

 Technology peripheralsAINo need to label data, '3D understanding' enters the era of multi-modal pre-training! ULIP series is fully open source and refreshes SOTA
Technology peripheralsAINo need to label data, '3D understanding' enters the era of multi-modal pre-training! ULIP series is fully open source and refreshes SOTA
By aligning three-dimensional shapes, two-dimensional pictures and corresponding language descriptions, multi-modal pre-training methods also drive the development of 3D representation learning.
However, the existing multi-modal pre-training frameworkmethods of collecting data lack scalability, which greatly limits the potential of multi-modal learning. Among them, the most The main bottleneck lies in the scalability and comprehensiveness of language modalities.
Recently, Salesforce AI teamed up with Stanford University and the University of Texas at Austin to release the ULIP (CVP R2023) and ULIP-2 projects, which are leading a new chapter in 3D understanding. .

Paper link: https://arxiv.org/pdf/2212.05171.pdf
Paper link: https://arxiv.org/pdf/2305.08275.pdf
##Code link: https: //github.com/salesforce/ULIP
The researchers used a unique approach to pre-train the model using 3D point clouds, images and text, aligning them to A unified feature space. This approach achieves state-of-the-art results in 3D classification tasks and opens up new possibilities for cross-domain tasks such as image-to-3D retrieval.
And ULIP-2 makes this multi-modal pre-training possible without any manual annotation, thus enabling large-scale scalability.
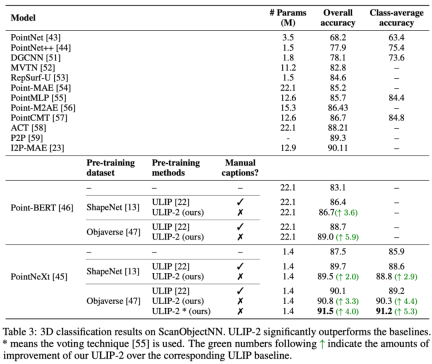
ULIP-2 achieved significant performance improvements in the downstream zero-shot classification of ModelNet40, reaching the highest accuracy of 74.0%; on the real-world ScanObjectNN benchmark, it only used 1.4 million An overall accuracy of 91.5% was achieved with just one parameter, marking a breakthrough in scalable multimodal 3D representation learning without the need for human 3D annotation.
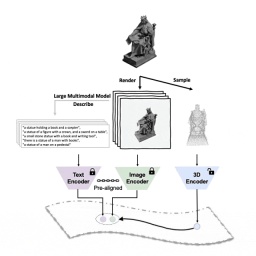
Schematic diagram of the pre-training framework for aligning these three features (3D, image, text)
The code and the released large-scale tri-modal data sets ("ULIP - Objaverse Triplets" and "ULIP - ShapeNet Triplets") have been open source.
Background3D understanding is an important part of the field of artificial intelligence, which allows machines to perceive and interact in three-dimensional space like humans. This capability has important applications in areas such as autonomous vehicles, robotics, virtual reality, and augmented reality.
However, 3D understanding has always faced huge challenges due to the complexity of processing and interpreting 3D data, as well as the cost of collecting and annotating 3D data.
ULIP
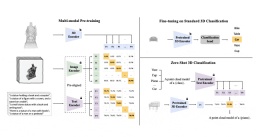
##Tri-modal pre-training framework and its downstream tasks
ULIP (already accepted by CVPR2023) adopts a unique approach to pre-train the model using 3D point clouds, images and text, aligning them into a unified representation space .This approach achieves state-of-the-art results in 3D classification tasks and opens up new possibilities for cross-domain tasks such as image-to-3D retrieval.
The key to the success of ULIP is the use of pre-aligned image and text encoders, such as CLIP, which are pre-trained on a large number of image-text pairs.
These encoders align the features of the three modalities into a unified representation space, enabling the model to understand and classify 3D objects more effectively.
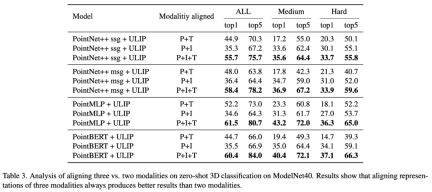
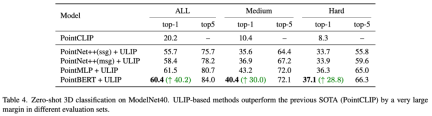
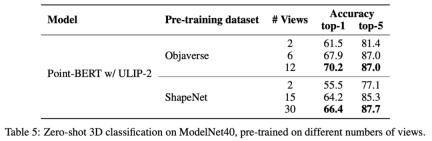
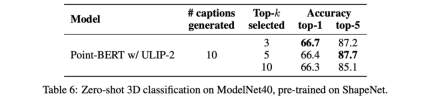
This improved 3D representation learning not only enhances the model’s understanding of 3D data, but also enables cross-modal applications such as zero-shot 3D classification and image-to-3D retrieval because the 3D encoder gains Multimodal context. The pre-training loss function of ULIP is as follows: In the default settings of ULIP, α is is set to 0, β and θ are set to 1, and the contrastive learning loss function between each two modes is defined as follows, where M1 and M2 refer to any two modes among the three modes: ULIP also conducted experiments on retrieval from image to 3D, and the results are as follows: The experimental results show that the ULIP pre-trained model has been able to learn meaningful multi-modal features between images and 3D point clouds. Surprisingly, compared to the other retrieved 3D models, the first retrieved 3D model is closest in appearance to the query image. For example, when we use images from different aircraft types (fighters and airliners) for retrieval (second and third rows), the closest 3D point cloud retrieved is still Subtle differences in query images are preserved. ##Here is a 3D object that generates multi-angle text descriptions Example. We first render 3D objects into 2D images from a set of views, and then use a large multi-modal model to generate descriptions for all generated images ULIP-2 in ULIP Basically, use large-scale multi-modal models to generate all-round corresponding language descriptions for 3D objects, thereby collecting scalable multi-modal pre-training data without any manual annotation, making the pre-training process and the trained model more efficient and enhanced its adaptability. ULIP-2’s method includes generating multi-angle and different language descriptions for each 3D object, and then using these descriptions to train the model, so that 3D objects, 2D images, and language descriptions can be combined Feature space alignment is consistent. This framework enables the creation of large tri-modal datasets without manual annotation, thereby fully utilizing the potential of multi-modal pre-training. ULIP-2 also released the large-scale three-modal data sets generated: "ULIP - Objaverse Triplets" and "ULIP - ShapeNet Triplets". Some statistical data of two tri-modal datasets The ULIP series has achieved amazing results in multi-modal downstream tasks and fine-tuning experiments on 3D expressions. In particular, the pre-training in ULIP-2 can be achieved without any manual annotation. of. ULIP-2 achieved significant improvements (74.0% top-1 accuracy) on the downstream zero-shot classification task of ModelNet40; in the real-world ScanObjectNN benchmark, it achieved An overall accuracy of 91.5% was achieved with only 1.4M parameters, marking a breakthrough in scalable multi-modal 3D representation learning without the need for manual 3D annotation. Both papers conducted detailed ablation experiments. In "ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding", since the pre-training framework of ULIP involves the participation of three modalities, the author used experiments to explore whether it is only Is it better to align two of the modes or to align all three modes? The experimental results are as follows: As can be seen from the experimental results, In different 3D backbones, aligning three modalities is better than aligning only two modalities, which also proves the rationality of ULIP's pre-training framework. In "ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding", the author explores the impact of different large-scale multimodal models on the pre-training framework. The results are as follows: The experimental results can be seen that the effect of ULIP-2 framework pre-training can be upgraded with the use of large-scale multi-modal models. And promotion has a certain degree of growth. In ULIP-2, the author also explored how using different numbers of views to generate the tri-modal data set would affect the overall pre-training performance. The experimental results are as follows: #The experimental results show that as the number of perspectives used increases, the effect of zero-shot classification of the pre-trained model will also increase. This also supports the point in ULIP-2 that a more comprehensive and diverse language description will have a positive effect on multi-modal pre-training. In addition, ULIP-2 also explored the impact of language descriptions of different topk sorted by CLIP on multi-modal pre-training. The experimental results are as follows: The experimental results show that the ULIP-2 framework has a certain degree of robustness to different topk. Top 5 is used as the default setting in the paper. The ULIP project (CVPR2023) and ULIP-2 jointly released by Salesforce AI, Stanford University, and the University of Texas at Austin are changing the field of 3D understanding. ULIP aligns different modalities into a unified space, enhancing 3D feature learning and enabling cross-modal applications. ULIP-2 is further developed to generate a holistic language description for 3D objects, create and open source a large number of three-modal data sets, and this process does not require manual annotation. These projects set new benchmarks in 3D understanding, paving the way for a future where machines truly understand our three-dimensional world. Salesforce AI: Le Xue (Xue Le), Mingfei Gao (Gao Mingfei), Chen Xing (Xingchen), Ning Yu (Yu Ning), Shu Zhang (张捍), Junnan Li (李俊 Nan), Caiming Xiong (Xiong Caiming), Ran Xu (Xu Ran), Juan Carlos niebles, Silvio Savarese. Stanford University: Prof. Silvio Savarese, Prof. Juan Carlos Niebles, Prof. Jiajun Wu(Wu Jiajun). UT Austin: Prof. Roberto Martín-Martín. 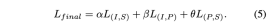

ULIP-2

Conclusion
Team
The above is the detailed content of No need to label data, '3D understanding' enters the era of multi-modal pre-training! ULIP series is fully open source and refreshes SOTA. For more information, please follow other related articles on the PHP Chinese website!

 Why Sam Altman And Others Are Now Using Vibes As A New Gauge For The Latest Progress In AIMay 06, 2025 am 11:12 AM
Why Sam Altman And Others Are Now Using Vibes As A New Gauge For The Latest Progress In AIMay 06, 2025 am 11:12 AMLet's discuss the rising use of "vibes" as an evaluation metric in the AI field. This analysis is part of my ongoing Forbes column on AI advancements, exploring complex aspects of AI development (see link here). Vibes in AI Assessment Tradi
 Inside The Waymo Factory Building A Robotaxi FutureMay 06, 2025 am 11:11 AM
Inside The Waymo Factory Building A Robotaxi FutureMay 06, 2025 am 11:11 AMWaymo's Arizona Factory: Mass-Producing Self-Driving Jaguars and Beyond Located near Phoenix, Arizona, Waymo operates a state-of-the-art facility producing its fleet of autonomous Jaguar I-PACE electric SUVs. This 239,000-square-foot factory, opened
 Inside S&P Global's Data-Driven Transformation With AI At The CoreMay 06, 2025 am 11:10 AM
Inside S&P Global's Data-Driven Transformation With AI At The CoreMay 06, 2025 am 11:10 AMS&P Global's Chief Digital Solutions Officer, Jigar Kocherlakota, discusses the company's AI journey, strategic acquisitions, and future-focused digital transformation. A Transformative Leadership Role and a Future-Ready Team Kocherlakota's role
 The Rise Of Super-Apps: 4 Steps To Flourish In A Digital EcosystemMay 06, 2025 am 11:09 AM
The Rise Of Super-Apps: 4 Steps To Flourish In A Digital EcosystemMay 06, 2025 am 11:09 AMFrom Apps to Ecosystems: Navigating the Digital Landscape The digital revolution extends far beyond social media and AI. We're witnessing the rise of "everything apps"—comprehensive digital ecosystems integrating all aspects of life. Sam A
 Mastercard And Visa Unleash AI Agents To Shop For YouMay 06, 2025 am 11:08 AM
Mastercard And Visa Unleash AI Agents To Shop For YouMay 06, 2025 am 11:08 AMMastercard's Agent Pay: AI-Powered Payments Revolutionize Commerce While Visa's AI-powered transaction capabilities made headlines, Mastercard has unveiled Agent Pay, a more advanced AI-native payment system built on tokenization, trust, and agentic
 Backing The Bold: Future Ventures' Transformative Innovation PlaybookMay 06, 2025 am 11:07 AM
Backing The Bold: Future Ventures' Transformative Innovation PlaybookMay 06, 2025 am 11:07 AMFuture Ventures Fund IV: A $200M Bet on Novel Technologies Future Ventures recently closed its oversubscribed Fund IV, totaling $200 million. This new fund, managed by Steve Jurvetson, Maryanna Saenko, and Nico Enriquez, represents a significant inv
 As AI Use Soars, Companies Shift From SEO To GEOMay 05, 2025 am 11:09 AM
As AI Use Soars, Companies Shift From SEO To GEOMay 05, 2025 am 11:09 AMWith the explosion of AI applications, enterprises are shifting from traditional search engine optimization (SEO) to generative engine optimization (GEO). Google is leading the shift. Its "AI Overview" feature has served over a billion users, providing full answers before users click on the link. [^2] Other participants are also rapidly rising. ChatGPT, Microsoft Copilot and Perplexity are creating a new “answer engine” category that completely bypasses traditional search results. If your business doesn't show up in these AI-generated answers, potential customers may never find you—even if you rank high in traditional search results. From SEO to GEO – What exactly does this mean? For decades
 Big Bets On Which Of These Pathways Will Push Today's AI To Become Prized AGIMay 05, 2025 am 11:08 AM
Big Bets On Which Of These Pathways Will Push Today's AI To Become Prized AGIMay 05, 2025 am 11:08 AMLet's explore the potential paths to Artificial General Intelligence (AGI). This analysis is part of my ongoing Forbes column on AI advancements, delving into the complexities of achieving AGI and Artificial Superintelligence (ASI). (See related art


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Dreamweaver CS6
Visual web development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

