that have been taken before and stored in working memory. Actions.
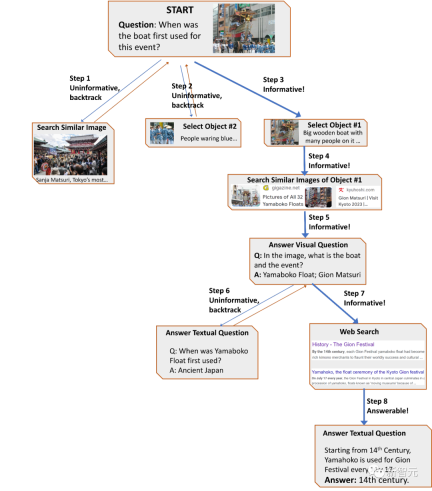
The planner then assembles a set of contextual examples from the user research data, combined with records of previous tool interactions, and after the planner formulates prompts As input to the language model, the LLM returns a structured answer that determines the next tool to activate and the query to dispatch.
The entire design process can be driven by multiple calls to the planner to drive dynamic decisions and gradually generate answers

Researchers use reasoners to analyze the output of tool execution, extract useful information, and decide on the category of tool output: informative, uninformative, or final answer
If the reasoner returns a result of "providing an answer", it directly outputs it as the final result and ends the task; if the result is no information, it returns to the planner and selects another action based on the current state; if the reasoner thinks that the tool output is useful , then the state is modified and control is transferred back to the planner to make new decisions in the new state.
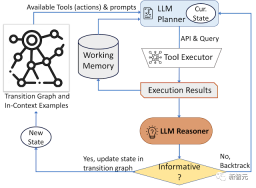
AVIS adopts a dynamic decision-making strategy to respond to visual information search queries
Experimental results
What needs to be rewritten is: Tool collection
Using the PALI 17B model, the image description model can generate descriptions for input images and detected object cropped images
Visual question answering model, using the PALI 17B VQA model, takes images and questions as input and text-based answers as output.
Object detection, using an object detector trained on a superset of the Open Images dataset, provided by the specific category Google Lens API; using a high confidence threshold, only retaining the ranking in the input image The front detection frame.
Use Google Image Search to get image crop information related to the detected box
When making decisions, the planner will The utilization of each piece of information is considered a separate operation, because each piece of information may contain hundreds of tokens and requires complex processing and reasoning.
In some cases, images may contain textual content, such as street names or brand names. You can use the Optical Character Recognition (OCR) feature in the Google Lens API to extract this text
By using the Google Search API for web searches, you can enter a text query and get relevant document links and snippet output results, while also providing a knowledge graph panel containing direct answers and up to five questions related to the input query
Experimental results
The researchers evaluated the AVIS framework on the Infoseek and OK-VQA datasets. From the results, it can be seen that even very robust visual language models such as OFA and PALI model, also cannot obtain high accuracy after fine-tuning on the Infoseek dataset.
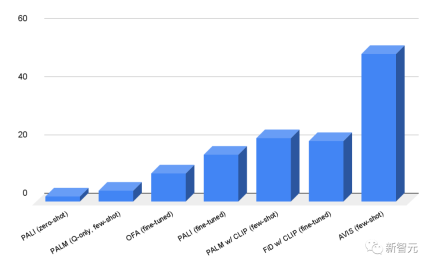
Without fine-tuning, the AVIS method successfully achieved an accuracy of 50.7%
on OK-VQA data On the set, the AVIS system achieved an accuracy of 60.2% under few-shot settings, second only to the fine-tuned PALI model.

Most question and answer examples in OK-VQA rely on common sense knowledge rather than fine-grained knowledge, so the difference in performance is probably due to this . PALI is able to exploit common knowledge encoded in model parameters without relying on the assistance of external knowledge
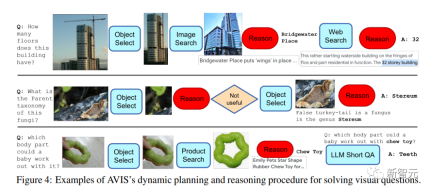
A key feature of AVIS is the ability to dynamically do Make decisions rather than execute fixed sequences. From the above example, you can see the flexibility of AVIS using different tools at different stages.
It is worth noting that the reasoner design in this article enables AVIS to identify irrelevant information, go back to the previous state, and repeat the search.
For example, in the second example about fungal taxonomy, AVIS initially made the wrong decision by selecting a leaf object; after the reasoner found it irrelevant to the problem, it prompted AVIS to re- planning, and then successfully selected the object related to the false turkey tail fungus, resulting in the correct answer, Stereum
Conclusion
The researchers came up with a A new approach, AVIS, uses LLM as an assembly center and uses a variety of external tools to answer knowledge-intensive vision questions.
In this approach, the researchers chose to use human decision-making data collected from user studies as anchors, adopt a structured framework, and use an LLM-based planner to dynamically Decision tool selection and query formation tools until all the necessary information needed to answer the visual question is gathered
The above is the detailed content of Is fine-tuning the 'knowledge-based image question and answer' useless? Google releases search system AVIS: few samples surpass supervised PALI, and the accuracy is tripled. For more information, please follow other related articles on the PHP Chinese website!

 Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PMHarnessing the Power of Data Visualization with Microsoft Power BI Charts In today's data-driven world, effectively communicating complex information to non-technical audiences is crucial. Data visualization bridges this gap, transforming raw data i
 Expert Systems in AIApr 16, 2025 pm 12:00 PM
Expert Systems in AIApr 16, 2025 pm 12:00 PMExpert Systems: A Deep Dive into AI's Decision-Making Power Imagine having access to expert advice on anything, from medical diagnoses to financial planning. That's the power of expert systems in artificial intelligence. These systems mimic the pro
 Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AM
Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AMFirst of all, it’s apparent that this is happening quickly. Various companies are talking about the proportions of their code that are currently written by AI, and these are increasing at a rapid clip. There’s a lot of job displacement already around
 Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AM
Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AMThe film industry, alongside all creative sectors, from digital marketing to social media, stands at a technological crossroad. As artificial intelligence begins to reshape every aspect of visual storytelling and change the landscape of entertainment
 How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AM
How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AMISRO's Free AI/ML Online Course: A Gateway to Geospatial Technology Innovation The Indian Space Research Organisation (ISRO), through its Indian Institute of Remote Sensing (IIRS), is offering a fantastic opportunity for students and professionals to
 Local Search Algorithms in AIApr 16, 2025 am 11:40 AM
Local Search Algorithms in AIApr 16, 2025 am 11:40 AMLocal Search Algorithms: A Comprehensive Guide Planning a large-scale event requires efficient workload distribution. When traditional approaches fail, local search algorithms offer a powerful solution. This article explores hill climbing and simul
 OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AM
OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AMThe release includes three distinct models, GPT-4.1, GPT-4.1 mini and GPT-4.1 nano, signaling a move toward task-specific optimizations within the large language model landscape. These models are not immediately replacing user-facing interfaces like
 The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AM
The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AMChip giant Nvidia said on Monday it will start manufacturing AI supercomputers— machines that can process copious amounts of data and run complex algorithms— entirely within the U.S. for the first time. The announcement comes after President Trump si


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Linux new version
SublimeText3 Linux latest version

Dreamweaver CS6
Visual web development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

