
Home >Java >javaTutorial >More than 6,000 words | Points to note when designing the Flash Kill system
More than 6,000 words | Points to note when designing the Flash Kill system
- Java后端技术全栈forward
- 2023-08-23 14:28:011101browse
Five architectural principles
The data should be as small as possible
The first thing is that the user can request as little data as possible. The requested data includes data uploaded to the system and data returned by the system to the user (usually a web page).
The number of requests should be as small as possible
After the page requested by the user is returned, the browser will also include other additional requests when rendering this page, for example, this page depends on CSS/JavaScript, images, and Ajax requests are all defined as "extra requests", and these extra requests should be as few as possible.
The path should be as short as possible
It is the number of intermediate nodes that need to be passed through in the process from the user making a request to returning the data.
Dependencies should be as few as possible
refers to the system or service that must be relied upon to complete a user request. The dependencies here refer to strong dependencies.
High Availability
The single point in the system can be said to be a taboo in the system architecture, because the single point means no backup and the risk is uncontrollable. We design a distributed system The most important principle is "elimination of single points", also known as "high availability".
Architecture is an art of balance, and once the best architecture is separated from the scene it adapts to, everything will be empty talk. What we need to remember is that the points mentioned here are just directions. We should try our best to work in these directions, but we must also consider balancing other factors.
How to separate dynamic and static data
What is dynamic and static data
So what exactly is dynamic and static separation? The so-called "dynamic and static separation" actually means dividing the data requested by the user (such as HTML page) into "dynamic data" and "static data". Simply put, the main difference between "dynamic data" and "static data" is to see whether the data output in the page is related to the URL, browser, time, region, and whether it contains private data such as cookies.
For many media websites, the content of a certain article is the same whether you visit it or I visit it. So it is a typical static data, but it is a dynamic page. If we visit Taobao’s homepage now, the page that everyone sees may be different. Taobao’s homepage contains a lot of recommended information based on visitor characteristics, and these personalities The data can be understood as dynamic data.
How to cache static data?
First, you should cache static data closest to the user. Static data is data that is relatively unchanged, so we can cache it. Where is it cached? There are three common ones: in the user's browser, on the CDN, or in the server's Cache. You should cache them as close to the user as possible according to the situation.
Second, static transformation is to directly cache HTTP connections. Compared with ordinary data caching, you must have heard of static transformation of the system. The static transformation directly caches the HTTP connection instead of just caching the data. As shown in the figure below, the Web proxy server directly takes out the corresponding HTTP response header and response body according to the request URL and returns it directly. This response process is so simple that it does not even use the HTTP protocol. Reassembled, even the HTTP request headers do not need to be parsed.
Third, who should cache the static data is also important. Cache software written in different languages has different efficiencies in processing cached data. Take Java as an example, because the Java system itself also has its weaknesses (for example, it is not good at handling a large number of connection requests, each connection consumes more memory, and the Servlet container is slow to parse the HTTP protocol), so you can not do caching at the Java layer, but Do it directly on the Web server layer, so that you can shield some weaknesses at the Java language level; in comparison, Web servers (such as Nginx, Apache, Varnish) are also better at handling large concurrent static file requests.
How to make the transformation of dynamic and static separation
Unique URL Separate browser-related factors Separation time factor Asynchronous regional factor Remove Cookie
Several architectural solutions for dynamic and static separation
According to the complexity of the architecture, there are three options available:
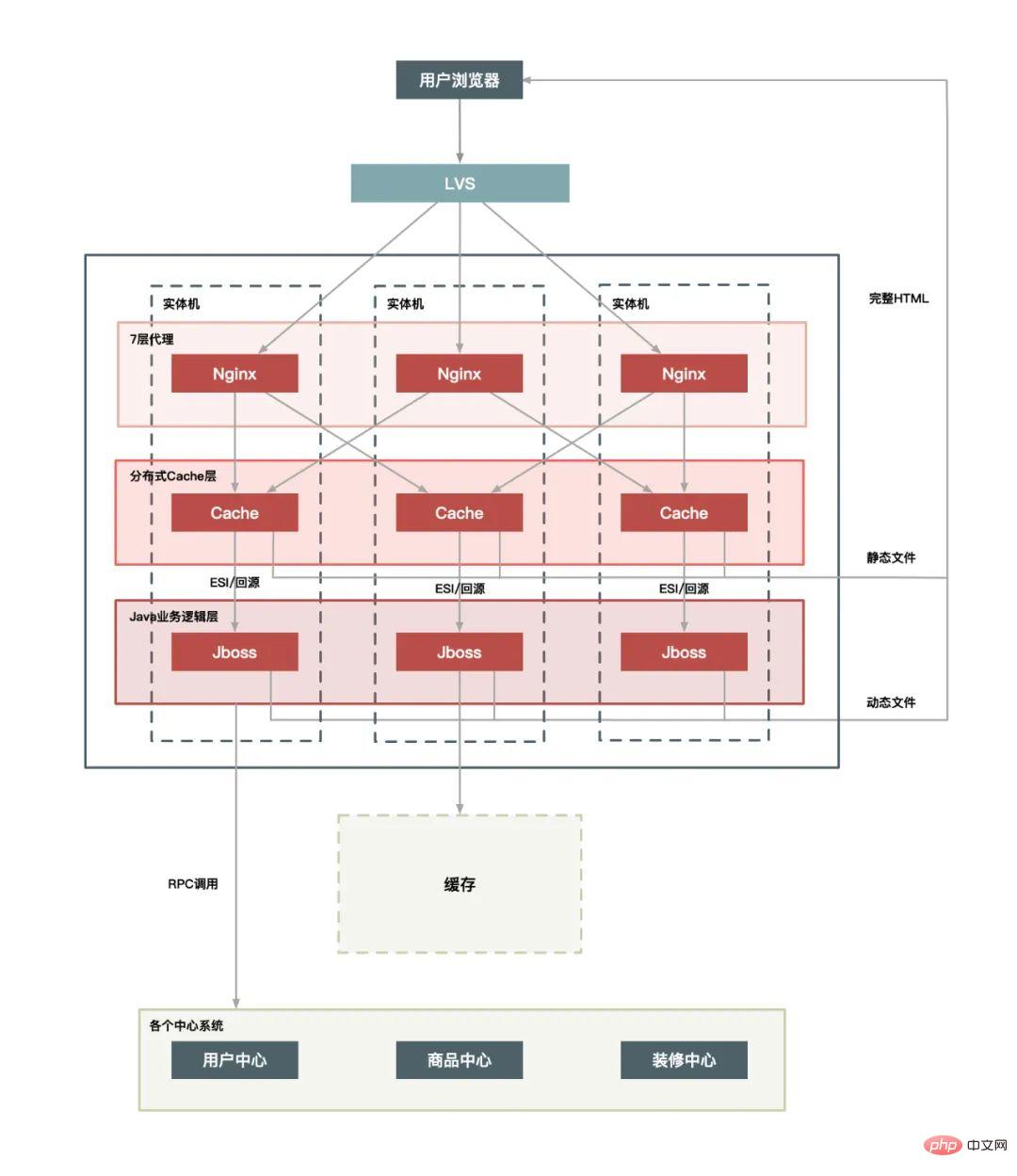
Single-machine deployment of physical machines:
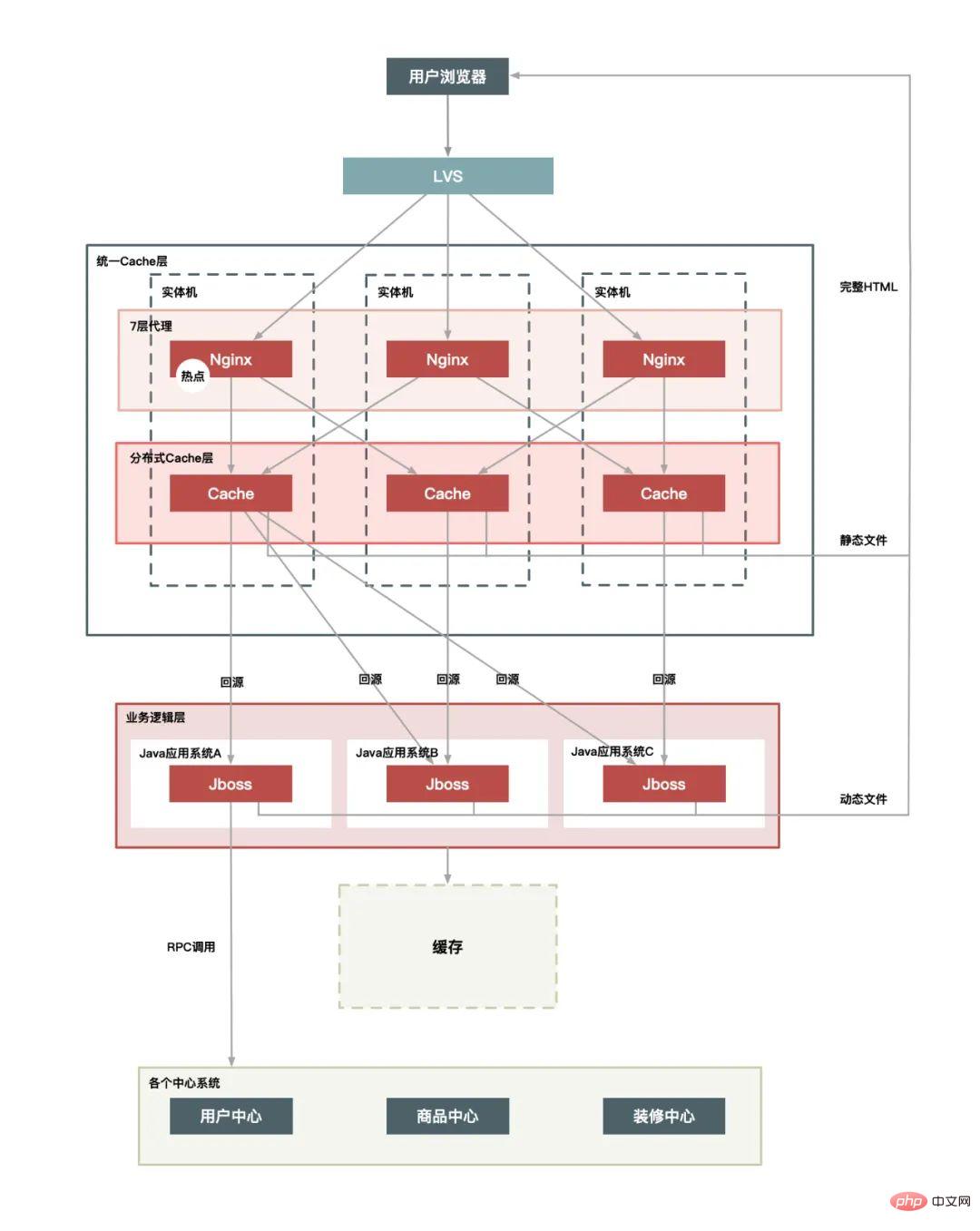
Unified Cache layer:
plus CDN layer:
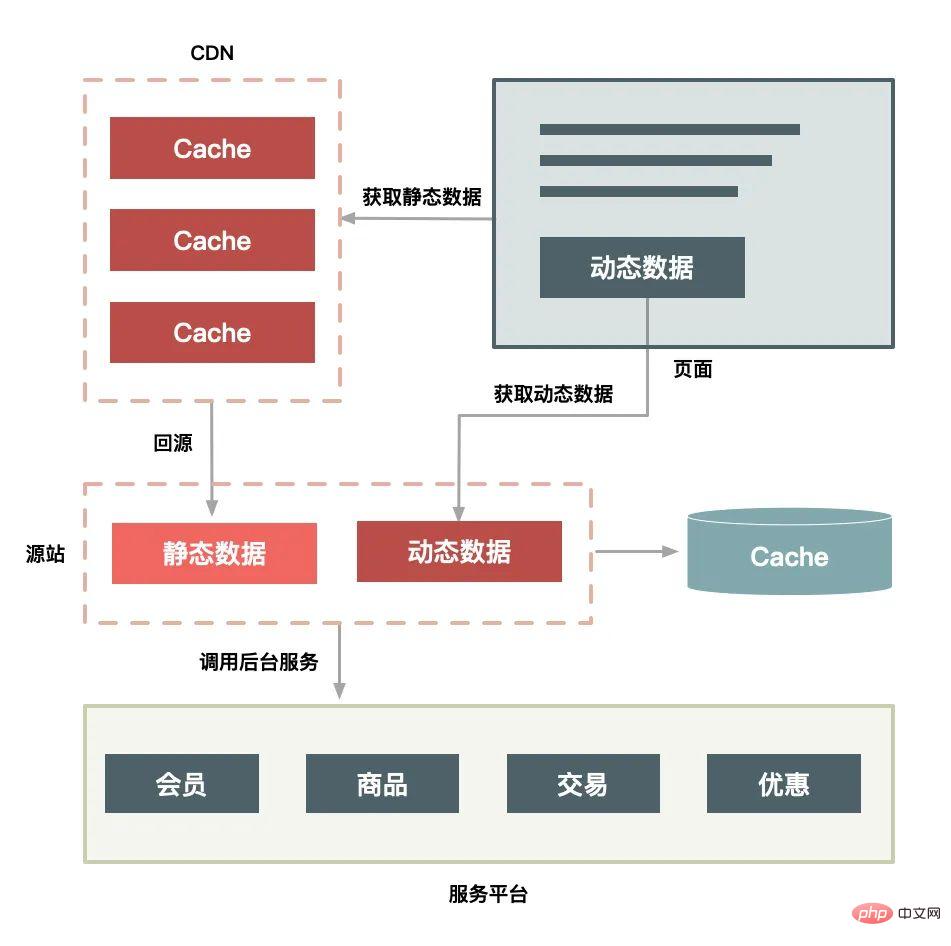
The CDN deployment solution also has the following features:
Cache the entire page in the user's browser; If you force refresh the entire page, CDN will also be requested; The actual valid request is just the user's click on the "Refresh Treasure Grab" button.
How to handle the hot data of flash sale system?
What is "hotspot"
Hotspots are divided into hotspot operations and hotspot data.
So-called "hot operations", such as a large number of page refreshes, a large number of adding shopping carts, a large number of orders placed at 0:00 on Double Eleven, etc., all belong to this type of operation. For the system, these operations can be abstracted into "read requests" and "write requests". These two hotspot requests are handled in very different ways. The optimization space for read requests is larger, while the bottleneck for write requests is generally in the storage layer. The idea of optimization is to balance based on the CAP theory. I will introduce this content in detail in the article "Reducing Inventory".
The "hotspot data" is easier to understand, that is, the data corresponding to the user's hotspot request. Hotspot data is divided into "static hotspot data" and "dynamic hotspot data".
The so-called "static hotspot data" refers to hotspot data that can be predicted in advance. For example, we can filter out sellers in advance through registration and mark these hot products through the registration system. In addition, we can also use big data analysis to discover hot products in advance. For example, we analyze historical transaction records and user shopping cart records to discover which products may be more popular and better-selling. These are all hot spots that can be analyzed in advance.
The so-called "dynamic hotspot data" refers to hotspots that cannot be predicted in advance and are temporarily generated during the operation of the system. For example, a seller advertises on Douyin, and then the product becomes popular immediately, causing it to be purchased in large quantities in a short period of time.
Since hotspot operations are user behaviors, we cannot change them, but we can make some restrictions and protections. Therefore, in this article, I will mainly introduce how to optimize hotspot data.
Discover hotspot data
Discover static hotspot data -
Discover dynamic hotspot data
Processing hotspot data
Optimization
The most effective way to optimize hotspot data is to cache hotspot data. If Hotspot data is separated from static data, so static data can be cached for a long time. However, caching hotspot data is more of a "temporary" cache, that is, whether it is static data or dynamic data, it is cached briefly in a queue for a few seconds. Since the queue length is limited, it can be replaced by the LRU elimination algorithm.
limit
Restriction is more of a protection mechanism, and there are many ways to restrict it. For example, do a consistent hash on the ID of the item being accessed, and then bucket it based on the hash. Set a processing queue for each bucket, so that you can Hot products are limited to a request queue to prevent certain hot products from taking up too many server resources and causing other requests to never receive processing resources from the server.
Isolation
The first principle of flash sale system design is to isolate this hot data, do not let 1% of the requests affect the other 99%, isolate After it comes out, it will be more convenient to make targeted optimization for these 1% of requests. Isolation can be divided into: business isolation, system isolation, and data isolation.
How to do traffic peak shaving
Just like roads in the city, because of the problems of morning peak and evening peak, there is a solution of peak shifting and traffic restriction.
The existence of peak clipping can, firstly, make server-side processing more stable, and secondly, it can save the resource cost of the server.
For the flash sale scenario, peak clipping essentially delays the issuance of user requests in order to reduce and filter out some invalid requests. It follows the principle of "the number of requests should be as small as possible".
Traffic Peak Shaving Ideas
Queue
To peak traffic, the easiest solution to think of is to use message queues Buffer instantaneous traffic and convert synchronous direct calls into asynchronous indirect push. In the middle, a queue is used to handle the instantaneous traffic peak at one end, and the message is smoothly pushed out at the other end.
In addition to the message queue, there are many similar queuing methods, such as:
Using the thread pool to lock and wait is also a common queuing method; The implementation of common memory queuing algorithms such as first-in-first-out and first-in-last-out; Serialize the request into a file and then read it sequentially files (such as the synchronization mechanism based on MySQL binlog) to restore requests, etc.
It can be seen that these methods have a common feature, which is to turn the "one-step operation" into a "two-step operation", in which the added one-step operation is used to buffer role.
Performance optimization
Reduce encoding Reduce serialization Java Ultimate Optimization Concurrent read optimization
##"Inventory reduction" core logic
This is very important, all other steps are auxiliary. If there are 100 pieces in stock, just sell 100 pieces and reduce it to 0 in the database. What's the trouble? Yes, this is the case in theory, but in specific business scenarios, "reducing inventory" is not that simple.What are the ways to reduce inventory
Click the "Buy Now" button on the product page, check the information and click "Submit Order". This step is called Next Single operation. After placing an order, you can only truly purchase when you complete the payment operation, which is what the saying goes: "Safety in pocket". There are generally several ways to reduce inventory:Decrease inventory after placing an order
That is, after the buyer places an order, the quantity purchased by the buyer will be subtracted from the total inventory of the product. Placing an order to reduce inventory is the simplest way to reduce inventory, and it is also the most precise method of control. When placing an order, the inventory of goods is directly controlled through the transaction mechanism of the database, so that oversold conditions will not occur. But you have to know that some people may not pay after placing an order.
Payment to Reduce Inventory
That is, after the buyer places the order, the inventory is not reduced immediately, but the inventory is actually reduced until the user pays, otherwise the inventory will be retained. to other buyers. However, because the inventory is reduced only after payment is made, if the concurrency is relatively high, there may be a situation where the buyer cannot pay after placing the order, because the goods may have been bought by others.
Withholding Inventory
This method is relatively complicated. After the buyer places an order, the inventory is reserved for a certain period of time (such as 10 minutes). If it exceeds this time , the inventory will be automatically released, and other buyers can continue to purchase after it is released. Before the buyer pays, the system will verify whether the inventory of the order is still reserved: if there is no reservation, the withholding will be tried again; if the inventory is insufficient (that is, the withholding fails), the payment will not be allowed to continue; if the withholding is successful, Then the payment is completed and the inventory is actually deducted.
Where to start with high-availability construction
When it comes to high-availability construction of the system, it is actually a system project that needs to take into account all stages of system construction, as well as That is to say, it actually runs through the entire life cycle of system construction, as shown in the following figure:
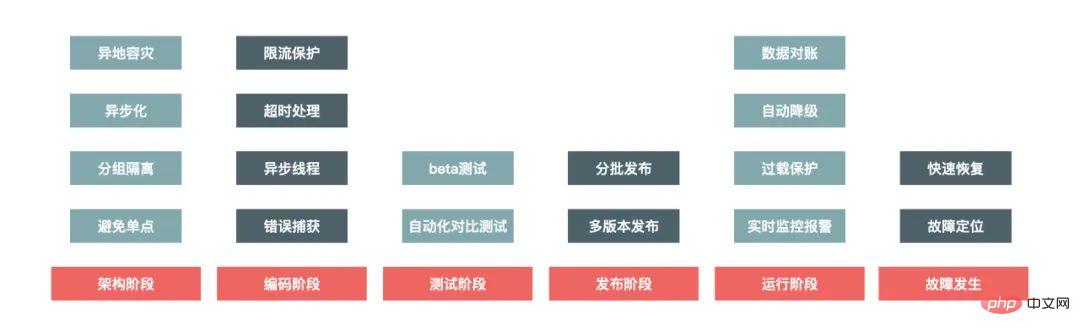
Architecture Phase
The architecture phase mainly considers the scalability and fault tolerance of the system, and avoids single point problems in the system. For example, in the unit deployment of multiple computer rooms, even if a certain computer room in a certain city suffers from an overall failure, it will still not affect the operation of the entire website.
Coding stage
The most important thing in coding is to ensure the robustness of the code. For example, when remote calling issues are involved, a reasonable timeout exit mechanism must be set up to prevent being used by other systems. In order to prevent the returned results from exceeding the processing scope of the program, the most common method is to capture error exceptions and have default processing results for unforeseen errors.
Testing Phase
Testing is mainly to ensure the coverage of test cases and to ensure that when the worst case occurs, we also have corresponding processing procedures.
Release Phase
There are also some things that need to be paid attention to when publishing, because errors are most likely to occur during publishing, so there must be an emergency rollback mechanism.
Running phase
Running time is the normal state of the system. The system will be in the running state most of the time. The most important thing in the running state is to monitor the system accurately and timely. Accurate alarms can be made when problems are discovered, and the alarm data must be accurate and detailed to facilitate troubleshooting.
Fault occurs
When a fault occurs, the first and most important thing is to stop the loss in time. For example, if the product price is wrong due to a program problem, the product must be removed from the shelves or the purchase link must be closed in time. Prevent significant asset losses. Then it is necessary to be able to restore services in a timely manner and locate the cause and solve the problem.
How should we maximize the normal operation of our system when encountering heavy traffic?
Downgrade
The so-called "downgrade" means that when the capacity of the system reaches a certain level, some non-core functions of the system are restricted or shut down, thereby reducing the limited resources. Reserved for more core business. It is a purposeful and planned execution process, so for downgrade we generally need to have a set of plans to coordinate the execution. If we systematize it, we can achieve degradation through a planning system and a switching system.
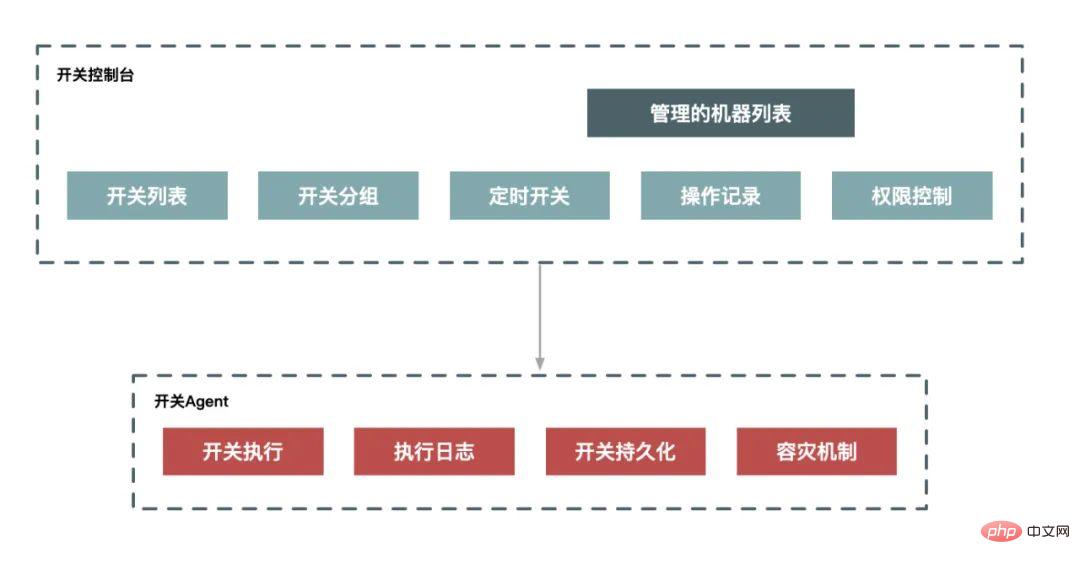
Current limiting
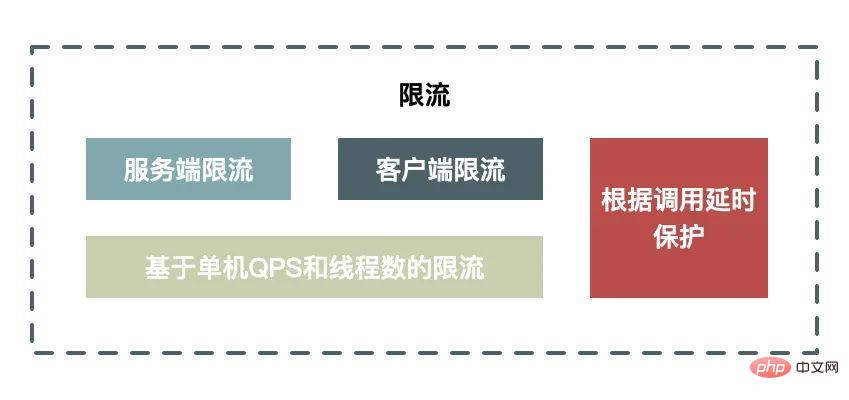
Current limiting means that when the system capacity reaches the bottleneck, we need to protect the system by limiting a part of the traffic, and It can not only manually execute the switch, but also support automatic protection measures.
The advantages and disadvantages of client-side current limiting and server-side current limiting:
Client-side current limiting has the advantage of limiting the issuance of requests and reducing the consumption of the system by reducing useless requests. The disadvantage is that when clients are scattered, it is impossible to set a reasonable current limiting threshold: if the threshold is set too small, the client will be restricted before the server reaches the bottleneck; if it is set too large, it will not be able to The role of restrictions.
The advantage of server-side current limiting is that a reasonable threshold can be set according to the performance of the server. The disadvantage is that the restricted requests are invalid requests, and processing these invalid requests itself will consume server resources.
Common current limiting algorithm
Counter (fixed window) algorithm
Counter The algorithm uses a counter to accumulate the number of accesses within a period, and when the set current limit value is reached, the current limit policy is triggered. At the beginning of the next cycle, it is cleared and counted again.
This algorithm is very simple to implement in a stand-alone or distributed environment. It can be easily implemented using the incr atomic self-increment and thread safety of redis.
Sliding window algorithm
The sliding window algorithm divides the time period into N small periods, records the number of visits in each small period, and deletes them according to the time sliding Expired minor cycles. This algorithm can well solve the critical problem of fixed window algorithm.
Leaky bucket algorithm
Leaky bucket algorithm is to put the access request directly into the leaky bucket when it arrives. If the current capacity has reached the upper limit (current limit value), it will be discarded. (Trigger current limiting policy). The leaky bucket releases access requests (that is, the requests pass) at a fixed rate until the leaky bucket is empty.
Token Bucket Algorithm
The Token Bucket Algorithm is that the program adds tokens to the token bucket at a rate of r (r=time period/current limit value) until the The token bucket is full. When the request arrives, it will request a token from the token bucket. If the token is obtained, the request will be passed. Otherwise, the current limiting policy will be triggered.
Denial of Service
If Current limiting cannot solve the problem, so the last resort is to refuse service directly. When the system load reaches a certain threshold, for example, the CPU usage reaches 90% or the system load value reaches 2*CPU cores, the system directly rejects all requests. This method is the most violent but also the most effective system protection method. For example, in the flash sale system, we design overload protection in the following aspects:
Set overload protection on the front-end Nginx. When the machine load reaches a certain value, the HTTP request is directly rejected and a 503 error code is returned. In Java Layers can also be designed with overload protection.
Denial of service can be said to be a last resort solution to prevent the worst-case scenario from happening and preventing the server from being completely unable to provide services for a long time. Although system overload protection like this cannot provide services when overloaded, the system can still operate and can easily recover when the load drops. Therefore, every system and every link should set up this backup plan to prepare the system for the worst-case scenario. under protection.
Cache problem
Cache avalanche
The data is not loaded into the cache, or the cache fails in a large area at the same time, Causes all requests to look up the database, causing database, CPU, and memory overload, or even downtime.
A simple avalanche process:
1) Large-scale failure of the Redis cluster;
2) Caching failure, but there are still a large number of requests to access the cache service Redis;
3) After a large number of Redis requests failed, the requests were transferred to the database;
4) Database requests increased sharply, causing the database to be killed;
##5) Since most of your application services depend on For database and Redis services, it will quickly cause an avalanche of server clusters, and eventually the entire system will collapse completely.Solution:
Beforehand: Highly available cache
Highly available cache is to prevent the entire cache failure. Even if individual nodes, machines or even computer rooms are shut down, the system can still provide services, and both Redis Sentinel and Redis Cluster can achieve high availability.In progress: Cache downgrade (temporary support)
How do we ensure that the service is still available when the number of visits increases sharply and causes problems with the service. Hystrix, which is widely used in China, uses three methods: fusing, downgrading, and current limiting to reduce losses after avalanches. As long as the database is not dead, the system can always respond to requests. Isn’t this how we come here every Spring Festival 12306? As long as you can still respond, you at least have a chance to grab a ticket.
Afterwards: Redis backup and fast warm-up
1) Redis data backup and recovery
2) Fast cache warm-up
Cache breakdown
Cache breakdown means that multiple threads request hotspot data at the same time when the hotspot data storage expires. Because the cache has just expired, all concurrent requests will go to the database to query data.
Solution:
In fact, in most actual business scenarios, cache breakdown occurs in real time, but it will not cause too much pressure on the database. Because for general company business, the amount of concurrency will not be that high. Of course, if you are unfortunate enough to have this happen, you can set these hotspot keys so they never expire. Another method is to use a mutex lock to control thread access to the query database, but this will cause the system throughput to decrease and needs to be used in actual situations.
Cache penetration
Cache penetration refers to querying a data that definitely does not exist. Because there is no information about the data in the cache, it will go directly to the database layer for query. From a system level, it seems that it penetrates the cache layer and directly reaches the db, which is called cache penetration. Without the protection of the cache layer, this kind of query for data that must not exist may be a danger to the system. If someone Malicious use of this kind of data that definitely does not exist to frequently request the system, no, to be precise, it is to attack the system. The requests will reach the database layer, causing the db to be paralyzed and causing system failure.
Solution:
The solutions in the cache penetration industry are relatively mature, and the main commonly used ones are the following:
Bloom filter: An algorithm similar to a hash table, using all possible query conditions to generate a bitmap. This bitmap will be used to filter before database query. If it is not among them, it will be filtered directly, thereby reducing the database level. pressure. Null value caching: A relatively simple solution. After querying the non-existent data for the first time, the key is matched with the corresponding null value (null or only key) is also put into the cache, but it is set to a shorter expiration time, such as a few minutes, so that it can deal with a large number of attacks on this key in a short period of time. The reason for setting a shorter expiration time is because the value may not be relevant to the business. , its existence is of little significance, and the query may not be initiated by the attacker, so there is no need to store it for a long time, so it can be invalidated early.
Summary
Since this article is a theoretical article, there is not a single line of code in the entire article, but it is mentioned in the article Basically, it is what happened to the flash sale system. The problems that may occur in each system are different.
The above is the detailed content of More than 6,000 words | Points to note when designing the Flash Kill system. For more information, please follow other related articles on the PHP Chinese website!