
Home >Common Problem >Must-ask questions in interviews: What exactly happens from entering the URL to page display?
Must-ask questions in interviews: What exactly happens from entering the URL to page display?
- Java学习指南forward
- 2023-07-26 17:01:372345browse
I was quite confused when I first started writing this article, because you can find a lot of information by searching online for "what happens from entering the URL to the page display". Moreover, this interview question is basically a required question. During the interview in February, although I knew what happened in the process, when the interviewer continued to ask questions step by step, many details were not clear.
#The purpose of this article is to summarize and expand knowledge through what happens after entering the url. So the article may be complicated.
The overall process is as follows:
1. Enter the address
When we start in the browser When you enter a URL, the browser is actually already intelligently matching possible URLs. It will find the URL that may correspond to the entered string from history records, bookmarks, etc., and then give intelligent prompts so that you can fill in the URL. Full url address. For Google's Chrome browser, it will even display the web page directly from the cache. That is to say, the page will come out before you press enter.
2. The browser searches for the IP address of the domain name
1. Once the request is initiated, the first thing the browser does is to resolve the domain name. Generally speaking, browsing The server will first check the hosts file on the local hard disk to see if there are any rules corresponding to this domain name. If so, it will directly use the IP address in the hosts file.
2. If the corresponding IP address cannot be found in the local hosts file, the browser will send a DNS request to the local DNS server. Local DNS servers are generally provided by your network access server provider, such as China Telecom and China Mobile.
3. After the DNS request for the URL you entered reaches the local DNS server, the local DNS server will first query its cache record. If there is this record in the cache, you can directly Returning results, this process is a recursive query. If not, the local DNS server will also query the DNS root server.
4. The root DNS server does not record the specific correspondence between domain names and IP addresses. Instead, it tells the local DNS server that you can go to the domain server to continue querying and give the domain server. the address of. This process is an iterative process.
5. The local DNS server continues to make requests to the domain server. In this example, the request object is the .com domain server. After the .com domain server receives the request, it will not directly return the correspondence between the domain name and the IP address. Instead, it will tell the local DNS server the address of the resolution server for your domain name.
6. Finally, the local DNS server sends a request to the domain name resolution server, and then receives a correspondence between the domain name and the IP address. The local DNS server not only returns the IP address to the user's computer, but also Save this correspondence in the cache so that the next time another user queries, the results can be returned directly to speed up network access.
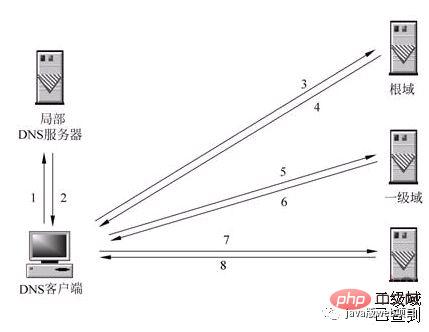
The picture below explains this process perfectly:

Knowledge expansion:
1) What is DNS?
DNS (Domain Name System, domain name system), a distributed mapping of domain names and IP addresses on the Internet The database allows users to access the Internet more conveniently without having to remember IP strings that can be directly read by machines. The process of finally obtaining the IP address corresponding to the host name through the host name is called domain name resolution (or host name resolution).
Generally speaking, we are more accustomed to remembering the name of a website, such as www.baidu.com, rather than remembering its IP address, such as: 167.23.10.2. And computers are better at remembering the IP address of a website, rather than links like www.baidu.com. Because DNS is equivalent to a phone book. For example, if you are looking for the domain name www.baidu.com, then I look through my phone book and I will know, oh, its phone number (IP) is 167.23.10.2.
2) Two ways of DNS query: recursive query and iterative query
1. Recursive analysis
When the local DNS server itself cannot answer the client's DNS query, it needs to query other DNS servers. There are two methods at this time. The one shown in the figure is the recursive method. The local DNS server is responsible for querying other DNS servers. Generally, it first queries the root domain server of the domain name, and then the root domain name server queries downwards one level at a time. The final query result is returned to the local DNS server, and then the local DNS server returns it to the client.

2. Iterative analysis
When the local DNS server itself cannot answer the client's DNS query, it can also be resolved through iterative query, as shown in the figure. The local DNS server does not query other DNS servers by itself, but returns the IP addresses of other DNS servers that can resolve the domain name to the client DNS program. The client DNS program then continues to query these DNS servers until the query results are obtained. until. In other words, iterative analysis only helps you find relevant servers, but will not help you check them. For example: the server IP address of baidu.com is here 192.168.4.5. You can check it yourself. I am very busy, so I can only help you here.
3) How the DNS domain namespace is organized
We are here As mentioned earlier, the root DNS server and the domain DNS server are how the DNS domain name space is organized. The five categories used to describe DNS domain names in the namespace are described in the table below, along with examples of each name type.
#4)DNS Load Balancing
When a website has enough users, if the resources requested each time are located on the same machine, then this The machine may pop off at any time. The solution is to use DNS load balancing technology. Its principle is to configure multiple IP addresses for the same host name in the DNS server. When responding to DNS queries, the DNS server will respond to each query with the IP address recorded by the host in the DNS file. Return different parsing results in order, guide client access to different machines, so that different clients access different servers, thereby achieving load balancing. For example, according to the load of each machine, the distance between the machine and the user can be Geographical distance, etc.
3. The browser sends an HTTP request to the web serverAfter getting the IP address corresponding to the domain name, the browser will send a random port (102488b3a3cd3b7bcbdb332bed0b745295e2 Build render tree-> Layout render tree-> Draw render tree
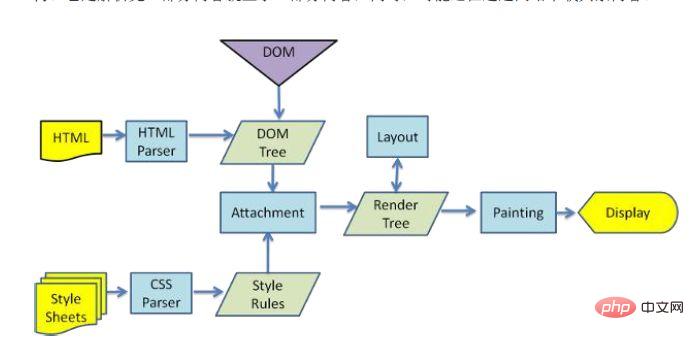
When the browser parses the html file, it will load it "from top to bottom" and perform parsing and rendering during the loading process. During the parsing process, if there is a request for external resources, such as pictures, external link CSS, iconfont, etc., the request process is asynchronous and will not affect the loading of the HTML document.
During the parsing process, the browser will first parse the HTML file to build the DOM tree, and then parse the CSS file to build the rendering tree. After the rendering tree is built, the browser begins to lay out the rendering tree and which is drawn to the screen. This process is relatively complex and involves two concepts: reflow and repaint.
Each element in the DOM node exists in the form of a box model, which requires the browser to calculate its position and size. This process is called relow; when the box model After the position, size and other attributes, such as color, font, etc. are determined, the browser begins to draw the content. This process is called repaint.
The page will inevitably experience reflow and repain when it is first loaded. The reflow and repain process is very performance-consuming, especially on mobile devices. It will destroy the user experience and sometimes cause the page to freeze. So we should reduce reflow and repain as little as possible.
When a js file is encountered during document loading, the HTML document will hang rendering (loading parsing rendering Synchronization) thread must not only wait for the js file in the document to be loaded, but also wait for the parsing execution to be completed before the rendering thread of the html document can be resumed. Because JS may modify the DOM, the most classic document.write, this means that the subsequent download of all resources may not be necessary before JS execution is completed. This is the fundamental reason why js blocks subsequent resource downloads. So I understand that in the usual code, js is placed at the end of the html document.
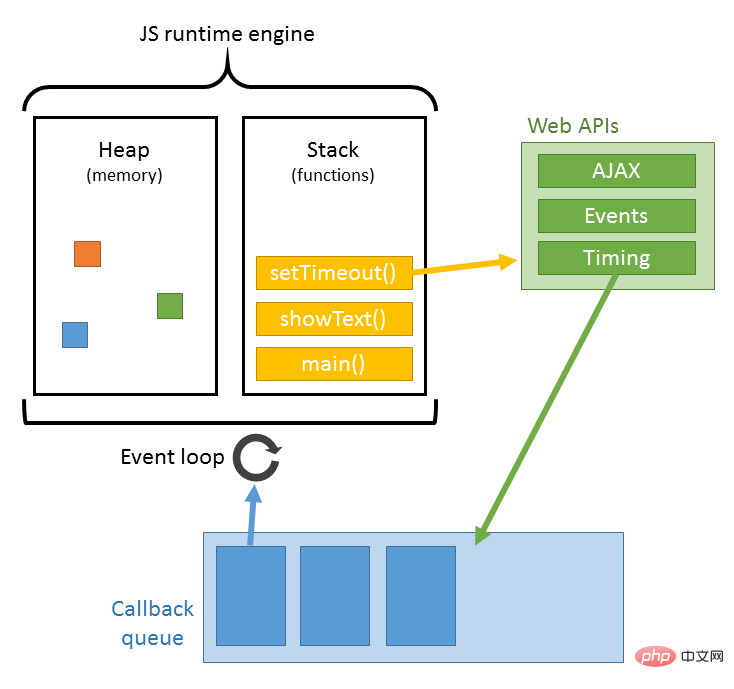
The parsing of JS is completed by the JS parsing engine in the browser, such as Google's V8. JS runs in a single thread, which means that it can only do one thing at the same time. All tasks need to be queued. The previous task ends before the next one can start. However, there are some tasks that are time-consuming, such as IO reading and writing, etc., so a mechanism is needed to execute the later tasks first, which are: synchronous tasks (synchronous) and asynchronous tasks (asynchronous).
The execution mechanism of JS can be regarded as a main thread plus a task queue. Synchronous tasks are tasks executed on the main thread, and asynchronous tasks are tasks placed in the task queue. All synchronous tasks are executed on the main thread, forming an execution stack; an asynchronous task will place an event in the task queue when it has the running result; when the script is running, it will first run the execution stack in sequence, and then extract the event from the task queue and run For tasks in the task queue, this process is repeated continuously, so it is also called an event loop. For the specific process, you can read my article: click here
9. The browser sends a request to obtain resources embedded in HTML (such as images, audio, video, CSS, JS, etc.)
In fact, this step can be paralleled in step 8. When the browser displays the HTML, it notices tags that need to get the content of other addresses. At this point, the browser will send a fetch request to retrieve the files. For example, I want to get external pictures, CSS, JS files, etc., similar to the following link:
Picture: http://static.ak.fbcdn.net/rsrc.php/z12E0 /hash/8q2anwu7.gif
CSS style sheet: http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
JavaScript file: http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
These addresses must be experienced A process similar to HTML reading. So the browser will look up these domain names in DNS, send requests, redirect, etc...
Unlike dynamic pages, static files will allow the browser to cache them. Some files may not need to communicate with the server, but can be read directly from the cache, or can be placed in a CDN
At this point, the process from inputting the URL to page display is finally completed. . Of course, the writing style is limited and there are any errors. You are welcome to point out that this article refers to many articles, but I can’t remember the links to many articles, so I only list the following three reference links.
The above is the detailed content of Must-ask questions in interviews: What exactly happens from entering the URL to page display?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Real interview question: Please talk about the CAS mechanism in concurrency
- The interviewer asks you: Do you know what an ABA problem is?
- A question asked in almost all Java interviews: talk about the difference between ArrayList and LinkedList
- Interviewer: How much do you know about high concurrency? Me: emmm...