
 Operation and MaintenanceLinux Operation and MaintenanceConfiguring Linux systems to support distributed database development
Operation and MaintenanceLinux Operation and MaintenanceConfiguring Linux systems to support distributed database development
Configuring Linux systems to support distributed database development
Introduction:
With the rapid development of the Internet, the amount of data has increased dramatically, and the requirements for database performance and scalability are also getting higher and higher. Distributed databases emerged as a solution to this challenge. This article will introduce how to configure a distributed database environment under Linux system to support distributed database development.
1. Install the Linux system
First, we need to install a Linux operating system. Common Linux distributions include Ubuntu, CentOS, Debian, etc., among which Ubuntu is a very popular choice. You can download the image file from the official website and install it according to the official documentation.
2. Install and configure the database management system
- First install a database management system, such as MySQL or PostgreSQL. Taking Ubuntu as an example, you can install MySQL through the following command:
sudo apt-get update sudo apt-get install mysql-server
- After the installation is complete, start the database service and set it to start automatically at boot:
sudo systemctl start mysql sudo systemctl enable mysql
- Configure the parameters of the database management system to adapt to the distributed environment. Open the MySQL configuration file
/etc/mysql/mysql.conf.d/mysqld.cnfand modify the following parameters:
bind-address = 0.0.0.0
This parameter will allow other computers to connect to the The database management system.
- Reload the MySQL configuration file to make the changes take effect:
sudo systemctl reload mysql
3. Set the master node and slave node
In a distributed database, there is usually a master node There are two roles: node and slave node. The master node is used to handle write operations and main queries of data, while the slave node is used to replicate the data of the master node and handle read operation requests.
- First, set up the master node. Log in to the MySQL console:
mysql -u root -p
Create a new database user and grant it read and write permissions on the master node:
CREATE USER 'user'@'%' IDENTIFIED BY 'password'; GRANT ALL PRIVILEGES ON *.* TO 'user'@'%' WITH GRANT OPTION; FLUSH PRIVILEGES;
- Next, set up the slave node . Perform the same operations on the slave node as on the master node, create a user the same as the master node, and set the user's permissions to read-only permissions:
CREATE USER 'user'@'%' IDENTIFIED BY 'password'; GRANT SELECT, SHOW VIEW ON *.* TO 'user'@'%'; FLUSH PRIVILEGES;
4. Configure and test replication
In a distributed database, the slave node achieves data consistency by replicating the data of the master node. Here's how to configure and test replication.
- On the master node, edit the MySQL configuration file
/etc/mysql/mysql.conf.d/mysqld.cnfand add the following parameters:
server-id = 1 log_bin = /var/log/mysql/binlog
These parameters will enable binary logging, which is used to store records of data changes on the master node.
- Restart the MySQL service on the master node:
sudo systemctl restart mysql
- On the slave node, edit the MySQL configuration file
/etc/mysql/mysql.conf .d/mysqld.cnf, add the following parameters:
server-id = 2 relay-log = /var/log/mysql/relaylog
These parameters will enable the slave node to receive and replicate data changes from the master node.
- Restart the MySQL service on the slave node:
sudo systemctl restart mysql
- On the master node, use the following command to create a test database and insert some data:
CREATE DATABASE test;
USE test;
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100)
);
INSERT INTO employees VALUES(1, 'John');
INSERT INTO employees VALUES(2, 'Jane');- On the slave node, you can check whether the data has been copied successfully by running the following command:
USE test; SELECT * FROM employees;
If the slave node shows the same data as the master node, it means Copied successfully.
Summary:
Through the guidance of this article, we have successfully configured a Linux system to support distributed database development. During this configuration process, we installed the database management system, set up the master node and slave nodes, and tested the data replication function. Distributed databases can help us cope with the challenges of massive data and improve the performance and scalability of database systems.
Reference materials:
- MySQL official documentation: https://dev.mysql.com/doc/
- PostgreSQL official documentation: https://www. postgresql.org/docs/
The above is the detailed content of Configuring Linux systems to support distributed database development. For more information, please follow other related articles on the PHP Chinese website!

 Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM
Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM译者 | 李睿审校 | 孙淑娟随着Python越来越受欢迎,其局限性也越来越明显。一方面,编写Python应用程序并将其分发给没有安装Python的人员可能非常困难。解决这一问题的最常见方法是将程序与其所有支持库和文件以及Python运行时打包在一起。有一些工具可以做到这一点,例如PyInstaller,但它们需要大量的缓存才能正常工作。更重要的是,通常可以从生成的包中提取Python程序的源代码。在某些情况下,这会破坏交易。第三方项目Nuitka提供了一个激进的解决方案。它将Python程序编
 ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PM
ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PMChatGPT 目前彻底改变了开发代码的方式,然而,大多数软件开发人员和数据专家仍然没有使用 ChatGPT 来改进和简化他们的工作。这就是为什么我在这里概述 5 个不同的功能,以提高我们的日常工作速度和质量。我们可以在日常工作中使用它们。现在,我们一起来了解一下吧。注意:切勿在 ChatGPT 中使用关键代码或信息。01.生成项目代码的框架从头开始构建新项目时,ChatGPT 是我的秘密武器。只需几个提示,它就可以生成我需要的代码框架,包括我选择的技术、框架和版本。它不仅为我节省了至少一个小时
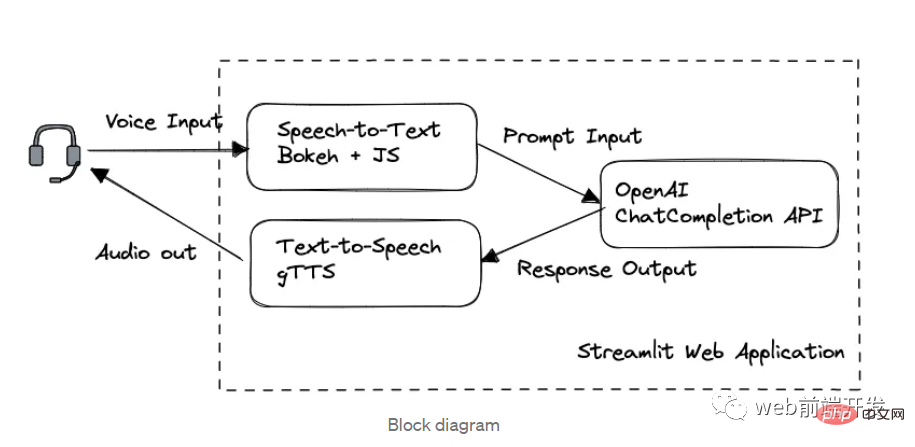 我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM
我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM今天这篇文章的重点是使用 ChatGPT API 创建私人语音 Chatbot Web 应用程序。目的是探索和发现人工智能的更多潜在用例和商业机会。我将逐步指导您完成开发过程,以确保您理解并可以复制自己的过程。为什么需要不是每个人都欢迎基于打字的服务,想象一下仍在学习写作技巧的孩子或无法在屏幕上正确看到单词的老年人。基于语音的 AI Chatbot 是解决这个问题的方法,就像它如何帮助我的孩子要求他的语音 Chatbot 给他读睡前故事一样。鉴于现有可用的助手选项,例如,苹果的 Siri 和亚马
 解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM
解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM测试时自适应(Test-TimeAdaptation,TTA)方法在测试阶段指导模型进行快速无监督/自监督学习,是当前用于提升深度模型分布外泛化能力的一种强有效工具。然而在动态开放场景中,稳定性不足仍是现有TTA方法的一大短板,严重阻碍了其实际部署。为此,来自华南理工大学、腾讯AILab及新加坡国立大学的研究团队,从统一的角度对现有TTA方法在动态场景下不稳定原因进行分析,指出依赖于Batch的归一化层是导致不稳定的关键原因之一,另外测试数据流中某些具有噪声/大规模梯度的样本
 摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM
摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM哈喽,大家好。之前给大家分享过摔倒识别、打架识别,今天以摔倒识别为例,我们看看能不能完全交给ChatGPT来做。让ChatGPT来做这件事,最核心的是如何向ChatGPT提问,把问题一股脑的直接丢给ChatGPT,如:用 Python 写个摔倒检测代码 是不可取的, 而是要像挤牙膏一样,一点一点引导ChatGPT得到准确的答案,从而才能真正让ChatGPT提高我们解决问题的效率。今天分享的摔倒识别案例,与ChatGPT对话的思路清晰,代码可用度高,按照GPT返回的结果完全可以开
 17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM
17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM自 2020 年以来,内容开发领域已经感受到人工智能工具的存在。1.Jasper AI网址:https://www.jasper.ai在可用的 AI 文案写作工具中,Jasper 作为那些寻求通过内容生成赚钱的人来讲,它是经济实惠且高效的选择之一。该工具精通短格式和长格式内容均能完成。Jasper 拥有一系列功能,包括无需切换到模板即可快速生成内容的命令、用于创建文章的高效长格式编辑器,以及包含有助于创建各种类型内容的向导的内容工作流,例如,博客文章、销售文案和重写。Jasper Chat 是该
 为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM
为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM1970年,机器人专家森政弘(MasahiroMori)首次描述了「恐怖谷」的影响,这一概念对机器人领域产生了巨大影响。「恐怖谷」效应描述了当人类看到类似人类的物体,特别是机器人时所表现出的积极和消极反应。恐怖谷效应理论认为,机器人的外观和动作越像人,我们对它的同理心就越强。然而,在某些时候,机器人或虚拟人物变得过于逼真,但又不那么像人时,我们大脑的视觉处理系统就会被混淆。最终,我们会深深地陷入一种对机器人非常消极的情绪状态里。森政弘的假设指出:由于机器人与人类在外表、动作上相似,所以人类亦会对
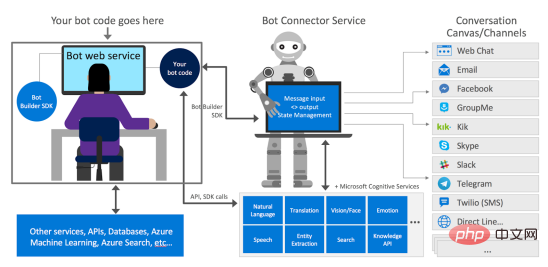 如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM
如何使用Azure Bot Services创建聊天机器人的分步说明Apr 11, 2023 pm 06:34 PM译者 | 李睿审校 | 孙淑娟信使、网络服务和其他软件都离不开机器人(bot)。而在软件开发和应用中,机器人是一种应用程序,旨在自动执行(或根据预设脚本执行)响应用户请求创建的操作。在本文中, NIX United公司的.NET开发人员Daniil Mikhov介绍了使用微软Azure Bot Services创建聊天机器人的一个例子。本文将对想要使用该服务开发聊天机器人的开发人员有所帮助。 为什么使用Azure Bot Services? 在Azure Bot Services上开发聊


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Atom editor mac version download
The most popular open source editor

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 English version
Recommended: Win version, supports code prompts!

