
The database is divided into databases and tables. When? How to divide?
- Java后端技术全栈forward
- 2023-08-17 16:31:551272browse
1. Data segmentation
Relational database It is relatively easy to become a system bottleneck. The storage capacity, number of connections, and processing capabilities of a single machine are limited. When the data volume of a single table reaches 1000W or 100G, due to the large number of query dimensions, even if slave databases are added and indexes are optimized, the performance will still drop severely when performing many operations. At this time, it is necessary to consider segmenting it. The purpose of segmentation is to reduce the burden on the database and shorten the query time.
1000W or 100G can be said to be the industry reference value. The specifics depend on the current system hardware facilities, table structure design and other factors.
The core content of database distribution is nothing more than data segmentation (Sharding), as well as the positioning and integration of data after segmentation. Data segmentation is to disperse and store data into multiple databases, so that the amount of data in a single database is reduced. By expanding the number of hosts, the performance problems of a single database are alleviated, thereby achieving the purpose of improving database operation performance.
Data segmentation can be divided into two ways according to its segmentation type: vertical (longitudinal) segmentation and horizontal (horizontal) segmentation
1. Vertical (Vertical) Segmentation
Vertical segmentation is commonly divided into two types: vertical database partitioning and vertical table partitioning.
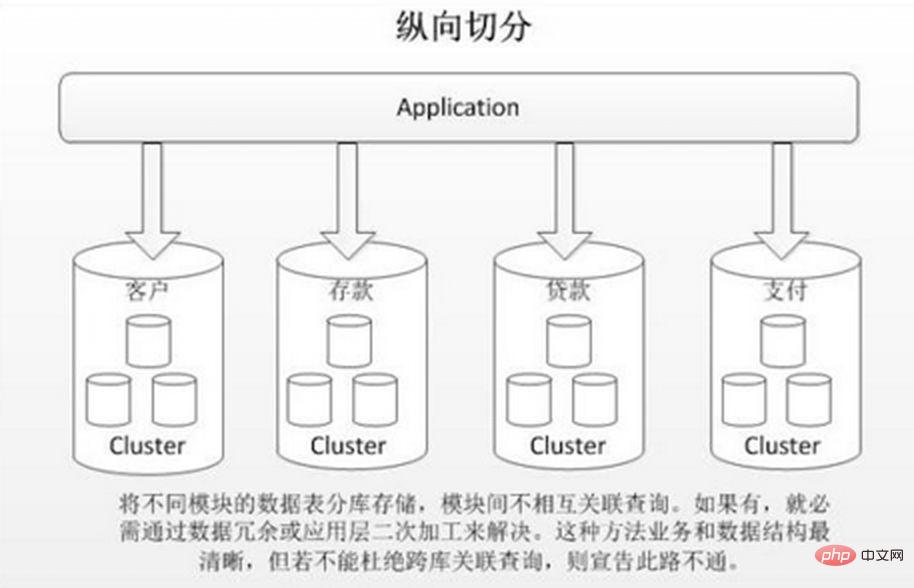
Vertical database sharding is to store different tables with low correlation in different databases based on business coupling. The approach is similar to splitting a large system into multiple small systems, which are divided independently according to business classification. Similar to the approach of "microservice governance", each microservice uses a separate database. As shown in the picture:
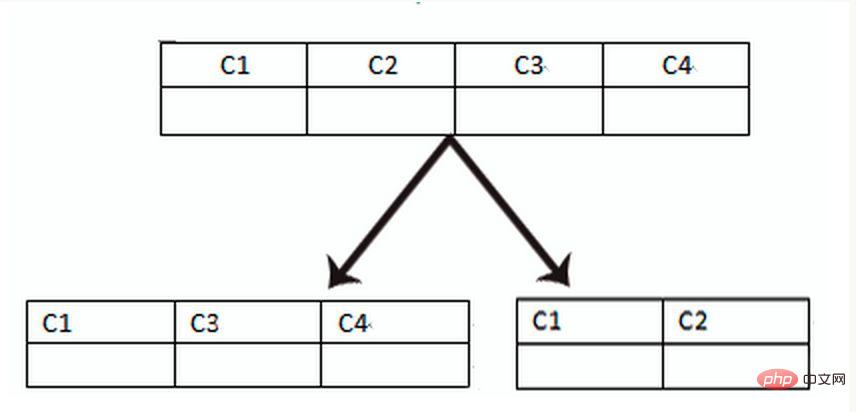
Vertical table partitioning is based on the "columns" in the database. If a table has many fields, you can create a new extended table, which will not Frequently used fields or fields with large field lengths are split out into extended tables. When there are many fields (for example, a large table has more than 100 fields), "split the large table into small tables" is easier to develop and maintain, and can also avoid cross-page problems. The bottom layer of MySQL is stored through data pages. Recording that takes up too much space will lead to page crossing, causing additional performance overhead. In addition, the database loads data into the memory in units of rows, so that the field length in the table is shorter and the access frequency is higher. The memory can load more data, the hit rate is higher, and the disk IO is reduced, thus improving the database performance.
Advantages of vertical segmentation:
1. Solve the coupling at the business system level and make the business clear 2. With The governance of microservices is similar, and it can also perform hierarchical management, maintenance, monitoring, and expansion of data of different businesses. 3. In high-concurrency scenarios, vertical segmentation can increase the bottlenecks of IO, database connections, and single-machine hardware resources to a certain extent
Disadvantages:
1. Some tables cannot be joined and can only be solved through interface aggregation, which increases the complexity of development. 2. Distributed transaction processing is complex. 3. There is still an excessive amount of data in a single table. Problem (requires horizontal segmentation)
2. Horizontal (horizontal) segmentation
When an application is difficult to fine-grained vertical segmentation Or the number of rows of data after segmentation is huge, and there are bottlenecks in reading, writing, and storage performance of a single database. At this time, horizontal segmentation is required.
Horizontal sharding is divided into intra-database sharding and sub-database sharding. It is based on the inherent logical relationship of the data in the table. The same table is dispersed into multiple databases or multiple tables according to different conditions. Each table only contains a part of the data, thus reducing the amount of data in a single table and achieving a distributed effect. As shown in the figure:
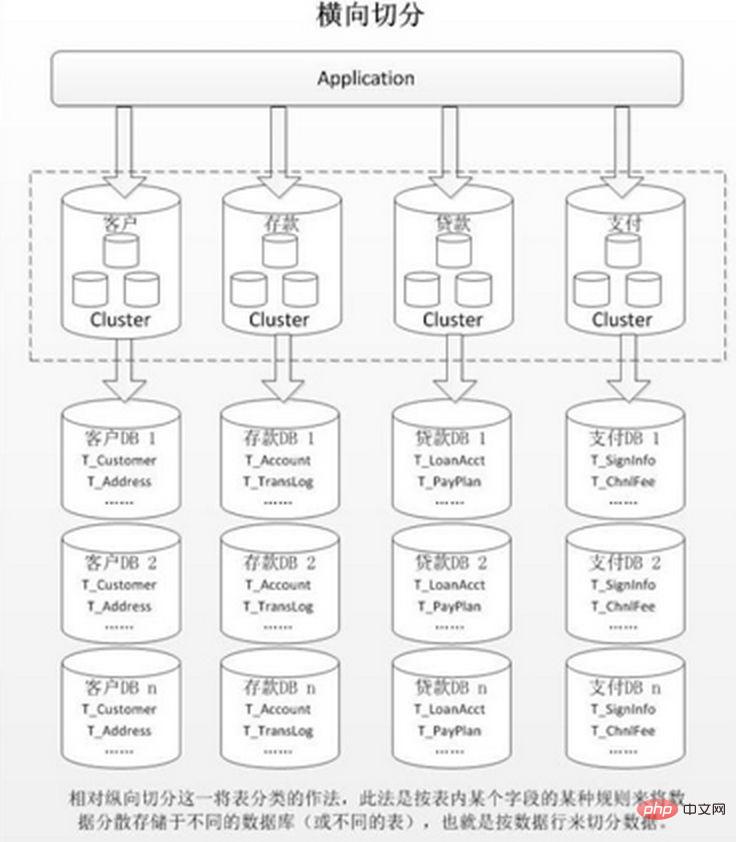
Internal table partitioning only solves the problem of excessive data volume in a single table, but does not distribute the table to libraries on different machines, so it is not very helpful in reducing the pressure on the MySQL database. Everyone still competes for the CPU, memory, and network IO of the same physical machine. This is best solved by dividing databases and tables.
Advantages of horizontal sharding:
1. There is no performance bottleneck caused by excessive data volume and high concurrency in a single database, which improves system stability and load capacity. 2. The application-side transformation is small. No need to split the business module
Disadvantages:
1. Transaction consistency across shards is difficult to guarantee. 2. Cross-database join query performance is poor. 3. Multiple expansion of data is difficult and the amount of maintenance is huge.
The same table after horizontal splitting It will appear in multiple databases/tables, and the content of each database/table is different. Several typical data fragmentation rules are:
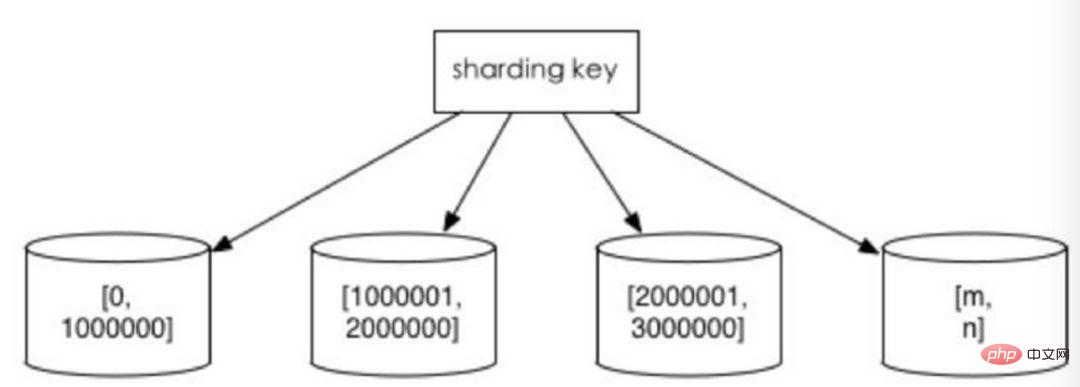
1. Split according to the value range
according to the time interval or ID interval. For example: distribute data of different months or even days into different libraries by date; assign records with userIds from 1 to 9999 to the first library, records with userIds from 10000 to 20000 to the second library, and so on. In a sense, the "hot and cold data separation" used in some systems, migrating some less used historical data to other libraries, and only providing hot data queries in business functions, is a similar practice.
The advantages of this are:
1. The size of a single table is controllable. 2. It is naturally easy to expand horizontally. If you want to expand the entire sharded cluster later, you only need to add nodes, no need to Migrate data from other shards 3. When using shard fields for range searches, continuous sharding can quickly locate shards for quick query, effectively avoiding cross-shard query problems.
Disadvantages:
Hotspot data becomes a performance bottleneck. Continuous sharding may have data hotspots, such as sharding by time fields. Some shards store data in the most recent time period and may be frequently read and written, while some shards store historical data that is rarely queried
2. Take the modulo based on the numerical value
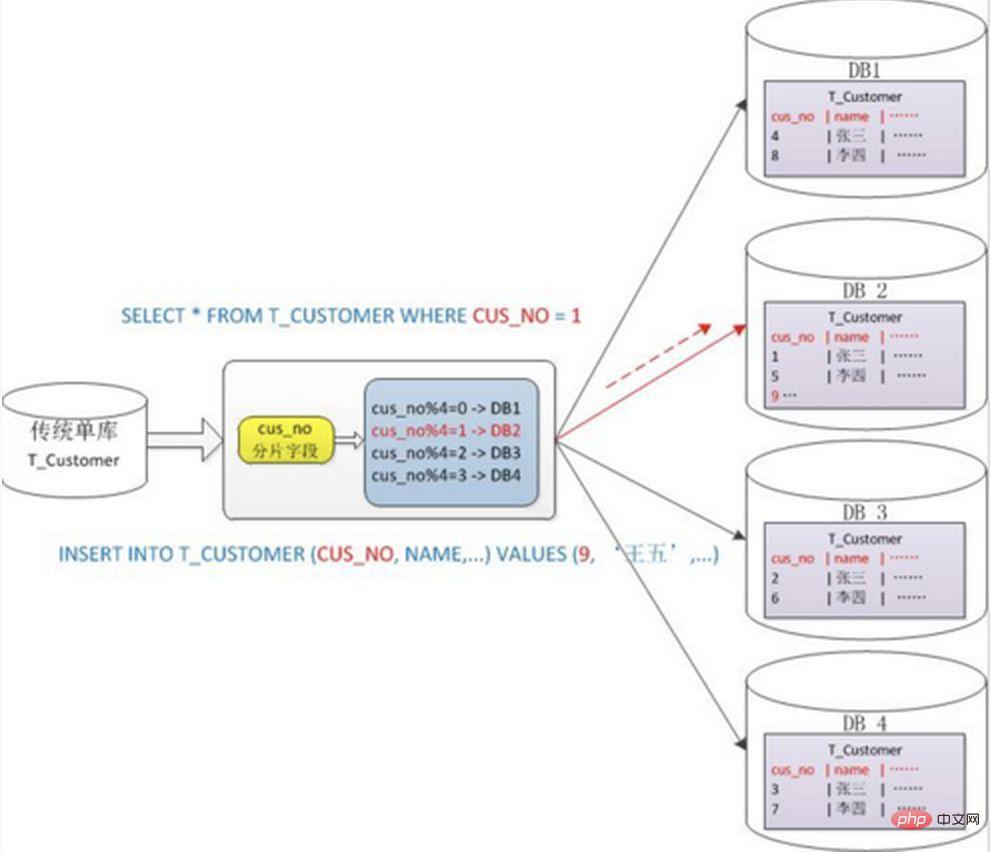
Generally use hash to get Mod's splitting method, for example: split the Customer table into 4 libraries based on the cusno field, put the remainder of 0 in the first library, the remainder of 1 in the second library, and so on. In this way, the data of the same user will be scattered into the same database. If the query condition contains the cusno field, the corresponding database can be clearly positioned for query.
Advantages:
Data fragmentation is relatively even, and it is not prone to hot spots and concurrent access bottlenecks
Disadvantages:
1. When the sharded cluster is expanded later, old data needs to be migrated (using a consistent hash algorithm can better avoid this problem) 2. It is easy to face the complex problem of cross-shard query. For example, in the above example, if cusno is not included in the frequently used query conditions, the database will not be located. Therefore, it is necessary to initiate queries to four libraries at the same time, then merge the data in the memory, take the minimum set and return it to the application. Instead, the library became a drag.
2. Problems caused by database and table sharding
Sub-database and sub-table can effectively eliminate the performance bottlenecks and pressures caused by single machines and single databases, break through the bottlenecks of network IO, hardware resources, and number of connections, and also bring about some problems. These technical challenges and corresponding solutions are described below.
1. Transaction consistency issue
Distributed transaction
When updated content is distributed in different libraries at the same time, cross-database transaction problems will inevitably occur. Cross-shard transactions are also distributed transactions, and there is no simple solution. Generally, the "XA protocol" and "two-phase commit" can be used to handle them.
Distributed transactions can ensure the atomicity of database operations to the greatest extent. However, when submitting a transaction, multiple nodes need to be coordinated, which delays the time point of submitting the transaction and prolongs the execution time of the transaction. This leads to an increased probability of conflicts or deadlocks when transactions access shared resources. As the number of database nodes increases, this trend will become more and more serious, thus becoming a shackle for the horizontal expansion of the system at the database level.
Eventual Consistency
For those systems with high performance requirements but low consistency requirements, the real-time performance of the system is often not required. Consistency, as long as the final consistency is achieved within the allowed time period, transaction compensation can be used. Different from the method of rolling back the transaction immediately after an error occurs during execution, transaction compensation is a post-mortem check and remedial measure. Some common implementation methods include: reconciliation check of data, comparison based on logs, and regular comparison with standard data sources. Sync and more. Transaction compensation should also be considered in conjunction with the business system.
2. Cross-node association query join problem
Before segmentation, the data required for many lists and detail pages in the system can be processed through sql join to complete. After segmentation, the data may be distributed on different nodes. At this time, the problems caused by join will be more troublesome. Considering the performance, try to avoid using join query.
Some ways to solve this problem:
1) Global table
The global table can also be regarded as " "Data dictionary tables" are tables that all modules in the system may depend on. In order to avoid cross-database join queries, a copy of such tables can be saved in each database. These data are usually rarely modified, so there is no need to worry about consistency issues.
2) Field redundancy
A typical anti-paradigm design that uses space for time and avoids join queries for the sake of performance. For example: when the order table saves the userId, it also saves a redundant copy of the userName, so that when querying the order details, there is no need to query the "buyer user table".
However, the applicable scenarios of this method are also limited, and it is more suitable for situations where there are relatively few dependent fields. The data consistency of redundant fields is also difficult to ensure. Just like the example of the order table above, after the buyer modifies the userName, does it need to be updated synchronously in the historical orders? This should also be considered in conjunction with actual business scenarios.
3) Data assembly
#At the system level, the query is divided into two. The results of the first query focus on finding the associated data id. Then initiate a second request based on the id to obtain the associated data. Finally, the obtained data is assembled into fields.
4) ER sharding
In a relational database, if you can first determine the relationship between tables and associate those If the relational table records are stored on the same shard, cross-shard join problems can be better avoided. In the case of 1:1 or 1:n, it is usually split according to the ID primary key of the main table. As shown in the figure below:
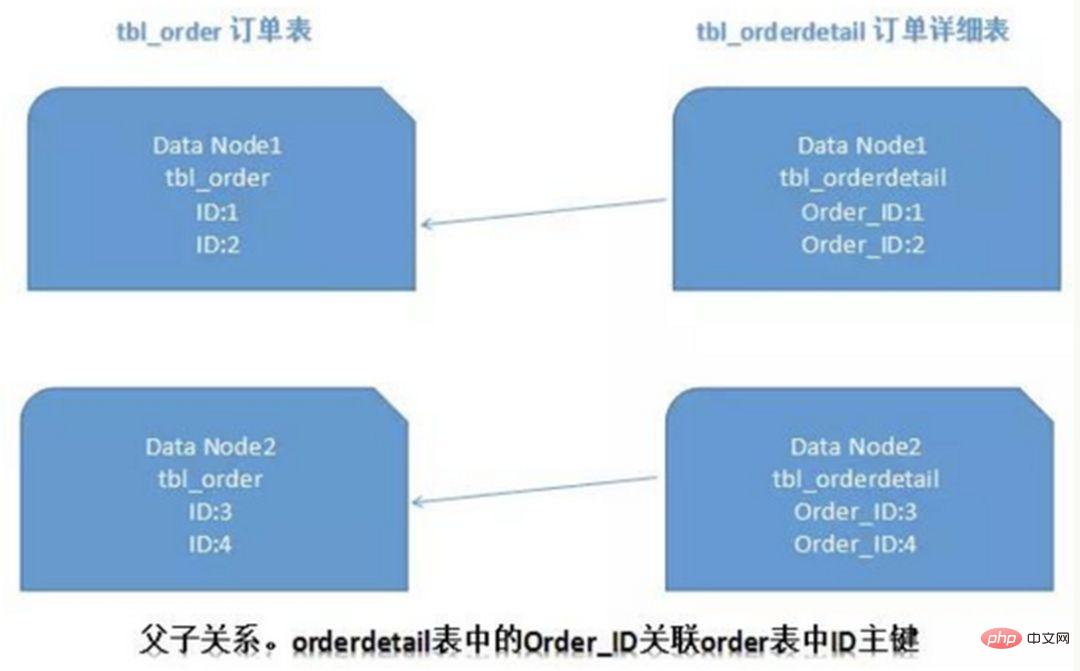
In this way, the order order table and orderdetail order details table on Data Node1 can be processed through orderId The local correlation query is performed, and the same is true on Data Node2.
3. Cross-node paging, sorting, and function issues
When querying across multiple nodes and multiple databases, limit paging and order by sorting will occur. And other issues. Paging needs to be sorted according to the specified field. When the sorting field is a sharding field, it is easier to locate the specified shard through the sharding rules; when the sorting field is not a sharding field, it becomes more complicated. The data needs to be sorted and returned in different shard nodes first, and then the result sets returned by different shards are summarized and sorted again, and finally returned to the user. As shown in the figure:
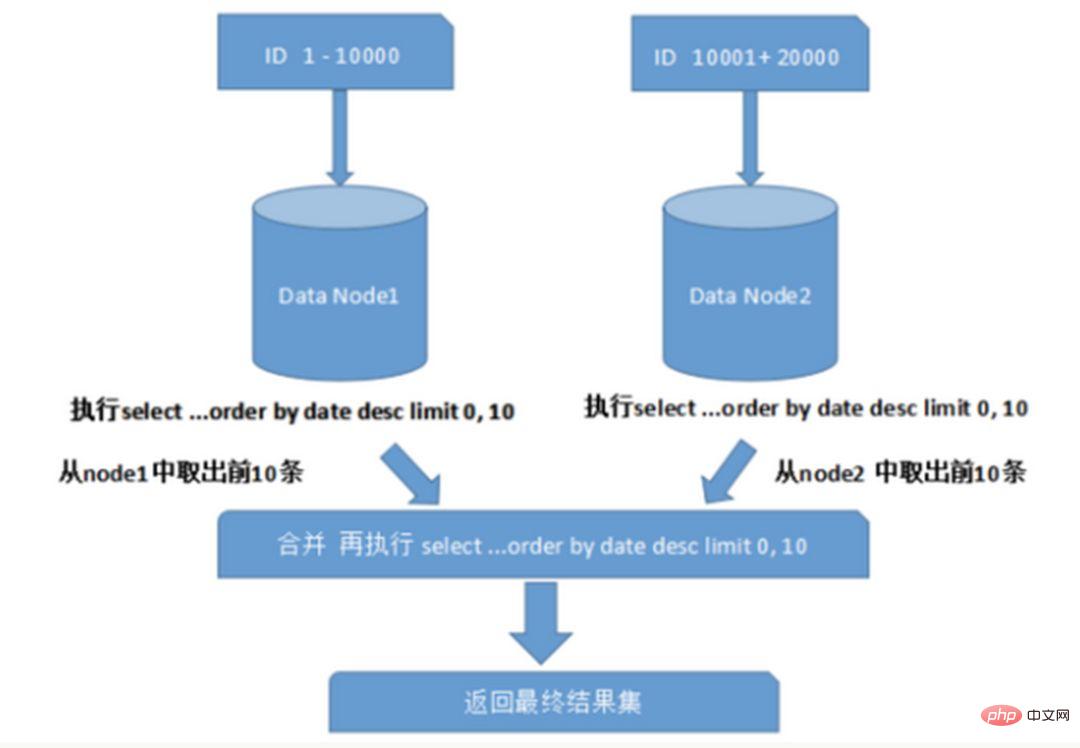
The above figure only takes the data from the first page, which does not have a great impact on performance. However, if the number of pages obtained is large, the situation becomes much more complicated, because the data in each shard node may be random. For the accuracy of sorting, the first N pages of data of all nodes need to be sorted and merged. Finally, Then perform the overall sorting. Such an operation consumes CPU and memory resources, so the larger the number of pages, the worse the system performance will be.
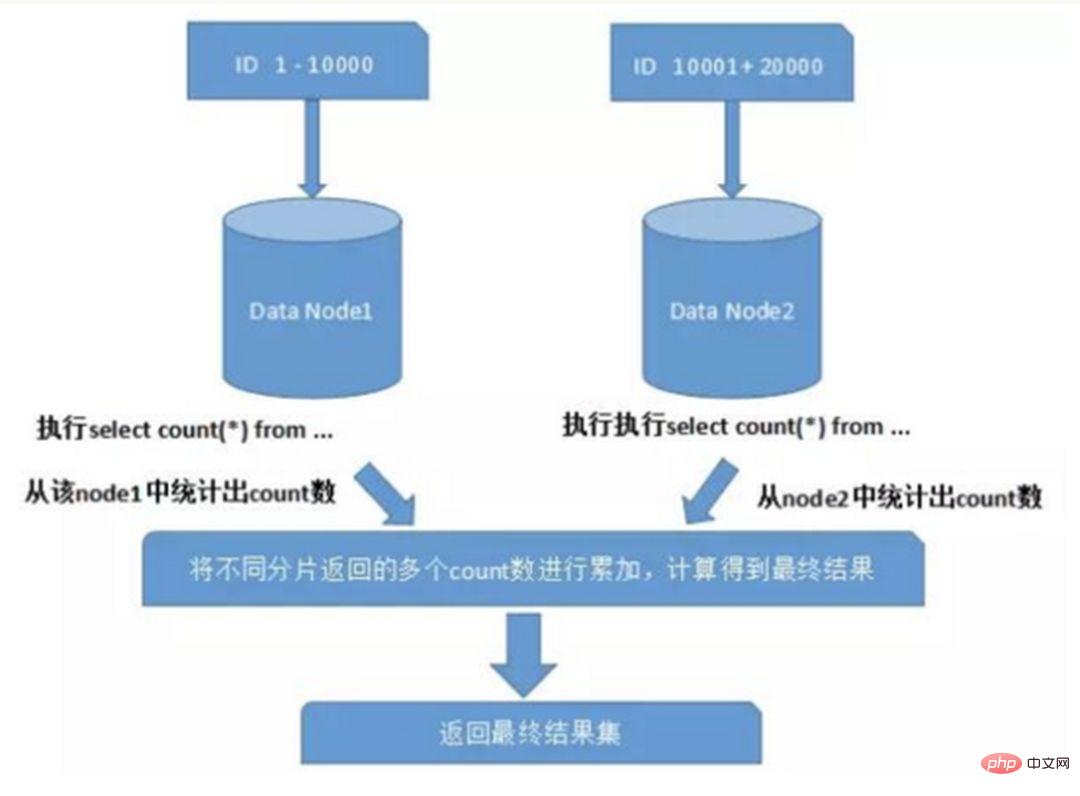
When using functions such as Max, Min, Sum, and Count for calculation, you also need to execute the corresponding function on each shard first, and then summarize the result sets of each shard and calculate again. , and finally return the result. as the picture shows:
4. Global primary key avoidance problem
In the sub-database In a table environment, since the data in the table exists in different databases at the same time, the usual auto-increment of the primary key value will be useless, and the self-generated ID of a partitioned database cannot be guaranteed to be globally unique. Therefore, it is necessary to design the global primary key separately to avoid the duplication of primary keys across databases. There are some common primary key generation strategies:
1) UUID
The UUID standard form contains 32 hexadecimal digits, divided into 5 segments , 36 characters in the form of 8-4-4-4-12, for example: 550e8400-e29b-41d4-a716-446655440000
UUID is the primary key, which is the simplest solution, locally generated, high performance, no Network time consuming. But the shortcomings are also obvious. Because UUID is very long, it will take up a lot of storage space. In addition, there will be performance problems when creating an index as a primary key and querying based on the index. Under InnoDB, the disorder of UUID will cause frequent changes in data location. , resulting in paging.
2) Combined with the database to maintain the primary key ID table
Create a sequence table in the database:
CREATE TABLE `sequence` ( `id` bigint(20) unsigned NOT NULL auto_increment, `stub` char(1) NOT NULL default '', PRIMARY KEY (`id`), UNIQUE KEY `stub` (`stub`) ) ENGINE=MyISAM;
Stub field is set to Unique index, the same stub value has only one record in the sequence table, and global IDs can be generated for multiple tables at the same time. The contents of the sequence table are as follows:
+-------------------+------+ | id | stub | +-------------------+------+ | 72157623227190423 | a | +-------------------+------+
Use the MyISAM storage engine instead of InnoDB for higher performance. MyISAM uses table-level locks, and reads and writes to the table are serial, so there is no need to worry about reading the same ID value twice during concurrency.
When a globally unique 64-bit ID is required, execute:
REPLACE INTO sequence (stub) VALUES ('a'); SELECT LAST_INSERT_ID();
These two statements are at the Connection level, select lastinsertid() must be under the same database connection as replace into to get the just The new ID inserted.
The advantage of using replace into instead of insert into is that it avoids the number of table rows being too large and does not require regular cleaning.
This solution is relatively simple, but its shortcomings are also obvious: there is a single point of problem and it is strongly dependent on the DB. When the DB is abnormal, the entire system is unavailable. Configuring master-slave can increase availability, but when the master database fails and master-slave switches, data consistency is difficult to guarantee under special circumstances. In addition, the performance bottleneck is limited to the read and write performance of a single MySQL.
A primary key generation strategy used by the flickr team is similar to the sequence table solution above, but better solves the problem of single points and performance bottlenecks.
The overall idea of this solution is to establish more than 2 global ID generating servers, deploy only one database on each server, and each database has a sequence table to record the current global ID. The step size of ID growth in the table is the number of libraries, and the starting values are staggered in order, so that the generation of IDs can be hashed to each database. As shown below:
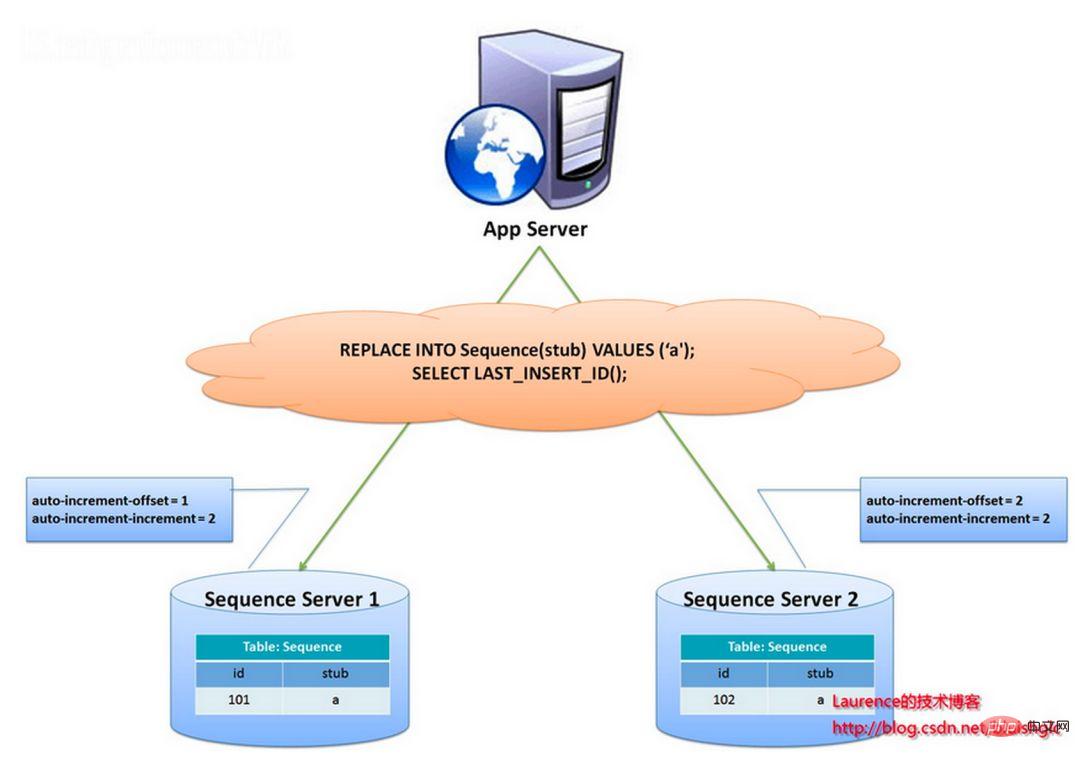
The ID is generated by two database servers and different auto_increment values are set. The starting value of the first sequence is 1, and each step increases by 2. The starting value of the other sequence is 2, and each step increases by 2. As a result, the IDs generated by the first station are all odd numbers (1, 3, 5, 7...), and the IDs generated by the second station are all even numbers (2, 4, 6, 8...).
This solution evenly distributes the pressure of generating IDs on the two machines. It also provides system fault tolerance. If an error occurs on the first machine, it can automatically switch to the second machine to obtain the ID. However, it has the following disadvantages: when adding machines to the system, horizontal expansion is more complicated; each time the ID is obtained, the DB must be read and written. The pressure on the DB is still very high, and the performance can only be improved by relying on heap machines.
You can continue to optimize based on flickr's solution, use batch methods to reduce the writing pressure of the database, obtain a range of ID number segments each time, and then go to the database to obtain them after use, which can greatly reduce the pressure on the database. As shown in the figure below:
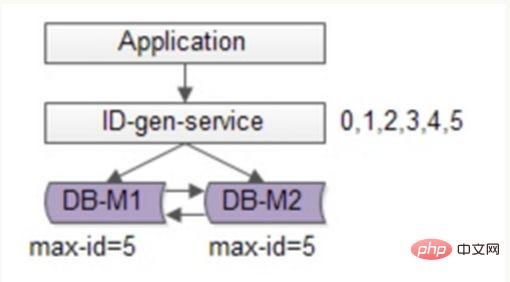
Still use two DBs to ensure availability. Only the current maximum ID is stored in the database. The ID generation service pulls 6 IDs in batches each time, and first changes the maxid to 5. When the application accesses the ID generation service, it does not need to access the database, and IDs 0~5 are sequentially dispatched from the number segment cache. After these IDs are issued, change the maxid to 11, and IDs 6~11 can be distributed next time. As a result, the pressure on the database is reduced to 1/6 of the original.
3) Snowflake distributed self-increasing ID algorithm
Twitter’s snowflake algorithm solves the need for distributed systems to generate global IDs, generating 64 Long type number of digits, components:
The first digit is unused
The next 41 digits are millisecond-level time, and the length of 41 digits can represent 69 years of time
5-digit datacenterId, 5-digit workerId. The 10-bit length supports the deployment of up to 1024 nodes
The last 12 bits are counts within milliseconds, and the 12-bit counting sequence number supports each node generating 4096 ID sequences per millisecond
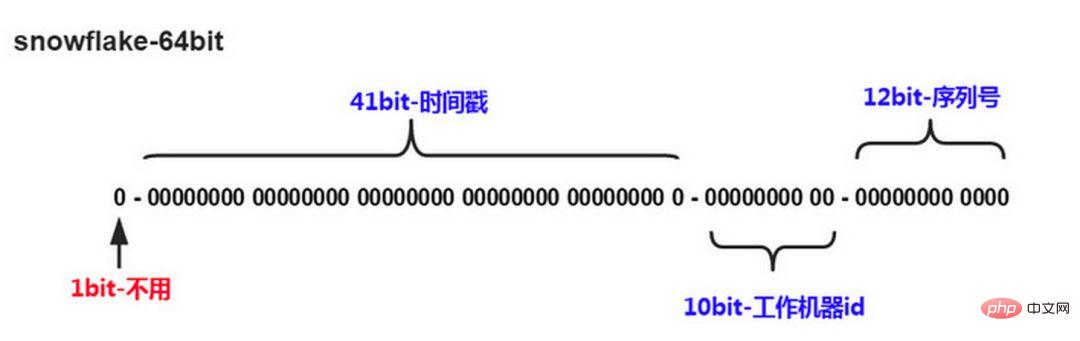
The advantage of this is: the number of milliseconds is at a high level, and the generated IDs generally increase according to the time trend; it does not rely on third-party systems, and has high stability and efficiency. In theory The upper QPS is about 409.6w/s (1000*2^12), and there will be no ID collisions in the entire distributed system; bits can be flexibly allocated according to its own business.
The disadvantage is that it relies heavily on the machine clock. If the clock is set back, it may result in duplicate ID generation.
To sum up
Combining the database and snowflake’s unique ID solution, you can refer to the industry’s more mature solution: Leaf - Meituan-Dianping distributed ID generation system, and takes into account issues such as high availability, disaster recovery, and distributed clocking.
5. Data migration and expansion issues
When the business develops rapidly and faces performance and storage bottlenecks, sharding design will be considered , at this time, it is inevitable to consider the issue of historical data migration. The general approach is to first read the historical data, and then write the data to each shard node according to the specified sharding rules. In addition, capacity planning needs to be carried out based on the current data volume and QPS, as well as the speed of business development, to calculate the approximate number of shards required (it is generally recommended that the data volume of a single table on a single shard does not exceed 1000W)
If Using numerical range sharding, you only need to add nodes to expand the capacity, and there is no need to migrate the sharded data. If numerical modulo sharding is used, it will be relatively troublesome to consider later expansion issues.
3. When to consider segmentation
The following describes when to consider data segmentation.
1. Try not to split it if possible
Not all tables need to be split, it mainly depends on the growth of the data speed. Segmentation will increase the complexity of the business to a certain extent. In addition to carrying data storage and query, the database is also one of its important tasks to assist the business in better realizing its needs.
Don’t use the big trick of sub-database and sub-table unless absolutely necessary to avoid "over-design" and "premature optimization". Before splitting databases and tables, don’t split just for the sake of splitting. Try your best to do what you can first, such as upgrading hardware, upgrading network, separating read and write, index optimization, etc. When the amount of data reaches the bottleneck of a single table, consider sharding databases and tables.
2. The amount of data is too large and normal operation and maintenance affects business access
The operation and maintenance mentioned here refers to:
1) For database backup, if a single table is too large, a large amount of disk IO and network IO will be required during backup. For example, if 1T of data is transmitted over the network and occupies 50MB, it will take 20,000 seconds to complete. The risk of the entire process is relatively high.
2) When DDL is modified on a large table, MySQL will lock For the entire table, this time will be very long. During this period, the business cannot access this table, which has a great impact. If you use pt-online-schema-change, triggers and shadow tables will be created during use, which also takes a long time. During this operation, it is counted as risk time. Splitting the data table and reducing the total amount can help reduce this risk.
3)大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
3、随着业务发展,需要对某些字段垂直拆分
举个例子,假如项目一开始设计的用户表如下:
id bigint #用户的IDname varchar #用户的名字last_login_time datetime #最近登录时间personal_info text #私人信息..... #其他信息字段
在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 lastloginname 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personalinfo 是不变的或很少更新的,此时在业务角度,就要将 lastlogintime 拆分出去,新建一个 usertime 表。
personalinfo 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 userext 表了。
4、数据量快速增长
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
5、安全性和可用性
鸡蛋不要放在一个篮子里。在业务层面上垂直切分,将不相关的业务的数据库分隔,因为每个业务的数据量、访问量都不同,不能因为一个业务把数据库搞挂而牵连到其他业务。利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
四. 案例分析
1、用户中心业务场景
用户中心是一个非常常见的业务,主要提供用户注册、登录、查询/修改等功能,其核心表为:
User(uid, login_name, passwd, sex, age, nickname) uid为用户ID, 主键login_name, passwd, sex, age, nickname, 用户属性
任何脱离业务的架构设计都是耍流氓,在进行分库分表前,需要对业务场景需求进行梳理:
用户侧:前台访问,访问量较大,需要保证高可用和高一致性。主要有两类需求:
1. User login: Query user information through login_name/phone/email, 1% of requests belong to this type 2. User information query: After logging in, query user information through uid, 99% of requests belong to this typeOperation side: Backend access, supports operational needs, and performs paging queries based on age, gender, login time, registration time, etc. It is an internal system with low access volume and low requirements on availability and consistency.
2. Horizontal segmentation method
#When the amount of data becomes larger and larger, the database needs to be horizontally segmented, as described above The segmentation methods include "based on numerical range" and "based on numerical modulo".
"According to the numerical range": Using the primary key uid as the basis for division, the data is horizontally divided into multiple databases according to the range of uid. For example: user-db1 stores data with uid ranges from 0 to 1000w, and user-db2 stores data with uid ranges from 1000w to 2000wuid.
The advantage is: expansion is simple. If the capacity is not enough, just add a new db.
The shortcoming is: The request volume is uneven. Generally, newly registered users will be more active, so the new user-db2 will have a higher load than user-db1, resulting in low server utilization. Balance
"Modulo based on numerical value": The primary key uid is also used as the basis for division, and the data is split horizontally into multiple databases based on the modulo value of uid. For example: user-db1 stores uid data modulo 1, user-db2 stores uid data modulo 0.
The advantages are: the data volume and request volume are evenly distributed
The disadvantage is: expansion is troublesome. When the capacity is not enough, add a new db. Requires rehash. Smooth migration of data needs to be considered.
3. Non-uid query method
After horizontal segmentation, the demand for query by uid can be well satisfied and can be directly Route to a specific database. For queries based on non-uid, such as login_name, it is not known which library should be accessed. In this case, all libraries need to be traversed, and the performance will be reduced a lot.
For the user side, the solution of "establishing a mapping relationship from non-uid attributes to uid" can be adopted; for the operation side, the solution of "separating the front-end and back-end" can be adopted.
3.1. Establish a mapping relationship from non-uid attributes to uid
1) Mapping relationship
For example: loginname cannot be directly Locate the database, you can establish the mapping relationship login_name→uid, and use an index table or cache to store it. When accessing loginname, first query the uid corresponding to login_name through the mapping table, and then locate the specific library through the uid.
The mapping table has only two columns and can carry a lot of data. When the amount of data is too large, the mapping table can also be split horizontally. This type of kv format index structure can use cache to optimize query performance, and the mapping relationship will not change frequently, and the cache hit rate will be very high.
2) Gene method
Sub-library gene: If the library is divided into 8 libraries through uid, it is routed using uid%8. At this time, it is determined by the last 3 bits of uid. Determine which library this row of User data falls on, then these 3 bits can be regarded as sub-library genes.
The above mapping relationship method requires additional storage of the mapping table. When querying by non-uid fields, an additional database or cache access is required. If you want to eliminate redundant storage and queries, you can use the f function to take the loginname gene as the sub-library gene of uid. When generating uid, refer to the distributed unique ID generation scheme described above, plus the last three bit values = f (loginname). When querying loginname, you only need to calculate the value of f(loginname)%8 to locate the specific library. However, this requires capacity planning in advance, estimating how many databases the data volume will need to be divided into in the next few years, and reserving a certain number of bits of database genes.
For the user side, the main requirement is to Single-line queries are mainly used. It is necessary to establish a mapping relationship from login_name/phone/email to uid, which can solve the query problem of these fields. As for the operation side, there are many queries with batch paging and various conditions. Such queries require a large amount of calculation, return a large amount of data, and consume high performance of the database. At this time, if the same batch of services or databases are shared with the user side, a small number of background requests may occupy a large amount of database resources, resulting in user-side access performance degradation or timeout. This type of business is best to adopt the "separation of front-end and back-end" solution. The back-end business on the operation side extracts independent services and DBs to solve the coupling with the front-end business system. Since the operation side does not have high requirements for availability and consistency, it is not necessary to access the real-time library. Instead, it can asynchronously synchronize data to the operation library through binlog for access. When the amount of data is large, you can also use ES search engine or Hive to meet the complex query methods in the background.
5. Support database and table sharding middleware
Standing on the shoulders of giants can save a lot of effort. Currently, There are already some relatively mature open source solutions for sharding databases and tables:sharding-jdbc (Dangdang) TSharding (Mogu Street) Atlas (Qihoo 360) Cobar (Alibaba) MyCAT (based on Cobar) Oceanus (58.com ) Vitess (Google)
The above is the detailed content of The database is divided into databases and tables. When? How to divide?. For more information, please follow other related articles on the PHP Chinese website!