

What I want to share with you today is Distributed Lock. This article uses five cases, diagrams, source code analysis, etc. to analyze.
Common synchronized, Lock and other locks are all implemented based on a single JVM. What should we do in a distributed scenario? At this time, distributed locks appeared.
Regarding distributed implementation solutions, there are three popular ones in the industry:
1, based on database
2, based on Redis
3. Based on Zookeeper
In addition, there are also implementations using etcd and consul.
The two most commonly used solutions in development are Redis and Zookeeper, and the most complex of the two solutions and the most likely to cause problems is Redis implementation plan, so today we will talk about the Redis implementation plan.
Main content of this article

##Distributed lock scenario
It is estimated that some friends are still not clear about distributed usage scenarios. I will briefly list three types below:
Case 1
The following code simulates the scenario of placing an order to reduce inventory. Let's analyze what problems will exist in high concurrency scenarios.@RestController
public class IndexController {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 模拟下单减库存的场景
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
return "end";
}
} Assume that the inventory (stock) is initialized in Redis The value is 100.
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
这行代码,获取到的值都为100,紧跟着判断大于0后都进行-1操作,最后设置到redis 中的值都为99。但正常执行完成后redis中的值应为 95。
案例2-使用synchronized 实现单机锁
在遇到案例1的问题后,大部分人的第一反应都会想到加锁来控制事务的原子性,如下代码所示:
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
synchronized (this){
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}
return "end";
}现在当有多个请求访问该接口时,同一时刻只有一个请求可进入方法体中进行库存的扣减,其余请求等候。
但我们都知道,synchronized 锁是属于JVM级别的,也就是我们俗称的“单机锁”。但现在基本大部分公司使用的都是集群部署,现在我们思考下以上代码在集群部署的情况下还能保证库存数据的一致性吗?
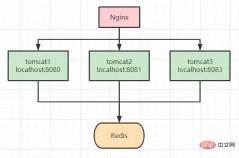
答案是不能,如上图所示,请求经Nginx分发后,可能存在多个服务同时从Redis中获取库存数据,此时只加synchronized (单机锁)是无效的,并发越高,出现问题的几率就越大。
案例3-使用SETNX实现分布式锁
setnx:将 key 的值设为 value,当且仅当 key 不存在。
若给定 key 已经存在,则 setnx 不做任何动作。
使用setnx实现简单的分布式锁:
/**
* 模拟下单减库存的场景
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
// 使用 setnx 添加分布式锁
// 返回 true 代表之前redis中没有key为 lockKey 的值,并已进行成功设置
// 返回 false 代表之前redis中已经存在 lockKey 这个key了
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "wangcp");
if(!result){
// 代表已经加锁了
return "error_code";
}
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
// 释放锁
stringRedisTemplate.delete(lockKey);
return "end";
}我们知道 Redis 是单线程执行,现在再看案例2中的流程图时,哪怕高并发场景下多个请求都执行到了setnx的代码,redis会根据请求的先后顺序进行排列,只有排列在队头的请求才能设置成功。其它请求只能返回“error_code”。
当setnx设置成功后,可执行业务代码对库存扣减,执行完成后对锁进行释放。
我们再来思考下以上代码已经完美实现分布式锁了吗?能够支撑高并发场景吗?答案并不是,上面的代码还是存在很多问题的,离真正的分布式锁还差的很远。
我们分析一下,上面的代码存在的问题:
死锁:假如第一个请求在setnx加锁完成后,执行业务代码时出现了异常,那释放锁的代码就无法执行,后面所有的请求也都无法进行操作了。
针对死锁的问题,我们对代码再次进行优化,添加try-finally,在finally中添加释放锁代码,这样无论如何都会执行释放锁代码,如下所示:
/**
* 模拟下单减库存的场景
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
try{
// 使用 setnx 添加分布式锁
// 返回 true 代表之前redis中没有key为 lockKey 的值,并已进行成功设置
// 返回 false 代表之前redis中已经存在 lockKey 这个key了
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "wangcp");
if(!result){
// 代表已经加锁了
return "error_code";
}
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}finally {
// 释放锁
stringRedisTemplate.delete(lockKey);
}
return "end";
}经过改进后的代码是否还存在问题呢?我们思考正常执行的情况下应该是没有问题,但我们假设请求在执行到业务代码时服务突然宕机了,或者正巧你的运维同事重新发版,粗暴的 kill -9 掉了呢,那代码还能执行 finally 吗?
案例4-加入过期时间
针对想到的问题,对代码再次进行优化,加入过期时间,这样即便出现了上述的问题,在时间到期后锁也会自动释放掉,不会出现“死锁”的情况。
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
try{
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey,"wangcp",10,TimeUnit.SECONDS);
if(!result){
// 代表已经加锁了
return "error_code";
}
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}finally {
// 释放锁
stringRedisTemplate.delete(lockKey);
}
return "end";
}现在我们再思考一下,给锁加入过期时间后就可以了吗?就可以完美运行不出问题了吗?
超时时间设置的10s真的合适吗?如果不合适设置多少秒合适呢?如下图所示

Assume there are three requests at the same time.
Request 1 needs to be executed for 15 seconds after being locked first, but the lock becomes invalid and released after 10 seconds of execution. Request 2 is locked and executed after entering. When request 2 is executed for 5 seconds, request 1 is executed and the lock is released, but the lock of request 2 is released at this time. Request 3 starts executing when request 2 is executed for 5 seconds, but when request 2 is executed for 3 seconds, the lock of request 3 is released.
We can see the problem by just simulating 3 requests now. If it is in a truly high-concurrency scenario, the lock may face "always invalid" or "permanent invalid".
So where is the specific problem? The summary is as follows:
1. When there is a request to release the lock, the lock released is not your own lock 2. The timeout period has expired Short, the existing code will be automatically released before it is executed
We think about the corresponding solutions to the problem:
For question 1, we think of Generate a unique id when the request comes in, use this unique id as the value of the lock, obtain and compare first when releasing, and then release when the comparison is the same, this can solve the problem of releasing other request locks. Regarding question 2, is it really appropriate for us to think about continuously extending the expiration time? If the setting is too short, there will be a problem of automatic release over time. If the setting is too long, there will be a problem that the lock cannot be released for a period of time after a shutdown, although "deadlock" will no longer occur. How to solve this problem?
Case 5-Redisson distributed lock
Spring BootIntegrationRedissonSteps
引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>初始化客户端
@Bean
public RedissonClient redisson(){
// 单机模式
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.3.170:6379").setDatabase(0);
return Redisson.create(config);
}Redisson实现分布式锁
@RestController
public class IndexController {
@Autowired
private RedissonClient redisson;
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 模拟下单减库存的场景
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
// 1.获取锁对象
RLock redissonLock = redisson.getLock(lockKey);
try{
// 2.加锁
redissonLock.lock(); // 等价于 setIfAbsent(lockKey,"wangcp",10,TimeUnit.SECONDS);
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}finally {
// 3.释放锁
redissonLock.unlock();
}
return "end";
}
}Redisson 分布式锁实现原理图
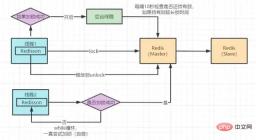
Redisson 底层源码分析
我们点击lock()方法,查看源码,最终看到以下代码
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}没错,加锁最终执行的就是这段lua 脚本语言。
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;脚本的主要逻辑为:
exists 判断 key 是否存在 当判断不存在则设置 key 然后给设置的key追加过期时间
这样来看其实和我们前面案例中的实现方法好像没什么区别,但实际上并不是。
这段lua脚本命令在Redis中执行时,会被当成一条命令来执行,能够保证原子性,故要不都成功,要不都失败。
我们在源码中看到Redssion的许多方法实现中很多都用到了lua脚本,这样能够极大的保证命令执行的原子性。
下面是Redisson锁自动“续命”源码:
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {
task.cancel();
}
}这段代码是在加锁后开启一个守护线程进行监听。Redisson超时时间默认设置30s,线程每10s调用一次判断锁还是否存在,如果存在则延长锁的超时时间。
现在,我们再回过头来看看案例5中的加锁代码与原理图,其实完善到这种程度已经可以满足很多公司的使用了,并且很多公司也确实是这样用的。但我们再思考下是否还存在问题呢?例如以下场景:
As we all know Redisis deployed in a cluster in actual deployment and use. In high concurrency scenarios, we lock. After writing the key to the master node, the master still The master went down when it was not synchronized to the slave node. The original slave node became the new master node after election. At this time, the lock failure problem may occur.Through the implementation mechanism of distributed locks, we know that in high concurrency scenarios, only successfully locked requests can continue to process business logic. Then everyone comes to lock, but only one lock is successful, and the rest are waiting. In fact, distributed locks and high concurrency are semantically contradictory. Although our requests are all concurrent, Redishelps us queue the requests for execution, which means converting our parallelism into serialization. . There will definitely be no concurrency problems in serially executed code, but the performance of the program will definitely be affected.
In response to these problems, we are thinking about solutions again
Thinking When solving the problem, we first think of the CAP principle (consistency, availability, partition tolerance), then the current
Redissatisfies AP (availability, partition tolerance). If we want to solve this problem, we need to find A distributed system that meetsCP(consistency, partition fault tolerance). The first thing that comes to mind isZookeeper. The inter-cluster data synchronization mechanism ofZookeeperis that when the master node receives the data, it will not immediately return a successful feedback to the client. It will first communicate with the child node. Synchronization, the client will be notified of successful reception only after more than half of the nodes have completed synchronization.And if the master node goes down, the re-elected master node according to theZabprotocol ofZookeeper(Zookeeperatomic broadcast) must have been successfully synchronized.Then the question is, how do we choose between
RedissonandZookeeperdistributed locks? The answer is that if the amount of concurrency is not that high, you can useZookeeperto do distributed locks, but its concurrency capability is far inferior toRedis. If you have relatively high concurrency requirements, then use Redis. The occasional master-slave architecture lock failure problem is actually tolerable.Regarding the second issue of improving performance, we can refer to the idea of lock segmentation technology of
ConcurrentHashMap, such as the inventory of our code The amount is currently 1000, then we can divide it into 10 segments, each segment is 100, and then lock each segment separately, so that the locking and processing of 10 requests can be performed at the same time. Of course, students who have requirements can continue to subdivide. But in fact, theQpsofRedishas reached10W, which is completely sufficient in scenarios without particularly high concurrency.
The above is the detailed content of Distributed lock: 5 cases, from entry to burial. For more information, please follow other related articles on the PHP Chinese website!

 Treatment of x² in curve integral: Why can the standard answer be ignored (1/3) x³?Apr 19, 2025 pm 08:06 PM
Treatment of x² in curve integral: Why can the standard answer be ignored (1/3) x³?Apr 19, 2025 pm 08:06 PMQuestions about a curve integral This article will answer a curve integral question. The questioner had a question about the standard answer to a sample question...
 What should I do if the Redis cache of OAuth2Authorization object fails in Spring Boot?Apr 19, 2025 pm 08:03 PM
What should I do if the Redis cache of OAuth2Authorization object fails in Spring Boot?Apr 19, 2025 pm 08:03 PMIn SpringBoot, use Redis to cache OAuth2Authorization object. In SpringBoot application, use SpringSecurityOAuth2AuthorizationServer...
 In JDBC's PreparedStatement, why do you need to use a specific parameter type setting method instead of the general setObject method?Apr 19, 2025 pm 08:00 PM
In JDBC's PreparedStatement, why do you need to use a specific parameter type setting method instead of the general setObject method?Apr 19, 2025 pm 08:00 PMJDBC...
 Why can't the main class be found after copying and pasting the package in IDEA? Is there any solution?Apr 19, 2025 pm 07:57 PM
Why can't the main class be found after copying and pasting the package in IDEA? Is there any solution?Apr 19, 2025 pm 07:57 PMWhy can't the main class be found after copying and pasting the package in IDEA? Using IntelliJIDEA...
 Java multi-interface call: How to ensure that interface A is executed before interface B is executed?Apr 19, 2025 pm 07:54 PM
Java multi-interface call: How to ensure that interface A is executed before interface B is executed?Apr 19, 2025 pm 07:54 PMState synchronization between Java multi-interface calls: How to ensure that interface A is called after it is executed? In Java development, you often encounter multiple calls...
 In Java programming, how to stop subsequent code execution when student ID is repeated?Apr 19, 2025 pm 07:51 PM
In Java programming, how to stop subsequent code execution when student ID is repeated?Apr 19, 2025 pm 07:51 PMHow to stop subsequent code execution when ID is repeated in Java programming. When learning Java programming, you often encounter such a requirement: when a certain condition is met,...
 Ultimate consistency: What business scenarios are applicable to? How to ensure the consistency of the final data?Apr 19, 2025 pm 07:48 PM
Ultimate consistency: What business scenarios are applicable to? How to ensure the consistency of the final data?Apr 19, 2025 pm 07:48 PMIn-depth discussion of final consistency: In the distributed system of application scenarios and implementation methods, ensuring data consistency has always been a major challenge for developers. This article...
 After the Spring Boot service is running for a period of time, how to troubleshoot?Apr 19, 2025 pm 07:45 PM
After the Spring Boot service is running for a period of time, how to troubleshoot?Apr 19, 2025 pm 07:45 PMThe troubleshooting idea of SSH connection failure after SpringBoot service has been running for a period of time has recently encountered a problem: a Spring...


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

SublimeText3 Linux new version
SublimeText3 Linux latest version

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SublimeText3 English version
Recommended: Win version, supports code prompts!

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

