

Kafka is an excellent distributed message middleware. Kafka is used in many systems for message communication. Understanding and using distributed messaging systems has almost become a necessary skill for a backend developer. Today 马哥byte will start with common Kafka interview questions and talk to you about Kafka.

Let’s talk about distributed messaging middleware
Question
#What is distributed messaging middleware? What is the role of message middleware? What are the usage scenarios of message middleware? Message middleware selection?

Distributed messaging is a communication mechanism, which is different from RPC, HTTP, RMI, etc., in the middle of the message The software uses a distributed intermediate agent to communicate. As shown in the figure, after using message middleware, the upstream business system sends messages, which are first stored in the message middleware, and then the message middleware distributes the messages to the corresponding business module applications (distributed producer-consumer model). This asynchronous approach reduces the coupling between services.

Define message middleware:
Use efficient and reliable message passing mechanism for platform-independent data exchange Integration of distributed systems based on data communication By providing message passing and message queuing models, inter-process communication can be expanded in a distributed environment
Referring to additional components in the system architecture will inevitably improve The architectural complexity of the system and the difficulty of operation and maintenance, soWhat are the advantages of using distributed message middleware in the system? What is the role of message middleware in the system?
Decoupling Redundancy (storage) Scalability Peak clipping Recoverability Sequence guarantee -
Buffering Asynchronous Communication
During interviews, interviewers often care about the interviewer’s ability to select open source components. This is both It can test the breadth of the interviewer's knowledge, and it can also test the depth of the interviewer's knowledge of a certain type of system. It can also show the interviewer's ability to grasp the overall system and system architecture design. There are many open source distributed messaging systems, and different messaging systems have different characteristics. Choosing a messaging system requires not only a certain understanding of each messaging system, but also a clear understanding of your own system requirements.
The following is a comparison of several common distributed messaging systems:

Answer Keywords
What is distributed Message middleware? Communication, queue, distributed, producer-consumer model. What is the role of message middleware? Decoupling, peak handling, asynchronous communication, buffering. What are the usage scenarios of message middleware? Asynchronous communication, message storage and processing. Message middleware selection? Language, protocol, HA, data reliability, performance, transaction, ecology, simplicity, push-pull mode.
Kafka basic concepts and architecture
Questions
Briefly talk about the architecture of Kafka? Is Kafka in push mode or pull mode? What is the difference between push and pull? How does Kafka broadcast messages? Are Kafka’s messages in order? Does Kafka support read-write separation? How does Kafka ensure high data availability? What is the role of zookeeper in Kafka? Does it support transactions? Can the number of partitions be reduced?
General concepts in Kafka architecture:

Producer: Producer, that is, the party that sends the message. Producers are responsible for creating messages and then sending them to Kafka. Consumer: Consumer, that is, the party that receives the message. Consumers connect to Kafka and receive messages, and then perform corresponding business logic processing. Consumer Group: A consumer group can contain one or more consumers. Using the multi-partition and multi-consumer approach can greatly improve the processing speed of downstream data. Consumers in the same consumer group will not consume messages repeatedly. Similarly, messages sent by consumers in different consumer groups will not affect each other. Kafka implements message P2P mode and broadcast mode through consumer groups. Broker: Service proxy node. Broker is Kafka's service node, that is, Kafka's server. Topic: Messages in Kafka are divided into Topic units. The producer sends messages to a specific Topic, and the consumer is responsible for subscribing to Topic messages and consuming them. Partition: Topic is a logical concept that can be subdivided into multiple partitions, and each partition only belongs to a single topic. Different partitions under the same topic contain different messages. The partition can be regarded as an appendable log file at the storage level. When messages are appended to the partition log file, they will be assigned a specific offset. ). Offset: offset is the unique identifier of the message in the partition. Kafka uses it to ensure the order of the message within the partition. However, offset does not span partitions. In other words, Kafka guarantees It's partition ordering rather than topic ordering. Replication: Replica is Kafka’s way of ensuring high data availability. Kafka’s data in the same Partition can have multiple copies on multiple Brokers. Usually only the primary copy provides external read and write services. When the broker where the primary replica is located crashes or a network failure occurs, Kafka will reselect a new Leader replica under the management of the Controller to provide external read and write services. Record: The message record that is actually written to Kafka and can be read. Each record contains key, value and timestamp.
Kafka Topic Partitions Layout
 ##Topic
##TopicKafka Consumer Offset
zookeeper

Broker registration: Brokers are deployed in a distributed manner and are independent of each other. Zookeeper is used to manage all Broker nodes registered to the cluster. Topic registration: In Kafka, messages of the same Topic will be divided into multiple partitions and distributed on multiple Brokers. These partition information and the corresponding relationship with the Broker are also All are maintained by Zookeeper Producer load balancing: Since the same Topic message will be partitioned and distributed on multiple Brokers, the producer needs to reasonably distribute the message Sent to these distributed Brokers. Consumer load balancing: Similar to producers, consumers in Kafka also need load balancing to achieve multiple consumers to reasonably receive messages from the corresponding Broker server. A consumer group contains several consumers, and each message will only be sent to one consumer in the group. Different consumer groups consume messages under their own specific Topics without interfering with each other.
Answer Keywords
Briefly explain the architecture of Kafka?
Producer, Consumer, Consumer Group, Topic, Partition
##Is Kafka push mode or pull mode? Push-pull What's the difference? Kafka Producer uses Push mode to send messages to Broker, and Consumer uses Pull mode for consumption. Pull mode, allowing the consumer to manage the offset by itself, can provide read performance
How does Kafka broadcast messages? Consumer group
Are Kafka’s messages in order?
Topic levels are unordered and Partitions are ordered
Does Kafka support read-write separation?
Not supported, only Leader provides external reading and writing services
How does Kafka ensure high data availability?
Copy, ack, HW
What is the role of zookeeper in Kafka?
Cluster management, metadata management
Does it support transactions?
After 0.11, transactions are supported and can be achieved "exactly once"
Can the number of partitions be reduced?
No, data will be lost
Kafka using
Problems
What command line tools does Kafka have? Which ones have you used? The execution process of Kafka Producer? What are the common configurations of Kafka Producer? How to keep Kafka messages in order? Producer How to ensure that data transmission is not lost? How to improve the performance of Producer? If the number of consumers in the same group is greater than the number of parts, how does Kafka handle it? Is Kafka Consumer thread-safe? Tell me about the thread model when you use Kafka Consumer to consume messages. Why is it designed like this? Common configurations of Kafka Consumer? When will a Consumer be kicked out of the cluster? How will Kafka react when a Consumer joins or exits? What is Rebalance and when does Rebalance occur?
Command line tools
Kafka’s command line tools are in the Kafka package’s /bin The directory mainly includes service and cluster management scripts, configuration scripts, information viewing scripts, Topic scripts, client scripts, etc.
kafka-configs.sh: configuration management script kafka-console-consumer.sh:kafka consumer console kafka-console-producer.sh:kafka producer console kafka-consumer-groups.sh:kafka consumer group related information kafka-delete-records.sh: Delete low-water log files kafka-log-dirs.sh: kafka message log directory information kafka-mirror-maker.sh: kafka cluster replication tool in different data centers kafka-preferred-replica-election.sh: trigger preferred replica election kafka-producer-perf-test.sh: kafka producer performance test script kafka-reassign-partitions.sh: partition reassignment script kafka-replica-verification.sh: Replication progress verification script -
kafka-server-start.sh: Start kafka service kafka-server-stop.sh: Stop kafka service kafka-topics.sh: topic management script -
kafka-verifiable-consumer.sh: Verifiable kafka consumer kafka-verifiable-producer.sh: Verifiable kafka producer zookeeper-server-start.sh: Start the zk service zookeeper-server-stop.sh: Stop the zk service zookeeper-shell.sh: zk client
We can usually use kafka-console-consumer.sh and kafka-console-producer.sh Script to test Kafka production and consumption, kafka-consumer-groups.sh can view and manage Topics in the cluster, kafka-topics.sh is usually used to view Kafka's Consumer group situation.
Kafka Producer
The normal production logic of Kafka producer includes the following steps:
Configure the producer Common producer instances for client parameters. Construct the message to be sent. Send a message. Close the producer instance.
Producer The process of sending messages is shown in the figure below. It needs to go through interceptor, serializer and partitioner, finally sent to the Broker in batches by the accumulator.

Kafka Producer requires the following necessary parameters:
bootstrap.server: Specify Kafka's Broker Address key.serializer:key serializer value.serializer:value serializer
Common parameters:
batch.num.messages
Default value: 200, the number of batch messages each time, only for asyc kick in.
##request.required.acks Default value: 0, 0 means that the producer does not need to wait for confirmation from the leader, 1 means that the leader needs to confirm writing to its local log and confirm it immediately, -1 means that the producer needs to confirm after all backups are completed. It only works in async mode. The adjustment of this parameter is a tradeoff between data loss and transmission efficiency. If you are not sensitive to data loss but care about efficiency, you can consider setting it to 0, which can greatly improve the efficiency of the producer in sending data.
request.timeout.ms
Default value: 10000, confirmation timeout.
partitioner.class
Default value: kafka.producer.DefaultPartitioner, kafka.producer.Partitioner must be implemented, Provide a partitioning strategy based on Key. Sometimes we need the same type of messages to be processed sequentially, so we must customize the distribution strategy to allocate the same type of data to the same partition.
producer.type
Default value: sync, specifies whether the message is sent synchronously or asynchronously. Use kafka.producer.AyncProducer for asynchronous asyc batch sending, and kafka.producer.SyncProducer for synchronous sync. Synchronous and asynchronous sending also affect the efficiency of message production.
compression.topic
Default value: none, message compression, no compression by default. Other compression methods include "gzip", "snappy" and "lz4". Compression of messages can greatly reduce network transmission volume and network IO, thus improving overall performance.
##compressed.topics Default value: null. When compression is set, you can specify specific topic compression. If not specified, all compression will be performed.
message.send.max.retries
Default value: 3, the maximum number of attempts to send a message.
retry.backoff.ms
Default value: 300, additional interval added to each attempt.
##topic.metadata.refresh.interval.ms Default value: 600000, obtain metadata regularly time. When the partition is lost and the leader is unavailable, the producer will also actively obtain metadata. If it is 0, metadata will be obtained every time the message is sent, which is not recommended. If negative, metadata is only fetched on failure.
queue.buffering.max.ms Default value: 5000, the maximum cached data in the producer queue Time, only for asyc.
- ##queue.buffering.max.message
Default value: 10000, the maximum number of messages cached by the producer, Just for asyc. ##queue.enqueue.timeout.ms Default value: -1, 0 is discarded when the queue is full, the negative value is the block when the queue is full, the positive value is the corresponding time of the block when the queue is full, only for asyc.
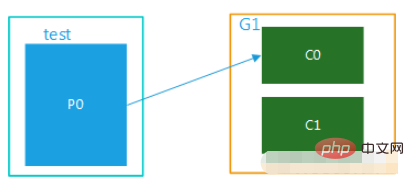
Kafka has the concept of consumer groups. Each consumer only Can consume messages from assigned partitions. Each partition can only be consumed by one consumer in a consumer group. Therefore, if the number of consumers in the same consumer group exceeds the number of partitions, some consumers will appear. The partition that cannot be consumed is allocated. The relationship between consumer groups and consumers is shown in the following figure:
 consumer group
consumer group- Configure the client and create a consumer
- Subscribe to the topic
- Pull the message and consume it
- Submit consumption displacement
- Close consumer instance
 Process
Process
Kafka consumer parameters
bootstrap.servers : Connection broker address, host: portformat.group.id: The consumer group to which the consumer belongs. key.deserializer: Corresponding to the producer's key.serializer, the deserialization method of key.value.deserializer: Corresponding to the producer's value.serializer, the deserialization method of value.session.timeout.ms: The time when coordinator detection failed. Default is 10s. This parameter is the time interval for the Consumer Group to actively detect (comsummer, a member of the group) crash, similar to the heartbeat expiration time. auto.offset.reset: This attribute specifies that when the consumer reads an offset without an offset, the offset is invalid (the consumer has expired for a long time and the current offset has been What should be done in the case of partitions that are outdated and deleted)? The default value is latest, which means reading data from the latest records (records generated after the consumer starts). The other value is earliest, which means that in the partial When the shift amount is invalid, the consumer starts reading data from the starting position. enable.auto.commit: No to automatically submit the displacement. If it is false, you need to manually submit the displacement in the program. For exactly-once semantics, it is best to submit the offset manuallyfetch.max.bytes: The maximum number of bytes for a single pull of data max.poll.records: The maximum number of messages returned by a single poll call. If the processing logic is very lightweight, this value can be increased appropriately. However, max.poll.recordspieces of data need to be processed within session.timeout.ms. The default value is 500request.timeout.ms: The maximum waiting time for a request response. If no response is received within the timeout period, Kafka will either resend the message or directly fail if the number of retries is exceeded.
Kafka Rebalance
Rebalance is essentially a protocol that stipulates how all consumers under a consumer group Agree to allocate each partition subscribed to the topic. For example, there are 20 consumers under a certain group, and it subscribes to a topic with 100 partitions. Under normal circumstances, Kafka allocates an average of 5 partitions to each consumer. This allocation process is called rebalance.
When to rebalance?
This is also a question that is often mentioned. There are three trigger conditions for rebalance:
Group members change (a new consumer joins the group, an existing consumer leaves the group voluntarily, or an existing consumer crashes - the difference between the two will be discussed later) to) The number of subscribed topics has changed The number of partitions subscribed to the topic has changed
How to allocate partitions within a group?
Kafka provides two allocation strategies by default: Range and Round-Robin. Of course, Kafka adopts a pluggable allocation strategy, and you can create your own allocator to implement different allocation strategies.
Answer Keywords
What are the command line tools for Kafka? Which ones have you used? /binDirectory, manage kafka cluster, manage topic, produce and consume kafkaThe execution process of Kafka Producer? Interceptors, Serializers, Partitioners and Accumulators What are the common configurations for Kafka Producer? Broker configuration, ack configuration, network and sending parameters, compression parameters, ack parameters How to keep Kafka messages in order? Kafka itself is unordered at the topic level, and is only ordered at the partition. Therefore, in order to ensure the processing order, you can customize the partitioner and send the data that needs to be processed sequentially to the same partition Producer How to ensure that data is sent without loss? ack mechanism, retry mechanism How to improve the performance of Producer? Batch, asynchronous, compression If the number of consumers in the same group is greater than the number of parts, how does Kafka handle it? The redundant Part will be in a useless state and will not consume data Is Kafka Consumer thread-safe? Unsafe, single-thread consumption, multi-thread processing Tell me about the thread model when you use Kafka Consumer to consume messages. Why is it designed like this? Separating pulling and processing Common configurations for Kafka Consumer? broker, network and pull parameters, heartbeat parameters When will the Consumer be kicked out of the cluster? Crash, network abnormality, processing time is too long, submission displacement timeout How will Kafka react when a Consumer joins or exits? Perform Rebalance What is Rebalance and when does Rebalance occur? Topic changes, consumer changes
High availability and performance
Problems
How does Kafka ensure high availability? Kafka’s delivery semantics? What does Replic do? What's the matter AR, ISR? What are Leader and Flower? What do HW, LEO, LSO, LW, etc. in Kafka stand for? What has Kafka done to ensure superior performance?
Partitions and replicas

In distributed data systems, partitions are usually used to improve the system's processing capabilities and replicas are used to ensure high availability of data. Multi-partitioning means the ability to process concurrently. Among these multiple copies, only one is the leader, and the others are follower copies. Only the leader copy can provide services to the outside world. Multiple follower copies are usually stored in different brokers from the leader copy. Through this mechanism, high availability is achieved. When a certain machine hangs up, other follower copies can quickly "turn to normal" and start providing services to the outside world.
Why does the follower copy not provide read service?
This problem is essentially a trade-off between performance and consistency. Just imagine, what would happen if the follower copy also provided services to the outside world? First of all, performance will definitely be improved. But at the same time, a series of problems will arise. Similar to phantom reading and dirty reading in database transactions. For example, if you write a piece of data to Kafka topic a, consumer b consumes data from topic a, but finds that it cannot consume it because the latest message has not been written to the partition copy that consumer b reads. At this time, another consumer c can consume the latest data because it consumes the leader copy. Kafka uses the management of WH and Offset to determine what data the Consumer can consume and the data currently written.

Only the Leader can provide external read services, so how to elect the Leader
kafka will work with The replicas kept synchronized by the leader replica are placed in the ISR replica set. Of course, the leader copy always exists in the ISR copy set. In some special cases, there is even only one copy of the leader in the ISR copy. When the leader fails, kakfa senses this situation through zookeeper, selects a new copy in the ISR copy to become the leader, and provides services to the outside world. But there is another problem with this. As mentioned earlier, it is possible that there is only the leader in the ISR replica set. When the leader replica dies, the ISR set will be empty. What should we do at this time? At this time, if the unclean.leader.election.enable parameter is set to true, Kafka will select a replica to become the leader in asynchronous, that is, a replica that is not in the ISR replica set.
The existence of copies will cause copy synchronization problems
Kafka maintains an available replica list (ISR) in all allocated replicas (AR). When the Producer sends a message to the Broker, it will determine how many replicas need to wait for the message to be synchronized based on the ack configuration. Only if it succeeds, the Broker will internally use the ReplicaManager service to manage the data synchronization between the flower and the leader.

Performance Optimization
Partition Concurrency Sequential read and write to disk page cache: read and write by page Read ahead: Kafka will read the messages to be consumed into memory in advance High-performance serialization (binary) Memory mapping Lock-free offset management: improve concurrency capability Java NIO model Batch: batch reading and writing Compression: message compression, storage compression, reducing network and IO overhead
Partition concurrency
On the one hand, since different Partitions can be located on different machines, you can make full use of the advantages of the cluster to achieve parallel processing between machines. On the other hand, since Partition physically corresponds to a folder, even if multiple Partitions are located on the same node, different Partitions on the same node can be configured to be placed on different disk drives to achieve parallel processing between disks. Take full advantage of multiple disks.
Sequential reading and writing
The files in each partition directory of Kafka are evenly cut into equal sizes (the default file size is 500 MB, which can be Manually set) data file, Each data file is called a segment file, and each segment uses append to append data.

Answer keyword
How does Kafka ensure high availability?
Ensure high availability of data through replicas, producer ack, retry, automatic Leader election, Consumer self-balancing
Kafka’s delivery semantics?
Delivery semantics generally include
at least once,at most onceandexactly once. Kafka implements the first two through ack configuration.What does Replic do?
Achieve high availability of data
What are AR and ISR?
AR: Assigned Replicas. AR is the set of replicas allocated when the partition is created after the topic is created. The number of replicas is determined by the replica factor. ISR: In-Sync Replicas. A particularly important concept in Kafka refers to the set of replicas in AR that are synchronized with the Leader. The replica in the AR may not be in the ISR, but the Leader replica is naturally included in the ISR. Regarding ISR, another common interview question is how to determine whether a copy should belong to an ISR. The current judgment is based on whether the time when the Follower replica's LEO lags behind the Leader's LEO exceeds the value of the Broker-side parameter replica.lag.time.max.ms. If exceeded, the replica is removed from the ISR.
What are Leader and Flower?
What does HW stand for in Kafka?
High watermark. This is an important field that controls the scope of the message that the consumer can read. An ordinary consumer can only "see" all messages on the Leader replica between Log Start Offset and HW (exclusive). Messages above the water level are invisible to consumers.
What has Kafka done to ensure superior performance?
Partition concurrency, sequential reading and writing to disk, page cache compression, high-performance serialization (binary), memory mapping lock-free offset management, Java NIO model
This article does not go into the implementation details and source code analysis of Kafka, but Kafka is indeed an excellent open source system. Many elegant architectural designs and source code designs are worth learning. It is highly recommended that interested students go more in-depth. Getting to know this open source system will be of great help to your own architectural design capabilities, coding capabilities, and performance optimization.
The above is the detailed content of Completed Kafka from an interview perspective. For more information, please follow other related articles on the PHP Chinese website!

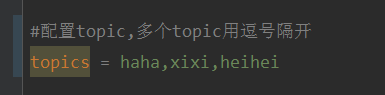 springboot+kafka中@KafkaListener动态指定多个topic怎么实现May 20, 2023 pm 08:58 PM
springboot+kafka中@KafkaListener动态指定多个topic怎么实现May 20, 2023 pm 08:58 PM说明本项目为springboot+kafak的整合项目,故其用了springboot中对kafak的消费注解@KafkaListener首先,application.properties中配置用逗号隔开的多个topic。方法:利用Spring的SpEl表达式,将topics配置为:@KafkaListener(topics=“#{’${topics}’.split(’,’)}”)运行程序,console打印的效果如下
 如何使用PHP和Kafka实现实时股票分析Jun 28, 2023 am 10:04 AM
如何使用PHP和Kafka实现实时股票分析Jun 28, 2023 am 10:04 AM随着互联网和科技的发展,数字化投资已成为人们越来越关注的话题。很多投资者不断探索和研究投资策略,希望能够获得更高的投资回报率。股票交易中,实时的股票分析对决策非常重要,其中使用Kafka实时消息队列和PHP技术实现更是一种高效且实用的手段。一、Kafka介绍Kafka是由LinkedIn公司开发的一个高吞吐量的分布式发布、订阅消息系统。Kafka的主要特点是
 SpringBoot怎么集成Kafka配置工具类May 12, 2023 pm 09:58 PM
SpringBoot怎么集成Kafka配置工具类May 12, 2023 pm 09:58 PMspring-kafka是基于java版的kafkaclient与spring的集成,提供了KafkaTemplate,封装了各种方法,方便操作,它封装了apache的kafka-client,不需要再导入client依赖org.springframework.kafkaspring-kafkaYML配置kafka:#bootstrap-servers:server1:9092,server2:9093#kafka开发地址,#生产者配置producer:#Kafka提供的序列化和反序列化类key
 kafka可视化工具对比分析:如何选择最合适的工具?Jan 05, 2024 pm 12:15 PM
kafka可视化工具对比分析:如何选择最合适的工具?Jan 05, 2024 pm 12:15 PM如何选择合适的Kafka可视化工具?五款工具对比分析引言:Kafka是一种高性能、高吞吐量的分布式消息队列系统,被广泛应用于大数据领域。随着Kafka的流行,越来越多的企业和开发者需要一个可视化工具来方便地监控和管理Kafka集群。本文将介绍五款常用的Kafka可视化工具,并对比它们的特点和功能,帮助读者选择适合自己需求的工具。一、KafkaManager
 go-zero与Kafka+Avro的实践:构建高性能的交互式数据处理系统Jun 23, 2023 am 09:04 AM
go-zero与Kafka+Avro的实践:构建高性能的交互式数据处理系统Jun 23, 2023 am 09:04 AM近年来,随着大数据的兴起和活跃的开源社区,越来越多的企业开始寻找高性能的交互式数据处理系统来满足日益增长的数据需求。在这场技术升级的浪潮中,go-zero和Kafka+Avro被越来越多的企业所关注和采用。go-zero是一款基于Golang语言开发的微服务框架,具有高性能、易用、易扩展、易维护等特点,旨在帮助企业快速构建高效的微服务应用系统。它的快速成长得
 springboot项目配置多个kafka的示例代码May 14, 2023 pm 12:28 PM
springboot项目配置多个kafka的示例代码May 14, 2023 pm 12:28 PM1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2.配置文件相关信息kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#可以并发消费的线程数(通常与partition数量一致)kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 从面试角度一文学完 KafkaAug 24, 2023 pm 03:22 PM
从面试角度一文学完 KafkaAug 24, 2023 pm 03:22 PMKafka 是一个优秀的分布式消息中间件,许多系统中都会使用到 Kafka 来做消息通信。对分布式消息系统的了解和使用几乎成为一个后台开发人员必备的技能。
 Swoole与Kafka的整合:构建高性能MQ系统Jun 13, 2023 pm 08:32 PM
Swoole与Kafka的整合:构建高性能MQ系统Jun 13, 2023 pm 08:32 PM随着互联网和移动设备的不断发展,消息队列成为了现代互联网架构中不可或缺的一部分。消息队列(MQ)可以在不同的应用程序之间传递消息,实现分布式系统中的解耦和异步处理,从而提高整个系统的可伸缩性和性能。在消息队列中,Kafka是一个非常流行和强大的开源消息中间件,而Swoole是一个基于PHP的异步和协程网络编程框架,可以极大地提高PHP应用程序的性能和并发能力


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

