

 Technology peripheralsAIPaper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Technology peripheralsAIPaper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.

Generative AI has taken the artificial intelligence community by storm. Both individuals and enterprises have begun to be keen on creating related modal conversion applications, such as Vincent pictures, Vincent videos, Vincent music, etc.
Recently, several researchers from scientific research institutions such as ServiceNow Research and LIVIA have tried to generate charts in papers based on text descriptions. To this end, they proposed a new method of FigGen, and the related paper was also included as a Tiny Paper in ICLR 2023.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2306.00800.pdf
Some people may ask, what is so difficult about generating the charts in the paper? How does this help scientific research?
Scientific research chart generation helps to disseminate research results in a concise and easy-to-understand way, and automatically generating charts can bring many advantages to researchers, such as saving time and energy without spending a lot of money. Take the effort to design a chart from scratch. In addition, designing visually appealing and easy-to-understand figures can make the paper accessible to more people.
However, generating diagrams also faces some challenges. It needs to represent complex relationships between discrete components such as boxes, arrows, and text. Unlike generating natural images, concepts in paper graphs may have different representations and require fine-grained understanding. For example, generating a neural network graph will involve an ill-posed problem with high variance.
Therefore, the researchers in this paper trained a generative model on a dataset of paper diagram pairs to capture the relationship between diagram components and the corresponding text in the paper. This requires dealing with varying lengths and highly technical text descriptions, different chart styles, image aspect ratios, and text rendering fonts, sizes, and orientation issues.
In the specific implementation process, the researchers were inspired by recent text-to-image results, used the diffusion model to generate charts, and proposed a potential diffusion to generate scientific research charts from text descriptions. Model - FigGen.
What are the unique features of this diffusion model? Let's move on to the details.
Models and Methods
The researchers trained a latent diffusion model from scratch.
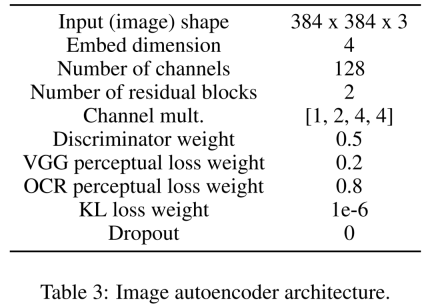
First learn an image autoencoder to map images into compressed latent representations. The image encoder uses KL loss and OCR perceptual loss. The text encoder used for conditioning is learned end-to-end in the training of this diffusion model. Table 3 below shows the detailed parameters of the image autoencoder architecture.
The diffusion model then interacts directly in the latent space, performing data-corrupted forward scheduling while learning to exploit temporal and textual conditional denoising U-Net to recover from the process.
## As for the data set, the researchers used Paper2Fig100k, which consists of graph-text pairs in the paper and contains 81,194 training samples and 21,259 validation samples. Figure 1 below is an example of a diagram generated using text descriptions in the Paper2Fig100k test set.

Model details
First the images Encoder. In the first stage, the image autoencoder learns a mapping from pixel space to a compressed latent representation, making diffusion model training faster. The image encoder also needs to learn to map the latent image back to pixel space without losing important details of the diagram (such as text rendering quality).
To this end, the researchers defined a convolutional codec with a bottleneck that downsamples the image at factor f=8. The encoder is trained to minimize KL loss, VGG-aware loss, and OCR-aware loss with Gaussian distribution.
Second is the text encoder. Researchers have found that general-purpose text encoders are not suitable for graph generation tasks. Therefore they define a Bert transformer trained from scratch in the diffusion process, which uses an embedding channel of size 512, which is also the embedding size that regulates the cross-attention layers of U-Net. The researchers also explored changes in the number of transformer layers under different settings (8, 32, and 128).
Finally, there is the latent diffusion model. Table 2 below shows the network architecture of U-Net. We perform the diffusion process on a perceptually equivalent latent representation of the image, where the input size of the image is compressed to 64x64x4, making the diffusion model faster. They defined 1,000 diffusion steps and linear noise scheduling.

##Training details
To train the image autoencoder, the researchers used an Adam optimizer with an effective batch size of 4 samples and a learning rate of 4.5e−6, during which four 12GB NVIDIA V100 graphics cards were used. To achieve training stability, they warmup the model in 50k iterations without using the discriminator.
For training the latent diffusion model, the researchers also used the Adam optimizer, which has an effective batch size of 32 and a learning rate of 1e−4. When training the model on the Paper2Fig100k dataset, they used eight 80GB NVIDIA A100 graphics cards.
Experimental results
In the generation process, the researcher used a DDIM sampler with 200 steps and generated 12,000 samples to calculate FID, IS, KID and OCR-SIM1. Robust use of classifier-free guidance (CFG) to test hyperconditioning.
Table 1 below shows the results for different text encoders. It can be seen that large text encoders produce the best qualitative results and condition generation can be improved by increasing the size of the CFG. Although the qualitative samples are not of sufficient quality to solve the problem, FigGen has grasped the relationship between text and images.
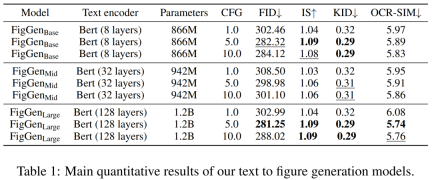
Figure 2 below shows the additional FigGen samples generated when adjusting the Classifier-Free Guidance (CFG) parameters. The researchers observed that increasing the size of the CFG, which was also demonstrated quantitatively, led to improvements in image quality.
 Pictures
Pictures
Figure 3 below shows more generation examples from FigGen. Pay attention to the variation in length between samples, as well as the technical level of the text description, which will closely affect the difficulty of the model to correctly generate understandable images.
 Picture
Picture
However, the researchers also admitted that although these generated charts cannot provide practical help to the authors of the paper, they still It can be regarded as a promising direction of exploration.
For more research details, please refer to the original paper.
The above is the detailed content of Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.. For more information, please follow other related articles on the PHP Chinese website!

 How to Build Your Personal AI Assistant with Huggingface SmolLMApr 18, 2025 am 11:52 AM
How to Build Your Personal AI Assistant with Huggingface SmolLMApr 18, 2025 am 11:52 AMHarness the Power of On-Device AI: Building a Personal Chatbot CLI In the recent past, the concept of a personal AI assistant seemed like science fiction. Imagine Alex, a tech enthusiast, dreaming of a smart, local AI companion—one that doesn't rely
 AI For Mental Health Gets Attentively Analyzed Via Exciting New Initiative At Stanford UniversityApr 18, 2025 am 11:49 AM
AI For Mental Health Gets Attentively Analyzed Via Exciting New Initiative At Stanford UniversityApr 18, 2025 am 11:49 AMTheir inaugural launch of AI4MH took place on April 15, 2025, and luminary Dr. Tom Insel, M.D., famed psychiatrist and neuroscientist, served as the kick-off speaker. Dr. Insel is renowned for his outstanding work in mental health research and techno
 The 2025 WNBA Draft Class Enters A League Growing And Fighting Online HarassmentApr 18, 2025 am 11:44 AM
The 2025 WNBA Draft Class Enters A League Growing And Fighting Online HarassmentApr 18, 2025 am 11:44 AM"We want to ensure that the WNBA remains a space where everyone, players, fans and corporate partners, feel safe, valued and empowered," Engelbert stated, addressing what has become one of women's sports' most damaging challenges. The anno
 Comprehensive Guide to Python Built-in Data Structures - Analytics VidhyaApr 18, 2025 am 11:43 AM
Comprehensive Guide to Python Built-in Data Structures - Analytics VidhyaApr 18, 2025 am 11:43 AMIntroduction Python excels as a programming language, particularly in data science and generative AI. Efficient data manipulation (storage, management, and access) is crucial when dealing with large datasets. We've previously covered numbers and st
 First Impressions From OpenAI's New Models Compared To AlternativesApr 18, 2025 am 11:41 AM
First Impressions From OpenAI's New Models Compared To AlternativesApr 18, 2025 am 11:41 AMBefore diving in, an important caveat: AI performance is non-deterministic and highly use-case specific. In simpler terms, Your Mileage May Vary. Don't take this (or any other) article as the final word—instead, test these models on your own scenario
 AI Portfolio | How to Build a Portfolio for an AI Career?Apr 18, 2025 am 11:40 AM
AI Portfolio | How to Build a Portfolio for an AI Career?Apr 18, 2025 am 11:40 AMBuilding a Standout AI/ML Portfolio: A Guide for Beginners and Professionals Creating a compelling portfolio is crucial for securing roles in artificial intelligence (AI) and machine learning (ML). This guide provides advice for building a portfolio
 What Agentic AI Could Mean For Security OperationsApr 18, 2025 am 11:36 AM
What Agentic AI Could Mean For Security OperationsApr 18, 2025 am 11:36 AMThe result? Burnout, inefficiency, and a widening gap between detection and action. None of this should come as a shock to anyone who works in cybersecurity. The promise of agentic AI has emerged as a potential turning point, though. This new class
 Google Versus OpenAI: The AI Fight For StudentsApr 18, 2025 am 11:31 AM
Google Versus OpenAI: The AI Fight For StudentsApr 18, 2025 am 11:31 AMImmediate Impact versus Long-Term Partnership? Two weeks ago OpenAI stepped forward with a powerful short-term offer, granting U.S. and Canadian college students free access to ChatGPT Plus through the end of May 2025. This tool includes GPT‑4o, an a


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

