
 Backend DevelopmentPHP TutorialEvaluation of mall product recommendation algorithm developed using PHP
Backend DevelopmentPHP TutorialEvaluation of mall product recommendation algorithm developed using PHP
Evaluation of mall product recommendation algorithm developed using PHP
With the development of e-commerce, more and more mall websites have begun to use recommendation algorithms to provide personalized product recommendation services. As a commonly used server-side programming language, PHP is also widely used in the development of shopping mall websites. This article will introduce how to use the PHP developer mall product recommendation algorithm and evaluate it.
- Basic Principle of Product Recommendation Algorithm
The goal of the product recommendation algorithm is to provide users with product recommendations that may be of interest based on the user’s behavioral data. Commonly used recommendation algorithms include user-based collaborative filtering, content-based recommendation and hybrid recommendation. Among them, the user-based collaborative filtering algorithm is the most commonly used algorithm.
The user-based collaborative filtering algorithm analyzes user behavior data to find users with similar behaviors to the target user, and then recommends products to the target user based on the products purchased by these users. This process can be divided into two steps: calculating the similarity between users and recommending products to the target users.
- Use PHP to develop product recommendation algorithms
In PHP, you can use a database to store user behavior data, and use corresponding algorithms to implement product recommendation functions. The following is a simple PHP code example that demonstrates how to implement a user-based collaborative filtering algorithm.
First, you need to create a database table to store user behavior data. You can create a table named "user_behavior", containing fields such as "user ID", "item ID" and "behavior type".
CREATE TABLE user_behavior (
user_id INT,
item_id INT,
action_type VARCHAR(50)
);Then, PHP code needs to be written to calculate the similarity between users. Here is a simple example using cosine similarity to calculate similarity between users.
function cosine_similarity($user1, $user2) {
// 获取用户1和用户2的行为数据
$user1_behavior = get_user_behavior($user1);
$user2_behavior = get_user_behavior($user2);
// 计算用户1和用户2的行为向量
$vector1 = calculate_vector($user1_behavior);
$vector2 = calculate_vector($user2_behavior);
// 计算余弦相似度
$similarity = dot_product($vector1, $vector2) / (norm($vector1) * norm($vector2));
return $similarity;
}Finally, product recommendations need to be made for the target users based on their similarity. The following is a simple example that recommends products to target users based on similarity from high to low.
function recommend_items($target_user) {
// 获取与目标用户相似度最高的用户
$most_similar_user = get_most_similar_user($target_user);
// 获取与目标用户相似度最高的用户购买过的商品
$most_similar_user_items = get_user_items($most_similar_user);
// 过滤掉目标用户已经购买过的商品
$recommended_items = filter_items($most_similar_user_items, $target_user);
return $recommended_items;
}- Evaluation of product recommendation algorithm
In actual use, the product recommendation algorithm needs to be evaluated to ensure its accuracy and effectiveness. Common methods for evaluating product recommendation algorithms include offline evaluation and online evaluation.
Offline evaluation is an evaluation conducted on historical data. The performance of the algorithm is evaluated by calculating indicators such as accuracy, recall, and coverage between recommended results and actual user behavior.
Online evaluation is an evaluation conducted in a real-time environment to evaluate the effectiveness of the algorithm by comparing new recommendation results with actual user feedback.
In summary, this article introduces how to use the PHP Developer City product recommendation algorithm and evaluate it. By implementing a user-based collaborative filtering algorithm and applying it to the mall website, personalized product recommendation services can be provided, thereby improving the user's shopping experience.
The above is the detailed content of Evaluation of mall product recommendation algorithm developed using PHP. For more information, please follow other related articles on the PHP Chinese website!

 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM
基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM译者 | 朱先忠审校 | 孙淑娟在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我
 Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM
Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM译者 | 朱先忠审校 | 孙淑娟引言模型超参数(或模型设置)的优化可能是训练机器学习算法中最重要的一步,因为它可以找到最小化模型损失函数的最佳参数。这一步对于构建不易过拟合的泛化模型也是必不可少的。优化模型超参数的最著名技术是穷举网格搜索和随机网格搜索。在第一种方法中,搜索空间被定义为跨越每个模型超参数的域的网格。通过在网格的每个点上训练模型来获得最优超参数。尽管网格搜索非常容易实现,但它在计算上变得昂贵,尤其是当要优化的变量数量很大时。另一方面,随机网格搜索是一种更快的优化方法,可以提供更好的
 因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM
因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM导读:因果推断是数据科学的一个重要分支,在互联网和工业界的产品迭代、算法和激励策略的评估中都扮演者重要的角色,结合数据、实验或者统计计量模型来计算新的改变带来的收益,是决策制定的基础。然而,因果推断并不是一件简单的事情。首先,在日常生活中,人们常常把相关和因果混为一谈。相关往往代表着两个变量具有同时增长或者降低的趋势,但是因果意味着我们想要知道对一个变量施加改变的时候会发生什么样的结果,或者说我们期望得到反事实的结果,如果过去做了不一样的动作,未来是否会发生改变?然而难点在于,反事实的数据往往是
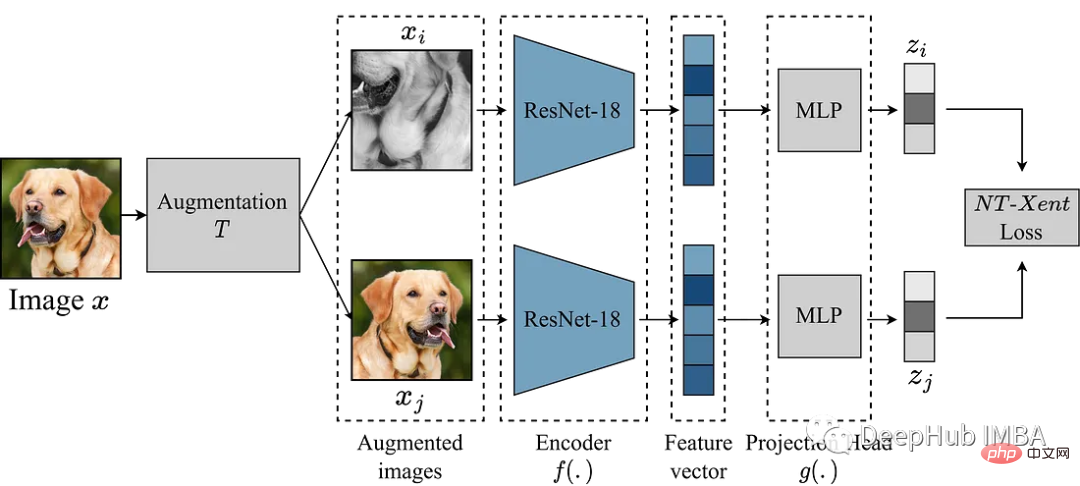 使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PM
使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PMSimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记
 盒马供应链算法实战Apr 10, 2023 pm 09:11 PM
盒马供应链算法实战Apr 10, 2023 pm 09:11 PM一、盒马供应链介绍1、盒马商业模式盒马是一个技术创新的公司,更是一个消费驱动的公司,回归消费者价值:买的到、买的好、买的方便、买的放心、买的开心。盒马包含盒马鲜生、X 会员店、盒马超云、盒马邻里等多种业务模式,其中最核心的商业模式是线上线下一体化,最快 30 分钟到家的 O2O(即盒马鲜生)模式。2、盒马经营品类介绍盒马精选全球品质商品,追求极致新鲜;结合品类特点和消费者购物体验预期,为不同品类选择最为高效的经营模式。盒马生鲜的销售占比达 60%~70%,是最核心的品类,该品类的特点是用户预期时
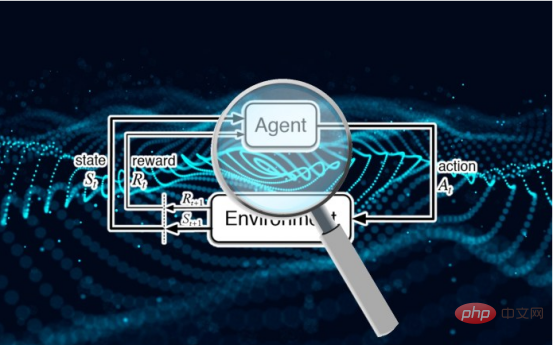 研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM
研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM译者 | 李睿 审校 | 孙淑娟随着机器学习成为人们每天都在使用的很多应用程序的一部分,人们越来越关注如何识别和解决机器学习模型的安全和隐私方面的威胁。 然而,不同机器学习范式面临的安全威胁各不相同,机器学习安全的某些领域仍未得到充分研究。尤其是强化学习算法的安全性近年来并未受到太多关注。 加拿大的麦吉尔大学、机器学习实验室(MILA)和滑铁卢大学的研究人员开展了一项新研究,主要侧重于深度强化学习算法的隐私威胁。研究人员提出了一个框架,用于测试强化学习模型对成员推理攻击的脆弱性。 研究
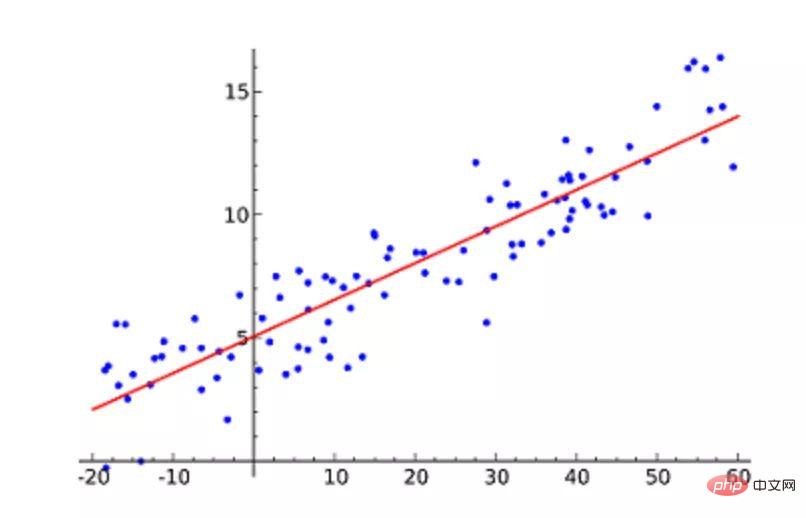 机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM
机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM1.线性回归线性回归(Linear Regression)可能是最流行的机器学习算法。线性回归就是要找一条直线,并且让这条直线尽可能地拟合散点图中的数据点。它试图通过将直线方程与该数据拟合来表示自变量(x 值)和数值结果(y 值)。然后就可以用这条线来预测未来的值!这种算法最常用的技术是最小二乘法(Least of squares)。这个方法计算出最佳拟合线,以使得与直线上每个数据点的垂直距离最小。总距离是所有数据点的垂直距离(绿线)的平方和。其思想是通过最小化这个平方误差或距离来拟合模型。例如


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

WebStorm Mac version
Useful JavaScript development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Atom editor mac version download
The most popular open source editor

