


Django is a popular Python web framework. Its efficiency and scalability are one of the reasons for its popularity. In applications, sometimes complex data interactions and consistency between multiple requests need to be handled. At this time, you need to use transaction processing techniques in Django to ensure data integrity and consistency.
In Django, there are two ways of transaction processing: function-based transaction processing and context manager-based transaction processing. This article will provide a detailed analysis of these two techniques.
1. Function-based transaction processing
Django provides the decorator transaction.atomic() to implement function-based transaction processing. This decorator can be used on view functions (views) and management commands (management commands).
Use this decorator in a view function. When the view function returns an HTTP response code of HTTP 500 (server error), Django will roll back all operations written to the database.
For example, the following is a view function used to process data passed in from the front end and needs to update multiple tables at the same time:
@transaction.atomic
def my_view(request):
# 处理从前端传入的数据
# ...
# 更新表1
# ...
# 更新表2
# ...In the above code, when an exception occurs, All write operations to the database will be automatically revoked to ensure data integrity and consistency. At the same time, the decorator also supports multiple nested transactions. When a nested transaction fails, only the database operated by the nested transaction will be rolled back, but not all transactions.
2. Transaction processing based on context manager
In Django 1.8, transaction processing based on context manager was introduced. This technique supports nested transactions and consistency issues between databases.
The following is an example of using the with statement:
from django.db import transaction
def my_view(request):
with transaction.atomic():
# 处理请求
# ...
# 更新表1
# ...
# 更新表2
# ...In the above code, the transaction will be automatically committed or rolled back. The effect is consistent with using transaction.atomic().
In addition, if you need to manually start a transaction and monitor possible error messages, you can use transaction.set_autocommit(False):
from django.db import connection, transaction
def my_view(request):
connection.set_autocommit(False)
try:
# 处理请求
# ...
# 更新表1
# ...
# 更新表2
# ...
connection.commit()
except:
connection.rollback()
finally:
connection.set_autocommit(True)The above is a method to manually control a transaction in a function, code More lengthy. If you need to reuse it, you can encapsulate this method into a separate class.
3. Notes
When using transaction processing in Django, you need to pay attention to the following points:
1. Django will automatically submit database modification operations by default. This The transaction will not be executed at this time. Set_autocommit(False) needs to be set to disable automatic commit.
2. If you need to handle deadlocks or other exceptions, you need to use an exception handling mechanism to avoid data damage.
3. When using transactions in management commands, you need to pay attention to the transaction submission time. Because commands can be long-running, long-running transactions can take up too many database resources, causing the entire database to slow down. In this case, third-party packages like django-extensions can be used to optimize long-running transactions.
In short, using transaction processing techniques in Django can ensure the integrity and consistency of data and reduce data damage caused by unexpected operations. At the same time, understanding Django's transaction processing skills can also help developers better optimize code and improve application operating efficiency.
The above is the detailed content of Transaction processing skills in Django framework. For more information, please follow other related articles on the PHP Chinese website!

 提高 Python 代码可读性的五个基本技巧Apr 12, 2023 pm 08:58 PM
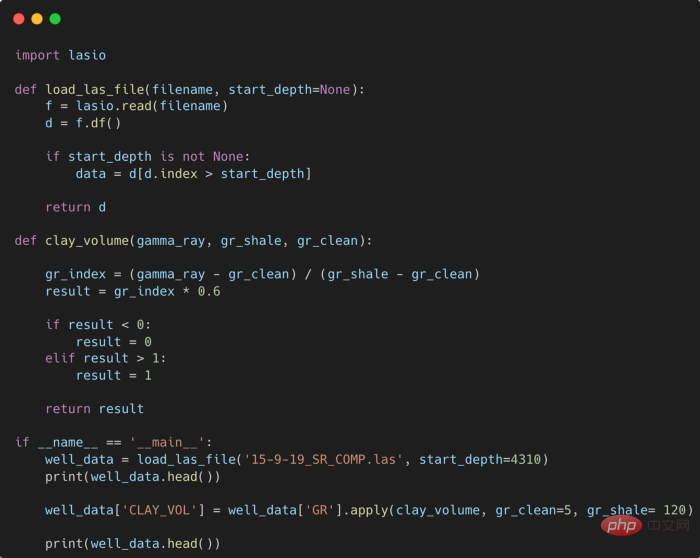
提高 Python 代码可读性的五个基本技巧Apr 12, 2023 pm 08:58 PMPython 中有许多方法可以帮助我们理解代码的内部工作原理,良好的编程习惯,可以使我们的工作事半功倍!例如,我们最终可能会得到看起来很像下图中的代码。虽然不是最糟糕的,但是,我们需要扩展一些事情,例如:load_las_file 函数中的 f 和 d 代表什么?为什么我们要在 clay 函数中检查结果?这些函数需要什么类型?Floats? DataFrames?在本文中,我们将着重讨论如何通过文档、提示输入和正确的变量名称来提高应用程序/脚本的可读性的五个基本技巧。1. Comments我们可
 使用PHP开发直播功能的十个技巧May 21, 2023 pm 11:40 PM
使用PHP开发直播功能的十个技巧May 21, 2023 pm 11:40 PM随着直播业务的火爆,越来越多的网站和应用开始加入直播这项功能。PHP作为一种流行的服务器端语言,也可以用来开发高效的直播功能。当然,要实现一个稳定、高效的直播功能需要考虑很多问题。下面列出了使用PHP开发直播功能的十个技巧,帮助你更好地实现直播。选择合适的流媒体服务器PHP开发直播功能,首先需要考虑的就是流媒体服务器的选择。有很多流媒体服务器可以选择,比如常
 提高Python代码可读性的五个基本技巧Apr 11, 2023 pm 09:07 PM
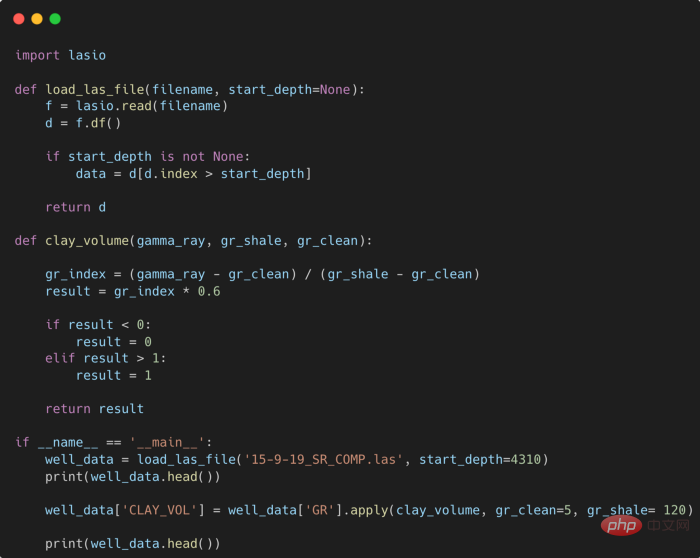
提高Python代码可读性的五个基本技巧Apr 11, 2023 pm 09:07 PM译者 | 赵青窕审校 | 孙淑娟你是否经常回头看看6个月前写的代码,想知道这段代码底是怎么回事?或者从别人手上接手项目,并且不知道从哪里开始?这样的情况对开发者来说是比较常见的。Python中有许多方法可以帮助我们理解代码的内部工作方式,因此当您从头来看代码或者写代码时,应该会更容易地从停止的地方继续下去。在此我给大家举个例子,我们可能会得到如下图所示的代码。这还不是最糟糕的,但有一些事情需要我们去确认,例如:在load_las_file函数中f和d代表什么?为什么我们要在clay函数中检查结果
 PHP中的多表关联查询技巧May 24, 2023 am 10:01 AM
PHP中的多表关联查询技巧May 24, 2023 am 10:01 AMPHP中的多表关联查询技巧关联查询是数据库查询的重要部分,特别是当你需要展示多个相关数据库表内的数据时。在PHP应用程序中,在使用MySQL等数据库时,多表关联查询经常会用到。多表关联的含义是,将一个表中的数据与另一个或多个表中的数据进行比较,在结果中将那些满足要求的行连接起来。在进行多表关联查询时,需要考虑表之间的关系,并使用合适的关联方法。下面介绍几种多
 Python中简单易用的并行加速技巧Apr 12, 2023 pm 02:25 PM
Python中简单易用的并行加速技巧Apr 12, 2023 pm 02:25 PM1.简介我们在日常使用Python进行各种数据计算处理任务时,若想要获得明显的计算加速效果,最简单明了的方式就是想办法将默认运行在单个进程上的任务,扩展到使用多进程或多线程的方式执行。而对于我们这些从事数据分析工作的人员而言,以最简单的方式实现等价的加速运算的效果尤为重要,从而避免将时间过多花费在编写程序上。而今天的文章费老师我就来带大家学习如何利用joblib这个非常简单易用的库中的相关功能,来快速实现并行计算加速效果。2.使用joblib进行并行计算作为一个被广泛使用的第三方Python库(
 Go语言中的网络爬虫开发技巧Jun 02, 2023 am 09:21 AM
Go语言中的网络爬虫开发技巧Jun 02, 2023 am 09:21 AM近年来,随着网络信息的急剧增长,网络爬虫技术在互联网行业中扮演着越来越重要的角色。其中,Go语言的出现为网络爬虫的开发带来了诸多优势,如高速度、高并发、低内存占用等。本文将介绍一些Go语言中的网络爬虫开发技巧,帮助开发者更快更好地进行网络爬虫项目开发。一、如何选择合适的HTTP客户端在Go语言中,有多种HTTP请求库可供选择,如net/http、GoRequ
 四种Python推导式开发技巧,让你的代码更高效Apr 22, 2023 am 09:40 AM
四种Python推导式开发技巧,让你的代码更高效Apr 22, 2023 am 09:40 AM对于数据科学,Python通常被广泛地用于进行数据的处理和转换,它提供了强大的数据结构处理的函数,使数据处理更加灵活,这里说的“灵活性”是什么意思?这意味着在Python中总是有多种方法来实现相同的结果,我们总是有不同的方法并且需要从中选择易于使用、省时并能更好控制的方法。要掌握所有的这些方法是不可能的。所以这里列出了在处理任何类型的数据时应该知道的4个Python技巧。列表推导式ListComprehension是创建列表的一种优雅且最符合python语言的方法。与for循环和if语句相比,列
 使用一个神器的指令,能迅速让你的GPT拥有智慧!May 09, 2023 am 08:13 AM
使用一个神器的指令,能迅速让你的GPT拥有智慧!May 09, 2023 am 08:13 AM今天给大家分享二个小技巧,第一个可以增加输出的逻辑,让框架逻辑变的更加清晰。先来看看正常情况下GPT的输出,以用户增长分析体系为例:下来我给加一个简单的指令,我们再对比看看效果:是不是效果更好一些?而且逻辑很清晰,当然上面的输出其实不止这些,只是为了举例而已。我们直接让GPT扮演一个资深的Python工程师,帮我写个学习计划吧!提问的时候只需后面加以下这句话即可!let'sthinkstepbystep接下来再看看第二个实用的指令,可以让你的文章更上一个台阶,比如我们让GPT写一个述职报告,这里


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

